

为什么重写equals还要重写hashcode?(转载)
为什么?
是为了提高效率,采取重写hashcode方法,先进行hashcode比较,如果不同,那么就没必要在进行equals的比较了,这样就大大减少了equals比较的次数,这对比需要比较的数量很大的效率提高是很明显的,一个很好的例子就是在集合中的使用;
我们都知道java中的List集合是有序的,因此是可以重复的,而set集合是无序的,因此是不能重复的,那么怎么能保证不能被放入重复的元素呢,但靠equals方法一样比较的话,如果原来集合中以后又10000个元素了,那么放入10001个元素,难道要将前面的所有元素都进行比较,看看是否有重复,欧码噶的,这个效率可想而知,因此hashcode就应遇而生了,java就采用了hash表,利用哈希算法(也叫散列算法),就是将对象数据根据该对象的特征使用特定的算法将其定义到一个地址上,那么在后面定义进来的数据只要看对应的hashcode地址上是否有值,那么就用equals比较,如果没有则直接插入,只要就大大减少了equals的使用次数,执行效率就大大提高了。
同事也是为了保证同一个对象,保证在equals相同的情况下hashcode值必定相同,如果重写了equals而未重写hashcode方法,可能就会出现两个没有关系的对象equals相同的(因为equal都是根据对象的特征进行重写的),但hashcode确实不相同的。
总结来说就是两点
1.使用hashcode方法提前校验,可以避免每一次比对都调用equals方法,提高效率
2.保证是同一个对象,如果重写了equals方法,而没有重写hashcode方法,会出现equals相等的对象,hashcode不相等的情况,重写hashcode方法就是为了避免这种情况的出现。
只是用文字来表示太空洞,我们直接上代码,
创建一个Personsa类
-
public class Personsa {
-
private String name;
-
public int age;
-
-
public Personsa(String name, int age) {
-
super();
-
this.name = name;
-
this.age = age;
-
}
-
-
public String getName() {
-
return name;
-
}
-
-
public void setName(String name) {
-
this.name = name;
-
}
-
-
public int getAge() {
-
return age;
-
}
-
-
public void setAge(int age) {
-
this.age = age;
-
}
-
}
然后写个测试类
-
import java.util.HashSet;
-
import java.util.Set;
-
-
public class HashCodeTest {
-
public static void main(String[] args) {
-
Personsa person1 = new Personsa("wulinfei",1);
-
Personsa person2 = new Personsa("wulinfei",1);
-
System.out.println("stu:" + person1.equals(person2));
-
Set<Personsa> set = new HashSet<>();
-
set.add(person1);
-
System.out.println("s1 hashCode:" + person1.hashCode());
-
System.out.println("add s1 size:" + set.size());
-
set.add(person2);
-
System.out.println("s2 hashCode:" + person2.hashCode());
-
System.out.println("add s2 size::" + set.size());
-
}
-
}
运行测试类,可以看出来,两个对象是不相同,所以返回false
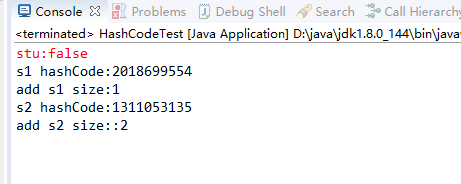
然后我们在重写Personsa类中重写equals方法,这个时候就是只需要name属性相同,equals方法就会返回true

重写equals方法之后,我们修改下age属性

然后运行测试类

然后我们把equals方法去掉,只重写hashcode方法,运行结果:hashcode值一样,但是返回值是false。

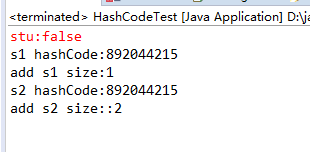
然后我们在同时重写hashcode和equals方法,可以看到返回值是true,同时,hashcode值也是相等的。

结合上面引用的案例,可以类推,hash类存储结构(HashSet、HashMap等等)添加元素会有重复性校验,校验的方式就是先取hashCode判断是否相等(找到对应的位置,该位置可能存在多个元素),然后再取equals方法比较(极大缩小比较范围,高效判断),最终判定该存储结构中是否有重复元素。
小总结:
- hashCode主要用于提升查询效率,来确定在散列结构中对象的存储地址;
- 重写equals()必须重写hashCode(),二者参与计算的自身属性字段应该相同;
- hash类型的存储结构,添加元素重复性校验的标准就是先取hashCode值,后判断equals();
- equals()相等的两个对象,hashcode()一定相等;
- 反过来:hashcode()不等,一定能推出equals()也不等;
- hashcode()相等,equals()可能相等,也可能不等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号