Toward fast and accurate human pose estimation via soft-gated skip connections
目录
Toward fast and accurate human pose estimation via soft-gated skip connections
一. 论文简介
设计小的block和feature map的融合方式,提人体姿态估计高计算效率和精度
主要做的贡献如下(可能之前有人已提出):
- block部分使用soft-gate
- feature融合对比,选择最佳方式
二. 模块详解
2.1 Soft-Gate模块
- 简单的说明就是下图展示所示,给每个channel加上了attention机制,这种做法其实SE已经完成了,就是中间的步骤有点小区别而已
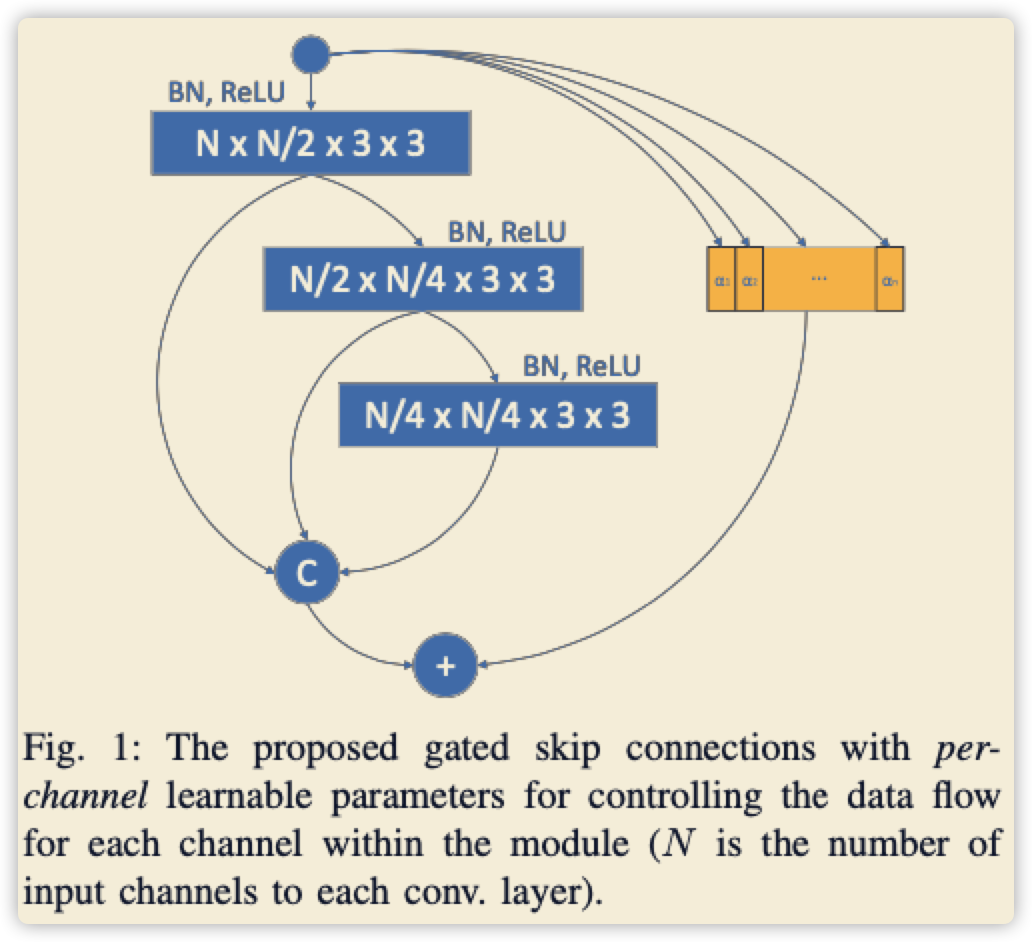
- 以下结合SE的权重,给出参考代码,未尝试运行,整体思路是这样
#FIXME This code is demo for paper, maybe cant run directly, please modify some bug when you use.
class ConvBNReLU(nn.Sequential):
'''
#FIXME Only for 3*3 and 1*1 convolution by dilation equal 1 or 2
'''
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1, dilation=1, norm_layer=None):
padding = (kernel_size - 1) // 2
if dilation==2 and kernel_size==3 and stride==1:
padding=2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding=padding, groups=groups, dilation=dilation, bias=False),
norm_layer(out_planes),
nn.ReLU6(inplace=True)
)
class SoftGateBlock(nn.Module):
def __init__(self, inp, gate=SqueezeExcite):
super(SoftGateBlock, self).__init__()
assert inp%4 == 0
self.layers = self.build_layer(inp, gate)
def forward(self, x):
alpha = self.layers[0](x)
branch_y1 = self.layers[1](x)
branch_y2 = self.layers[1](branch_y1)
branch_y3 = self.layers[1](branch_y2)
branch = torch.cat([branch_y1,branch_y2,branch_y3],dim=1)
y = alpha + branch #TODO please add dimension (torch.unsqueeze) to align dim if error
return y
def build_layer(self, chs, gate):
layers = []
layers.append(gate(chs))
for i in range(3):
layers.append(ConvBNReLU(chs, chs/2))
chs = chs/2
return nn.ModuleList(layers)
# SE module that attetion mode
class SqueezeExcite(nn.Module):
def __init__(self, in_chs, se_ratio=0.25, reduced_base_chs=None,
act_layer=nn.ReLU, gate_fn=hard_sigmoid, divisor=4, **_):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x = x * self.gate_fn(x_se)
return x
论文给的细节不完整,比如:
- 如何得到获得这个权重 \(\alpha\) ?方法有很多,让复现的人一个一个尝试?
- 这里demo以SE模块为例子
- 这里的block只给出了channel不变情况,那下采样和上采样的操作呢?
- 要么使用resnet原来block,要么自己设计。建议参考论文自己设计,因为目的是提升精度,使用前者没意义
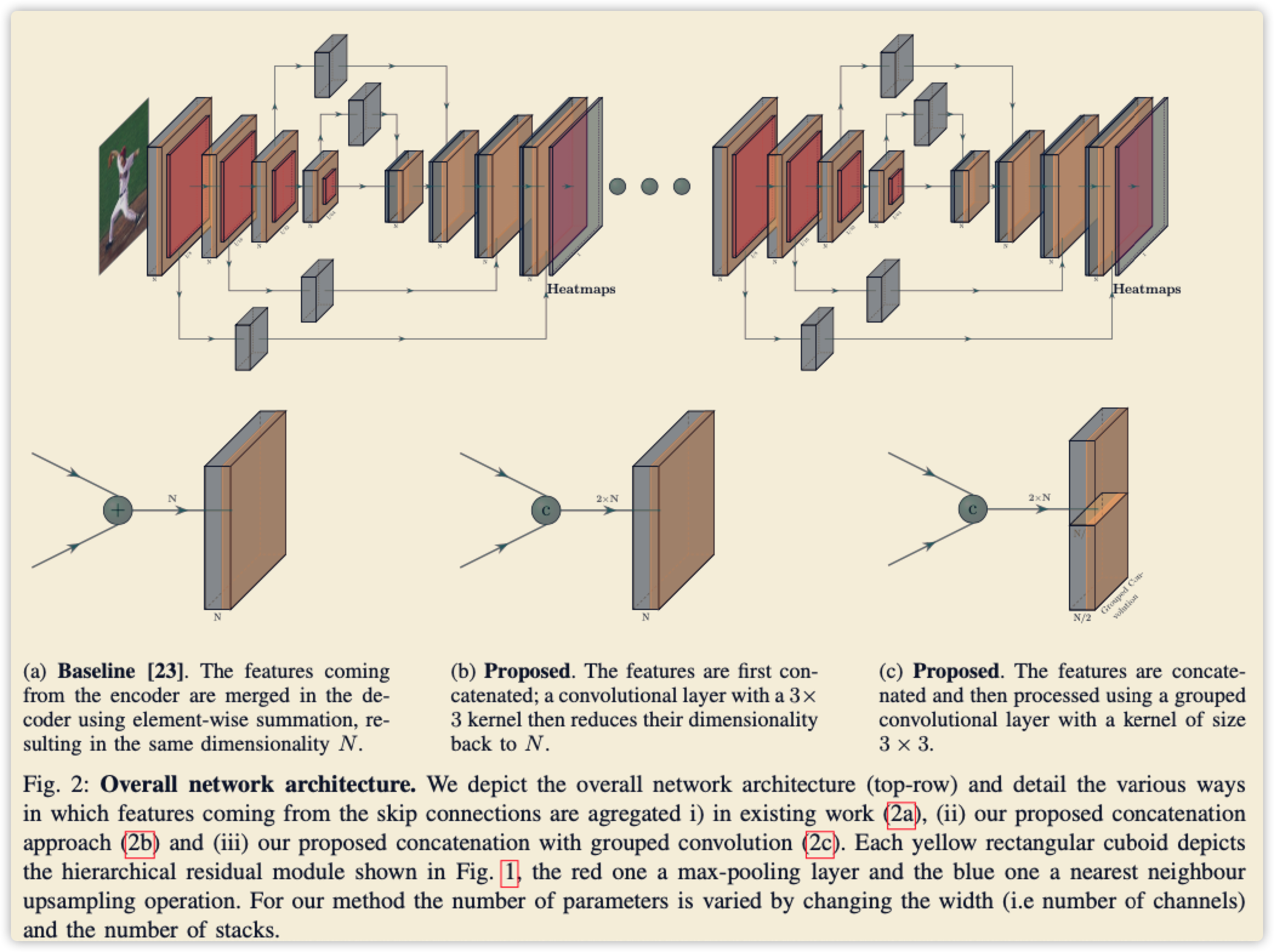
2.2 Feature融合
- 这部分很简单,就是对比几个连接操作,最后选择下图 \((b)\) 的内容,至于为什么?文中给了对比效果表格。
作者:影醉阏轩窗
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号