pandas:apply和transform方法的性能比较
1. apply与transform
首先讲一下apply() 与transform()的相同点与不同点
相同点:
都能针对dataframe完成特征的计算,并且常常与groupby()方法一起使用。
不同点:
apply()里面可以跟自定义的函数,包括简单的求和函数以及复杂的特征间的差值函数等(注:apply不能直接使用agg()方法 / transform()中的python内置函数,例如sum、max、min、’count‘等方法)
transform() 里面不能跟自定义的特征交互函数,因为transform是真针对每一元素(即每一列特征操作)进行计算,也就是说在使用 transform() 方法时,需要记得三点:
1、它只能对每一列进行计算,所以在groupby()之后,.transform()之前是要指定要操作的列,这点也与apply有很大的不同。
2、由于是只能对每一列计算,所以方法的通用性相比apply()就局限了很多,例如只能求列的最大/最小/均值/方差/分箱等操作
3、transform还有什么用呢?最简单的情况是试图将函数的结果分配回原始的dataframe。也就是说返回的shape是(len(df),1)。注:如果与groupby()方法联合使用,需要对值进行去重
2. 各方法耗时
分别计算在同样简单需求下各组合方法的计算时长
2.1 transform() 方法+自定义函数

2.2 transform() 方法+python内置方法

2.3 apply() 方法+自定义函数

2.4 agg() 方法+自定义函数

2.5 agg() 方法+python内置方法
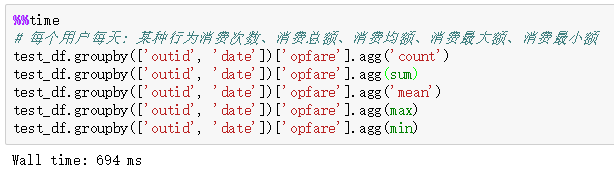
2.6 结论
- agg()+python内置方法的计算速度最快,其次是transform()+python内置方法。而 transform() 方法+自定义函数 的组合方法最慢,需要避免使用!
- 而下面两图中红框内容可观察发现:python自带的stats统计模块在pandas结构中的计算也非常慢,也需要避免使用!


3. 实例分析
需求:计算每个用户每天
某种行为消费次数、消费总额、消费均额、消费最大额、消费最小额
在几个终端支付、最常支付终端号、最常支付终端号的支付次数、最少支付终端号、最少支付终端号的支付次数
某种行为最常消费发生时间段、最常消费发生时间段的消费次数、最少消费发生时间段、最少消费发生时间段的消费次数
某种行为最早消费时间、最晚消费时间
原始数据信息:306626 x 9

具体选择哪种方法处理,根据实际情况确定,在面对复杂计算时,transform() 与apply()结合使用往往会有意想不到的效果!
需要注意的是,在与apply()一起使用时,transform需要进行去重操作,一般是通过指定一或多个列完成。
此外,匿名函数永远不是一个很好的办法,在进行简单计算时,无论是使用transfrom、agg还是apply,都要尽可能使用自带方法!!!
4. 小技巧
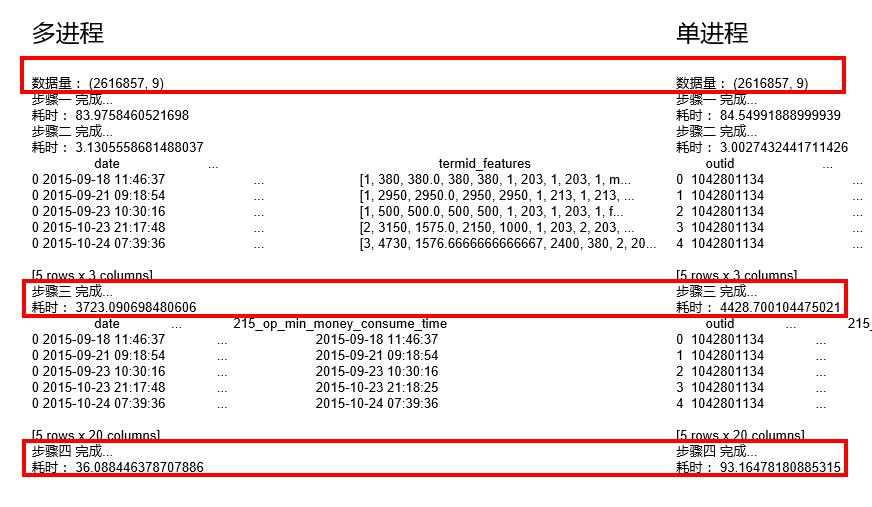
在使用apply()方法处理大数据级时,可以考虑使用joblib中的多线程/多进程模块构造相应函数执行计算,以下分别是采用多进程和单进程的耗时时长。
可以看到,在260W的数据集上,多进程比单进程的计算速度可以提升约17%~61% 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号