Python大数据分析——豆瓣读书数据分析
一、选题背景
豆瓣的发起者发现,对多数人做选择最有效的帮助其实来自亲友和同事。随意的一两句推荐,不但传递了他们自己真实的感受,也包含了对你口味的判断和随之而行的筛选。他们不会向单身汉推荐育儿大全,也不会给老妈带回赤裸特工。遗憾的是,你我所有的亲友加起来,听过看过的仍然有限。而且,口味最类似的人却往往是陌路。如果能不一一结交,却知道成千上万人的口味,能从中间迅速找到最臭味相投的,口口相传的魔力一定能放大百倍,对其中每一个人都多少会有帮助。豆瓣随着这一个愿望产生。豆瓣不针对任何特定的人群,力图包纳百味。无论高矮胖瘦,白雪巴人,豆瓣帮助你通过你喜爱的东西找到志同道合者,然后通过他们找到更多的好东西。
1.基础设置(导入模块、格式设置、数据整理预览)
2.数据清洗(查重、缺失值、异常值)
3.数据整体情况分析
4.数据分析工 a.有哪些评分和作品数量都很高的作者b.书籍的评分和评论数量之间是否存在相关性c.哪些书籍值得推荐
三、数据分析步骤
基础设置
导入数据源
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 6 7 data = pd.read_csv(\book_douban.csv',header=0) #文件地址根据自己保存位置调整
调整格式
1 pd.set_option('expand_frame_repr', False) # 当列太多时显示不清楚 2 pd.set_option('display.unicode.east_asian_width', True) # 设置输出右对齐
查看列名,观察是否有文件隐藏列或未命名列
通过返回的信息发现最后一列为未命名列,并查看源文件发现为无用的数据信息,选择直接删除该列,并重新查看数据分布
1 print(data.columns) 2 data = data.iloc[:,:-1] 3 print(data.info())

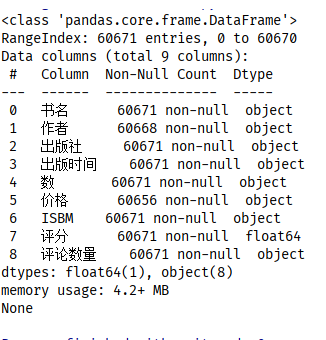
可知,该数据源文件的数据结构为60671行9列
部分特征存在丢失,其中“作者”列丢失3个,“价格”列丢失15个
除评分为浮点数数据类型外,其余皆为对象类型,既“出版时间”和“数”、‘ISBM’列存在格式错误的信息
数据清洗
先观察每个数据特征的情况,再逐一处理
1 def distribution(column): 2 x = data[column].value_counts().head(3).index 3 y = data[column].value_counts().head(3).values 4 df1 = pd.DataFrame(y,index=x).transpose() # 行列转置 5 6 sns.barplot(data=df1) 7 plt.title('图%d:%s'%(i+1,column)) # 设置标题 8 plt.subplots_adjust(wspace=0.5,hspace=0.5) # 设置图形间隔 9 10 11 for i in range(9): 12 plt.subplot(3,3,i+1) 13 distribution(data.columns[i]) 14 15 plt.show()
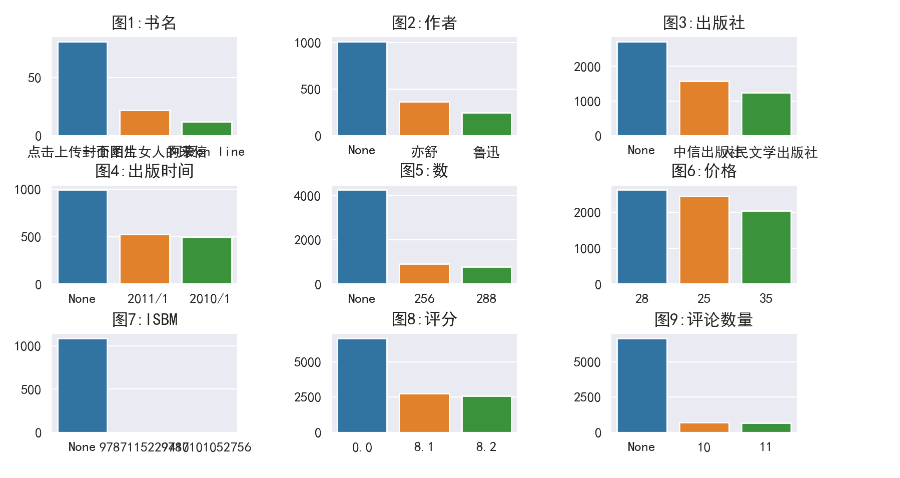
图1,“点击上传封面图片”数量最多且为错误字段,以删除该行信息的方式处理
图2,存在3个空值,以删除该行信息的方式处理
图2、3、6、7、8,缺失值显示为“None”字符串,也以删除该行信息的方式处理
图4,存在多种时间格式且错乱字符串,本文仅为提供分析思路,因此对源数据进行更改,以“2001年至2010年”时段内重新随机抽取一日期进行替换
图5,缺失页数的信息统一默认删除处理
图6,数据显示的价格单位不一,为方便统计全部去除价格符号并默认以人民币计算
图8,0.0为正常数据范围,不作处理
图9,“None”值为正常数据范围,但上文中显示‘评论数量’列的数据类型为object,既存在格式错误,将数据类型不为数值的数据改为0
针对观察提出的问题,逐一对各特征进行数据清洗时,发现存在未记录的问题
‘书名’字段实际存在ISBM值为‘9787508652825’,书名显示错误的书籍(通过excel发现),但因数量只有一个,且确实存在以日期格式命名的书籍,这里就不做批量(条件筛选)和单独处理了
‘出版社’字段,存在同一家出版社但多种字符描述的现象,同时,也存在非出版社名称的字符串,因没有出版社详细清单,难以筛选和重命名,默认皆为不同出版社处理
‘数’和‘价格’字段,存在‘None’字符串的同时也存在非数字描述的字符串,以筛选是否可转换为数值作为判断,进行区分删除
data_clear_1 = data.drop(data[data['书名'] == '点击上传封面图片'].index) # 清洗错乱的书名
data_clear_2 = data_clear_1.dropna(subset=['作者']) # 清除含有空值的信息
1 drop_col_list = ['作者', '出版社', '价格', 'ISBM', '数'] # 清除带有"None"字符串的信息 2 for i in drop_col_list: 3 data_clear_2 = data_clear_2.drop(data_clear_2.loc[data_clear_2[i] == 'None'].index).reset_index(drop=True)
1 date_list = pd.date_range('1/1/2001', '12/31/2010') # 重新配置时间并调整时间格式 2 for j in range(len(data_clear_2)): 3 data_clear_2.iloc[j, 3] = random.choice(date_list)
data_clear_2.replace('None', 0, inplace=True)
data_clear_2['评论数量'] = data_clear_2['评论数量'].astype('int') # 转换为数值类型
1 # 筛选无法转换为数值的字符串进行删除 2 data_clear_2['数'] = data_clear_2['数'].apply(pd.to_numeric, errors='coerce').fillna(0.0).astype('int') 3 data_clear_2 = data_clear_2.drop(data_clear_2.loc[data_clear_2['数'] == 0].index).reset_index(drop=True) 4 5 str_list = [] 6 for i in range(len(data_clear_2['价格'])): 7 if pd.to_numeric(data_clear_2.iloc[i, 5], errors='ignore'): # 判断转换是否可以转换为数值类型 8 data_clear_2.iloc[i, 5] = pd.to_numeric(data_clear_2.iloc[i, 5], errors='ignore') # 保留可转换的字符串 9 else: 10 str_list.append(i) # 不可转换的字符串行索引列表 11 12 data_clear_3 = data_clear_2.drop(str_list).reset_index(drop=True) #删除后,重置索引 13 data_clear_3 = data_clear_3.iloc[1:] # 特殊字符串 14 data_clear_3['价格'] = data_clear_3['价格'].apply(pd.to_numeric, errors='coerce').fillna(0.0).astype('float')
data_clear_3['出版时间'] = pd.to_datetime(data_clear_3['出版时间']).dt.floor('d')
1 print(data_clear_3.info()) 2 print('-' * 100) 3 print(data_clear_3.describe())
数据整体情况分析
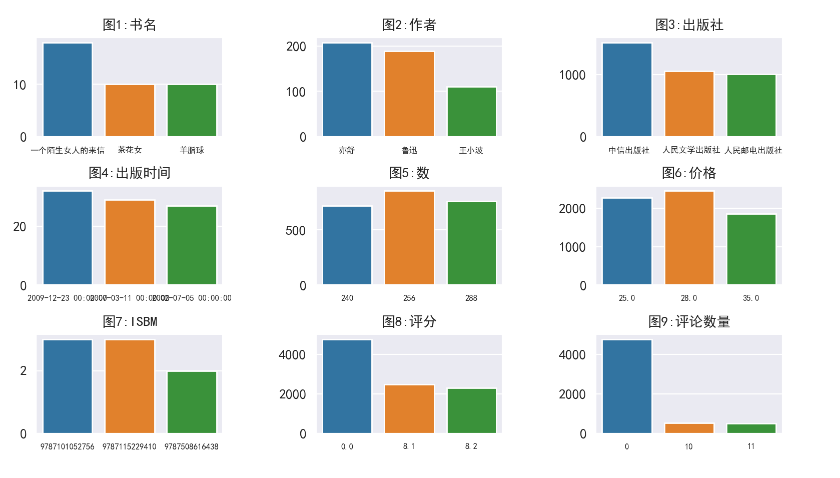
经以上问题处理后,数据明细如下

数据量由60671缩减到51770,共删除8901行数据
参与分类计算的‘出版时间’、‘数’、‘价格’、‘评论数量’均转换为整数或浮点数的数据类型
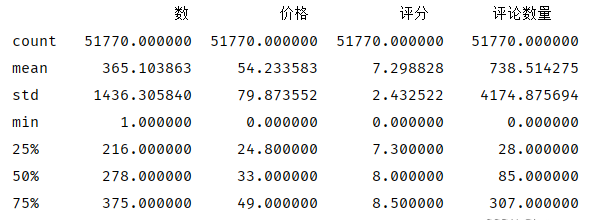
但仔细观察极值,结合主观常识判断,数据仍存在‘错误’的现象,后续将各个数据特征进行分类可视化,观察是否存在异常值
书名
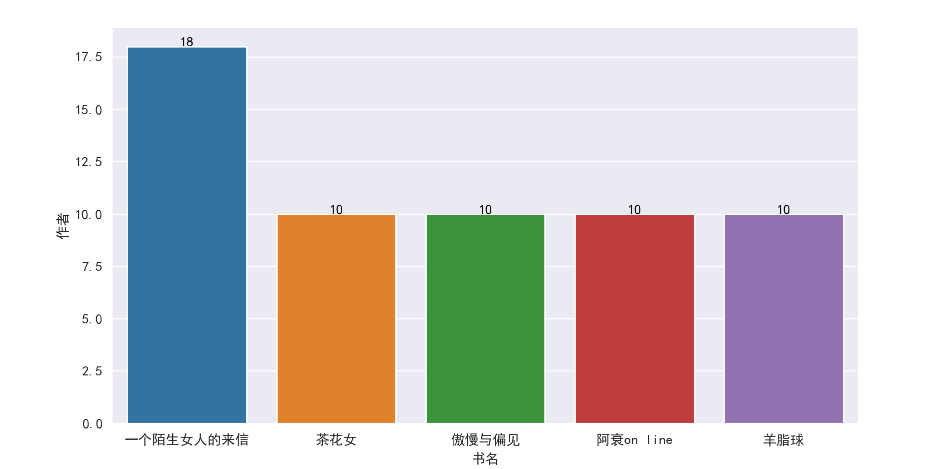
首先为‘书名’列,以‘书名’列为分类并统计‘作者’数量,从上图可知,同一书名存在多个作者或同作者多列信息
1 data_col_1_bar = data_clear_3.groupby('书名').agg({'作者':'count'}).sort_values(by='作者',ascending=False).head().reset_index() 2 g = sns.barplot(x='书名',y='作者',data=data_col_1_bar) 3 for i,row in data_col_1_bar.iterrows(): 4 g.text(row.name,row.作者,row.作者,ha='center',c='black')
筛选数量最多的前5个书单的作者,观察发现皆为同一作者,仅字符表达方式不一
1 data_col_1_name_max = data_clear_3[data_clear_3['书名'].isin(data_col_1_bar['书名'].values)].sort_values(by='书名').reset_index(drop=True).iloc[:,:2] 2 print(data_col_1_name_max)
但由于实际情况存在两本书相同的名字,以‘书名’作为分类统计并无实际意义
作者
若直接统计作者数量,也会因为‘书名’的问题导致部分数据偏高
为避免该类情况,以‘书名’作为唯一字段,删除重复数据,保留第一行数据
注:该处理方式会将同名书籍也一并删除,因此分析将以‘无同名书籍’作为假设条件
1 data_drop_dup_bookname = data_clear_3.drop_duplicates(subset='书名', keep='first').reset_index(drop=True) # 删除重复书名 2 3 print(data_drop_dup_bookname.nunique())
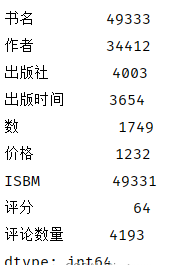
查看删除重复书名后,统计各字段非重复数据
观察上图数据,‘书名’有49333行数据,但‘作者’仅有34412行数据;由此可知,数据源中有部分书籍为同一作者
按作者分类,统计前5个作者发行的书籍,再将前5个作者的最高评分书籍列出
1 data_author = data_drop_dup_bookname.groupby('作者').agg({'书名': 'count'})\ 2 .sort_values('书名',ascending=False).head(5).reset_index() # 按作者分类,统计总数 3 g2 = sns.barplot(x='作者', y='书名', data=data_col_2_bar) 4 for i, row in data_col_2_bar.iterrows(): 5 g2.text(row.name, row.书名, row.书名, ha='center', c='black')
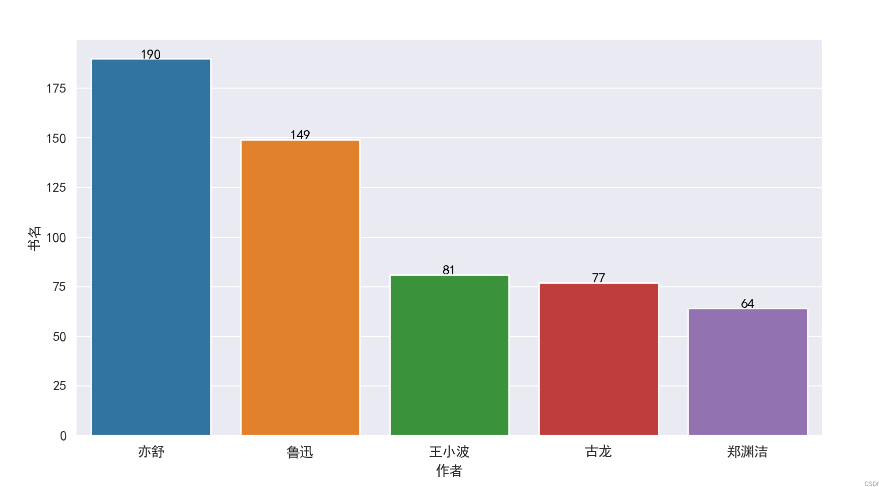
书籍数量最多的作者为‘亦舒’,其次为‘鲁迅’、‘王小波’、‘古龙’、‘郑渊洁’
1 print(data_col_2[data_col_2['作者']== '亦舒'].sort_values(by='评分',ascending=False).head().reset_index(drop=True)) 2 print('-'*100) 3 print(data_col_2[data_col_2['作者'] == '鲁迅'].sort_values(by='评分',ascending=False).head().reset_index(drop=True))
而在‘亦舒’的书籍中,评分最高的为《紅樓夢裏人》,评分8.6分
‘鲁迅’评分最高的为《鲁迅全集》,评分9.5分
出版社
同样以‘无同名书籍’作为假设条件,按出版社数量,分类统计前5个出版社发行的书籍
1 data_publisher = data_drop_dup_bookname.groupby('出版社').agg({'书名': 'count'})\ 2 .sort_values('书名',ascending=False).head().reset_index() # 按出版社分类,统计总数 3 print(data_publisher) 4 g3 = sns.barplot(x='出版社', y='书名', data=data_publisher) 5 for i, row in data_publisher.iterrows(): 6 g3.text(row.name, row.书名, row.书名, ha='center', c='black')
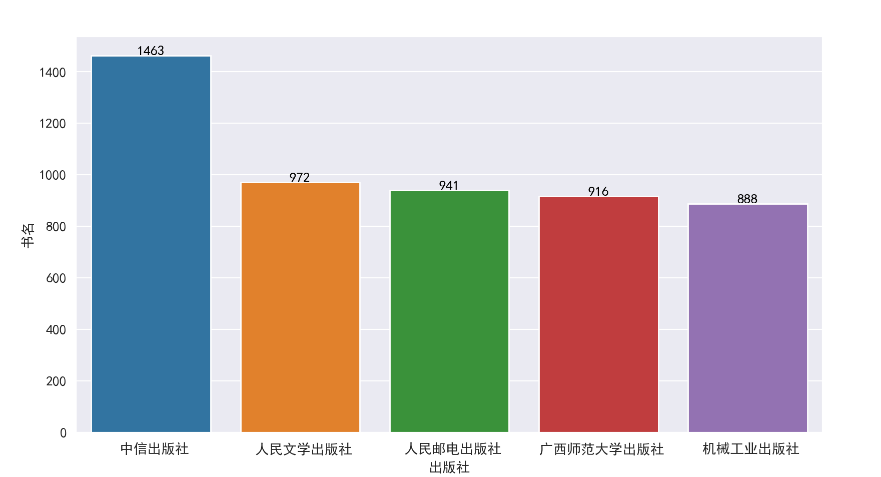
发行出版社最高为‘中信出版社’,共发行1463本书籍,其中《行动的勇气》评分高达9.9分,而
《货币战争》有37909条评论数量,是该出版社讨论最多的书籍
其次发行最高的为‘人民文学出版社’,共发行972本书记,《戚蓼生序本石头记》评分10分,《围城》有178288条评论数量,是该出版社讨论最多的书籍
1 for i in data_publisher['出版社']: 2 print(data_drop_dup_bookname[data_drop_dup_bookname['出版社']== i]. 3 sort_values(by='评分',ascending=False).head(1).reset_index(drop=True)) 4 print('-' * 100)
因‘出版社’字段存在‘名称描述’、‘名称错误’等问题,最低出版社发行数无统计意义,在此不作过多分析
出版时间
按年份、月份分类统计年月的发行数量
注:由于时间已被替换为随机抽取2001-1-1至2010-12-31之间的日期,因此每次执行代码时间都将随机改变
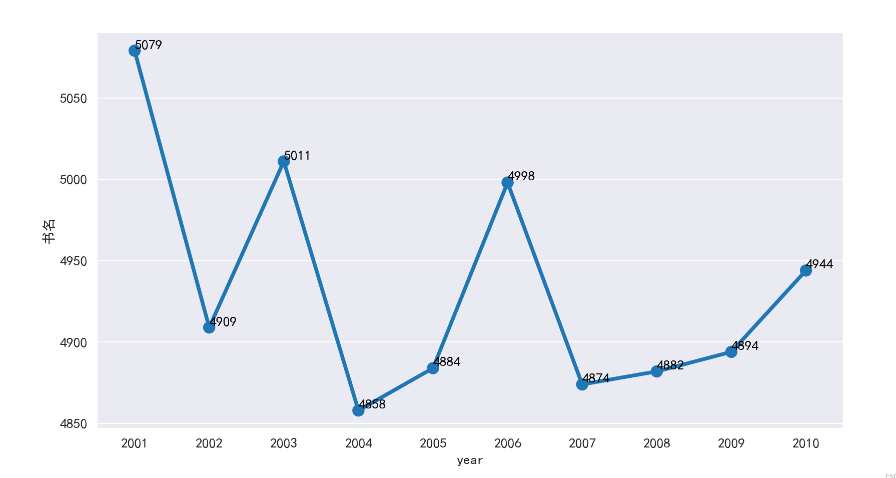
以上图为观察图例,发行书籍数量最高的是2001年(5079本),最低为2004年(4858年),两者差值为221本
从2001年至2007年,数据呈规律型显著浮动,2007年后发行数量逐渐缓慢上升
注:由于书籍数据由34412个国内外作者所组成,影响数据的浮动原因并非单一作者数据所造成,需考虑外部因素的印象。
但也因为出版时间是随机数据替换而来,无法对照2007年的相关政策或事件;因此,仅对数据表面分析,并无结合实际发行情况作2007年前后数据变动的原因分析
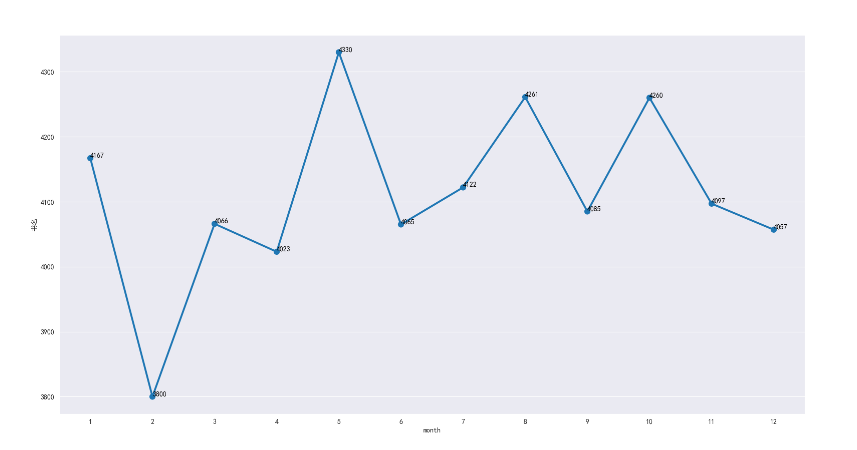
书籍在1月、5月、8月、10月发行数量最高,在二月最低(3800本),其余处于正常浮动中(设中线20%为浮动上下限)
再根据各月的书籍评分统计其均值,发现,实际2月的发行书籍质量并无随数量下降,且各月的评分均值均处于7.2-7.35之间
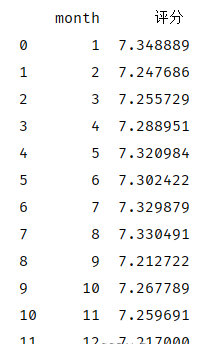
print(data_drop_dup_bookname.groupby('month').agg({'评分': 'mean'}).reset_index())
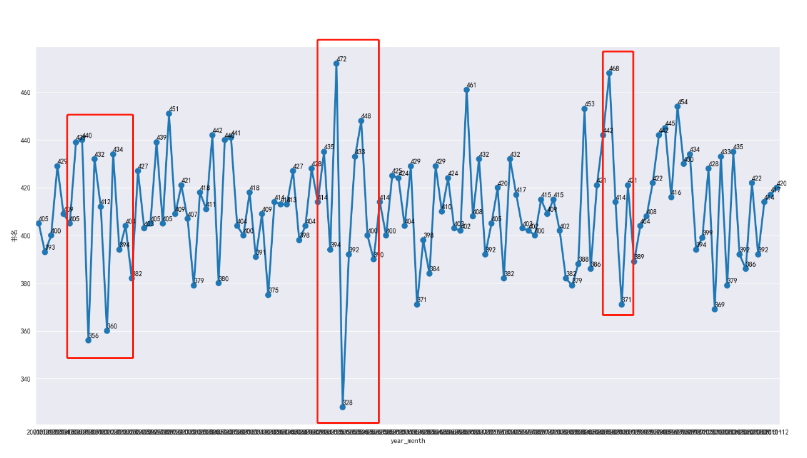
结合年份图和月份图可知,书籍发行数据大部分处于环比上下明显浮动的现象,但其中有小部分月份数据浮动显著
可追查这几个月份的作者数量、评分、评论数量,观察除数量有异常波动外是否还影响其书籍质量
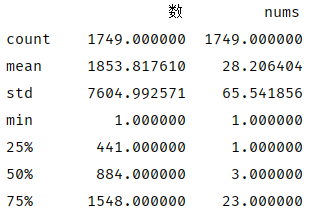
1 data_page = data_drop_dup_bookname.groupby('数').agg({'书名': 'count'})\ 2 .sort_values(by='书名').reset_index().rename(columns={'书名':'nums'}) 3 print(data_page.describe())
从上图我们可以看出,51770本书中,最小页数为‘1’,导出页数为‘1’的书名进行抽取查询后,发现部分书籍实际页数并非为‘1’,经查询导致该类现象的原因主要为:某瓣读书的页数可由用户随意更改

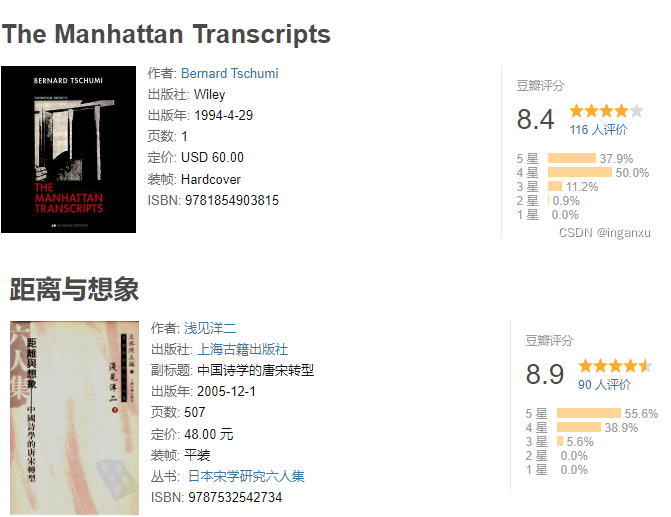
再次筛选页数小于25的书籍清单,发现仅有77本

数据描述显示,一共有1749种页数,50%的页数在441-1548页之间,其中值得关注的是‘最大页数’240000,书名为《希利尔讲世界地理》,经某瓣读书查询,实际页数为276页


print(data_clear_3[data_clear_3['数'] == 240000])
因此,该数据特征也存在错乱现象,为此需将最大和最小前10的页数导出,观察是否有误
手动查验前4个ISBM值,发现只有两个是页数异常


1 data_page_head = data_page.head(10).reset_index(drop=True) 2 print(data_page_head) 3 for i in data_page_head['数']: 4 print(data_drop_dup_bookname[data_drop_dup_bookname['数'] == i][['书名','ISBM']]) 5 print('-'*100)
再看最小页数时,发现有部分书籍页数与数据源一致,也有部分页数错乱
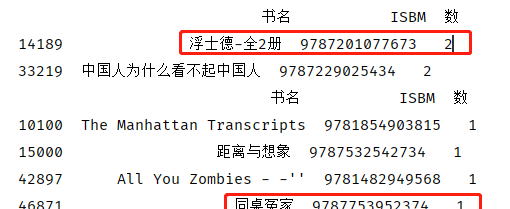

1 data_page_tail = data_page.tail(10).reset_index(drop=True) 2 print(data_page_tail) 3 for i in data_page_tail['数']: 4 print(data_drop_dup_bookname[data_drop_dup_bookname['数'] == i][['书名','ISBM','数']]) 5 print('-'*100)
页数一致:可能为人为恶意录入,并非真实页数
页数不一致:数据源错乱,可能为数据爬取时,未能正确爬取
价格
因书籍可分类为纸质书籍和电子书籍,两则的价格范围不一
通过对比电商价格范围,最终将0.5元设为纸质书籍最低价格,剩下48219行,共删除1114行数据
1 print(len(data_drop_dup_bookname)) 2 data_price = data_drop_dup_bookname.drop(data_drop_dup_bookname[data_drop_dup_bookname['价格'] < 0.5].index) 3 print(len(data_drop_dup_bookname))
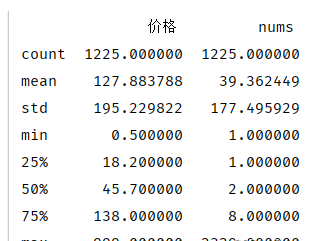
1 data_price = data_price.groupby('价格').agg({'书名': 'count'})\ 2 .sort_values(by='价格',ascending=False).reset_index().rename(columns={'书名':'nums'}) 3 print(data_price.describe())
书籍价格均值为127.88元,而中位数为45.7,标准差195.23,;其主要原因是因为价格极差过大
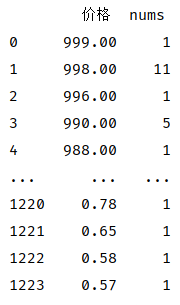
价格最高值:999元,为书籍《同志性愛聖經》,评分7.5分
print(data_drop_dup_bookname[data_drop_dup_bookname['价格'] == 999])
价格数量排名前5个价格处于25-38之间
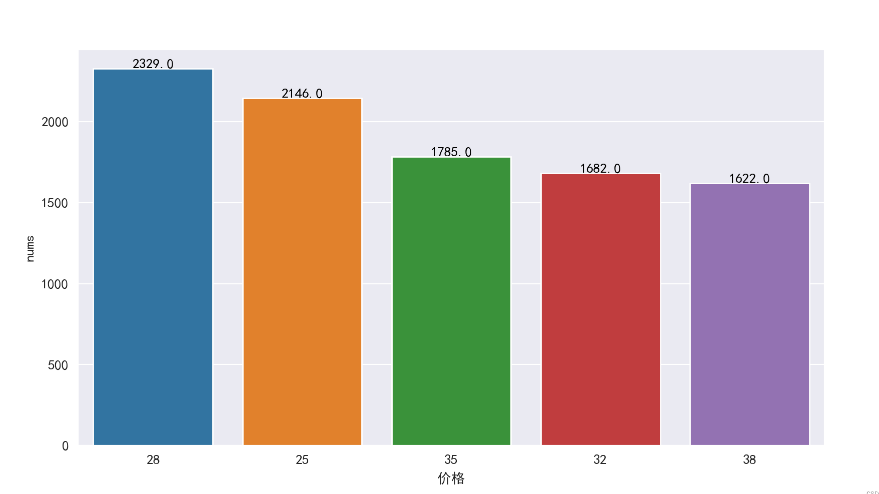
1 data_price_nums = data_drop_dup_bookname.groupby('价格').agg({'书名':'count'})\ 2 .sort_values(by='书名',ascending=False).head().reset_index().rename(columns={'书名':'nums'}) 3 g6 = sns.barplot(x='价格',y='nums',data=data_price_nums,order=data_price_nums['价格'].values.astype('int')) 4 for i,row in data_price_nums.iterrows(): 5 g6.text(row.name,row.nums+1,row.nums,ha='center',c='black')
观察上文describe后显示,书籍价格的四分位距处于18.2-138元之间
现将价格以十分位数的形式展现,结合价格数量排名前五的价格区间,得知大部分书籍的定价处于(22.62-45.7)元之间
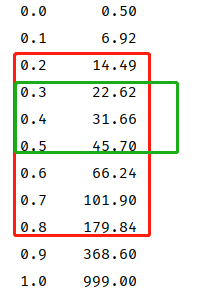
扩散分析思路:
联动发行书籍最多的作者(亦舒),对比其书籍价格处于哪个百分比之间?
联动发行书籍最多的出版社(中信出版社),对比其书籍价格处于哪个百分比之间?
统计大部分书籍(22.62-45.7元)的页数处于哪个范围?
ISBM
通过统计非重复个数发现,有两个ISBM值为相同
1 print(len(data_drop_dup_bookname)) 2 print(data_drop_dup_bookname['ISBM'].nunique())
通过定位重复值,发现重复ISBM值的书籍存在两个未知问题

1 data_duplicated = data_drop_dup_bookname['ISBM'].duplicated(keep=False) 2 print(data_drop_dup_bookname[data_duplicated == True])
第一个未知问题:ISBM值相同,实际书籍相同

ISBM值为“9787539924557”的书籍实际为同一本书籍,但名称不相同
导致该现象可能是:某瓣读书数据库添加书籍信息时,未查询是否已存在该书籍
第二个未知问题:ISBM值相同,实际书籍不相同
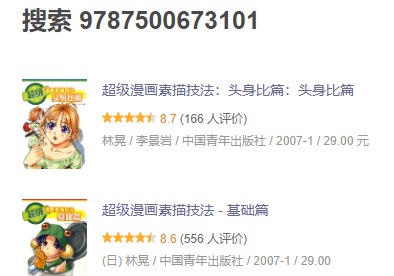
ISBM值为“9787500673101”的书籍,实际为《超级漫画素描技法》的丛书系列书籍

但通过抽查该丛书系列的其他书籍时,发现ISBM值并非为“9787500673101”
既,ISBM值“9787500673101”只有上图两本书籍,且两本书籍并非为同一本书
通过上述发现,得知ISBM值并非为唯一值,存在特殊情况
评分
因在数据清洗过程中,将“None”字符串替换为0.0,因此需将评分为0.0的数据删除
1 data_grade = data_drop_dup_bookname.drop(data_drop_dup_bookname[data_drop_dup_bookname['评分'] == 0.0].index) 2 print(data_grade['评分'].describe())
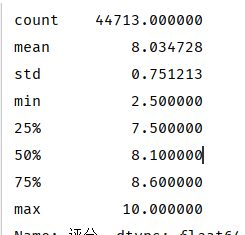
数据剩余44713行,共删除4620行数据,评分均值为8.0分
最低2.5分,共一本

print(data_grade[data_grade['评分'] == 2.5])
最高10.0分,共14本

print(data_grade[data_grade['评分'] == 10.0])
按评分分类统计数量前十的分数
从下图得知,前十最高评分数量的分值在7.6-8.5之间,其中8.1分数量最多(2353个),依次为8.2分、8.4分、7.8分......
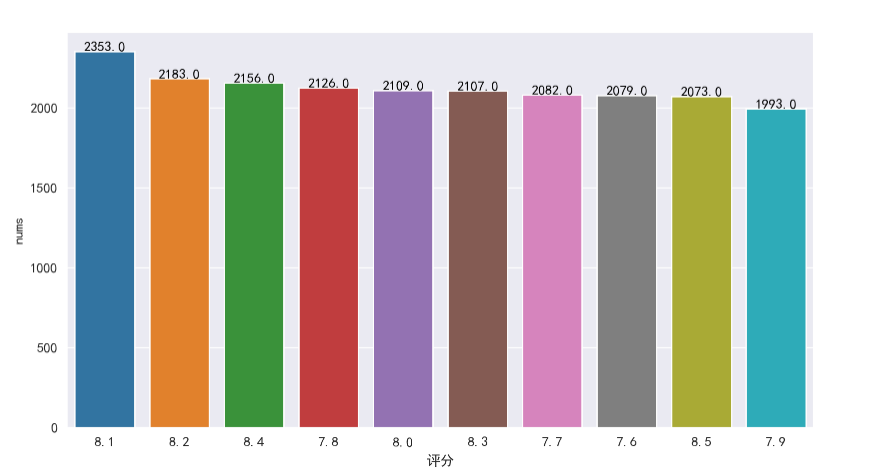
1 data_grade_g = data_grade.groupby('评分').agg({'书名':'count'})\ 2 .sort_values(by='书名',ascending=False).head(10).reset_index().rename(columns={'书名':'nums'}) 3 g8 = sns.barplot(x='评分',y='nums',data=data_grade_g,order=data_grade_g['评分'].values) 4 for i,row in data_grade_g.iterrows(): 5 g8.text(row.name,row.nums+1,row.nums,ha='center',c='black')
利用‘直接舍去取整’的方法对评分进行分层计算
在2.0-2.9评分之间的书籍只有3本
3.0-3.9评分之间的书籍只有2本
9.0-10.0评分之间的书籍只有3935本
scale为7和8的占比最高,与上文“前十最高评分数量的分值区间”结论吻合
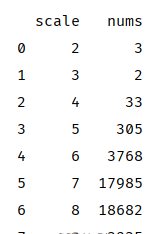
1 data_grade['scale'] = pd.cut(data_grade['评分'], 2 bins=[i for i in range(2,11)], 3 labels=range(2,10)) 4 data_grade_s = data_grade.groupby('scale').agg({'价格':'count'}).reset_index().rename(columns={'价格':'nums'}) 5 print(data_grade_s)
扩散分析思路:
发行书籍最多的作者(亦舒),其书籍评分是否有7.1-9.0评分区间以外的书籍?
发行书籍最多的前5个出版社,在7.1-9.0评分区间以外的书籍有多少,各占比多少?
统计评分在7.1-9.0之间的书籍页数分布如何?均值是多少?
统计评分在7.1-9.0之间的书籍,其价格分布如何?在22.62-45.7元之间有多少?占比多少?
评论数量
评论数量分类4193行,评论数量最高值为178288,评论数量最低值为0(占比最高),极差偏大

导出评论数量最高的5本书籍的关键信息,发现作者东野圭吾占了2本
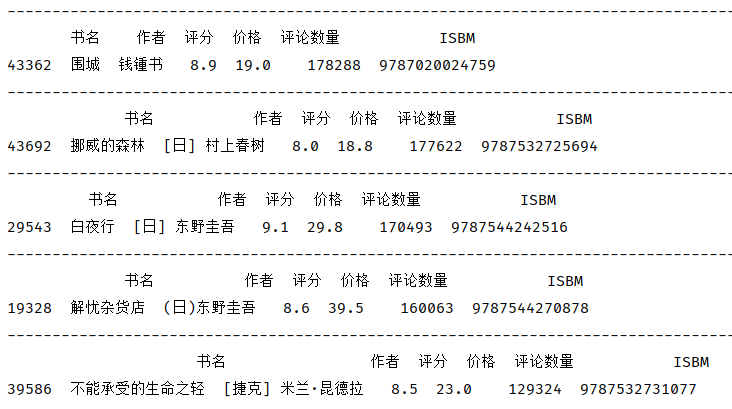
1 data_comment_h = data_drop_dup_bookname.groupby('评论数量').agg({'书名':'count'}).sort_values(by='评论数量',ascending=False).reset_index().rename(columns={'书名':'nums'}) 2 for i in data_comment_h['评论数量'].head(): 3 print(data_drop_dup_bookname[data_drop_dup_bookname['评论数量'] == i][['书名','作者','评分','价格','评论数量','ISBM']]) 4 print('-' * 100)
针对‘评论数量’特征进行describe统计,由于评论数量为0无统计意义,因此剔除数量为0后再统计
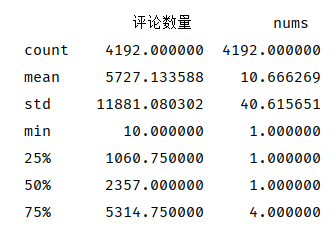
数量均值为5727条,但由于标准差为11881,因此数量均值并不可靠
max=33.55倍Q3
Q3=2.25倍median
median=2.22倍Q2
Q2=106倍min
......
极值与四分位距差距过大,反映出部分书籍的受关注程度较高(评论数量高)
再根据nums次数统计,将次数最多的前10个评论数量可视化展现
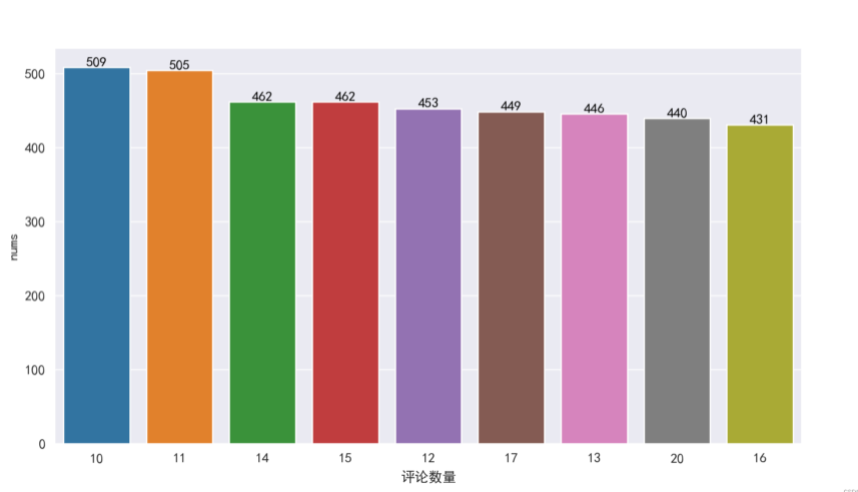
通过上图观察,次数最多的评论数量在10-20个之间
其中,书籍评论个数为‘10’的次数高达509次,占总书籍(49333本)1.03%
1 data_comment = data_comment.head(10) 2 g9 = sns.barplot(x='评论数量',y='nums',data=data_comment,order=data_comment['评论数量'].values) 3 for i,row in data_comment.iterrows(): 4 g9.text(row.name,row.nums+1,row.nums,ha='center',c='black') 5 plt.show()
扩散分析思路:
发行书籍最多的前5名作者,其书籍评论数量均值是多少?评论数量最高的书籍是哪本?
统计发行书籍最高的前5个出版社,在评分7.1以上,评论数量最高的前10本书籍清单;价格最高的钱10本书籍,评论数量各是多少?
统计评论数量在10-20个之间的书籍页数分布如何?均值是多少?
统计评分在7.1-9.0之间、评论数量在10-20个之间的书籍,其价格分布如何?在22.62-45.7元之间有多少?占比多少?
查看评论数量前5的4位作者最高评分、价格、页数的书籍清单
数据整体情况分析总结
书名:共51770行数据,数据源中同一书名存在多个作者或同作者多列信息
作者:共34412个作者,数据源中有部分书籍为同一作者,书籍数量最多的作者为‘亦舒’‘而她的书籍中,评分最高的为《紅樓夢裏人》,评分8.6分
出版社:共4003个出版社,书籍数量最多的出版社为‘中信出版社’
出版时间:年份发行数量最多的为‘2007年’,月份发行数量最多的为‘2月’,但各月评分均值并无明显差异
数:共1749种页数,50%的页数在441-1548页之间,存在部分数据错乱的现象
价格:共48219行数据,1232个价位,极差偏大,大部分书籍的定价处于(22.62-45.7)元之间
ISBM:非唯一值,存在‘ISBM值相同,实际书籍相同’和‘ISBM值相同,实际书籍不相同’两种特殊情况
评分:共44713行有效评分数据,大部分评分集中在7.1-9.0之间
评论数量:共4192类,极差偏大,大部分书籍的评论书籍集中在(10-20)个
数据分析
有哪些评分和作品数量都很高的作者
思路:
以‘评分取均值,数量取最高值’来定义‘评分和作品数量都很高’
新增‘作品数量’字段后连接到数据中
按评分和作品数量两个字段来排名
通过先以‘评分’来排名后,观察到靠前20位作者的‘作品数量’皆为1
所以下面以‘作品数量’来排名,再截取前20名作者
1 author_cnt_nums = data_clear_3.groupby('作者').agg({'书名':'count','评分':'mean'}).sort_values(by='书名',ascending=False).reset_index().rename(columns={'书名':'nums'}) 2 print(author_cnt_nums.head(20)['作者'])

再提取20位作者评分最高的书籍,考虑到有评分相同的情况,增加评论数量字段来排名
1 author_top20 = data_clear_3[data_clear_3['作者'].isin(author_cnt_nums.head(20)['作者'])].sort_values(by=['作者','评分','评论数量'],ascending=False) 2 author_top20_bookname = author_top20.groupby('作者').head(1).reset_index(drop=True) 3 print(author_top20) 4 print('-'*100) 5 print(author_top20_bookname)

如果再结合整体分析中‘评分’的区间占比,以8.6分为划分线,则只剩下14本书籍
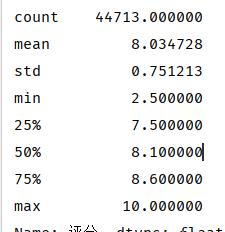
print(author_top20_bookname[author_top20_bookname['评分'] > 8.6]['书名'].reset_index(drop=True))

书籍的评分和评论数量之间是否存在相关性
删除‘数’小于25的数据行
删除‘价格’小于0.5的数据行
删除‘评分’为0.00的数据行
删除‘评论数量’为0的数据行
1 data_corr = data_clear_3.drop(data_clear_3.loc[(data_clear_3 == 0).any(1)].index) 2 data_corr = data_corr.drop(data_corr[data_corr['数'] <25].index) 3 data_corr = data_corr.drop(data_corr[data_corr['价格'] <0.5].index) 4 print(data_corr.describe())
按照上述条件删除部分数据后,数据行由51770行缩减到46030行
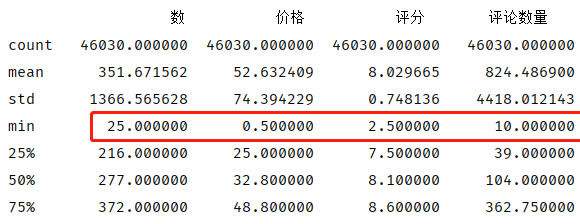
print(data_corr.corr().round(2))
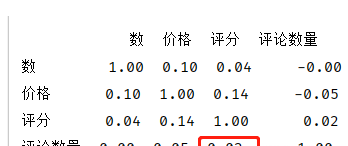
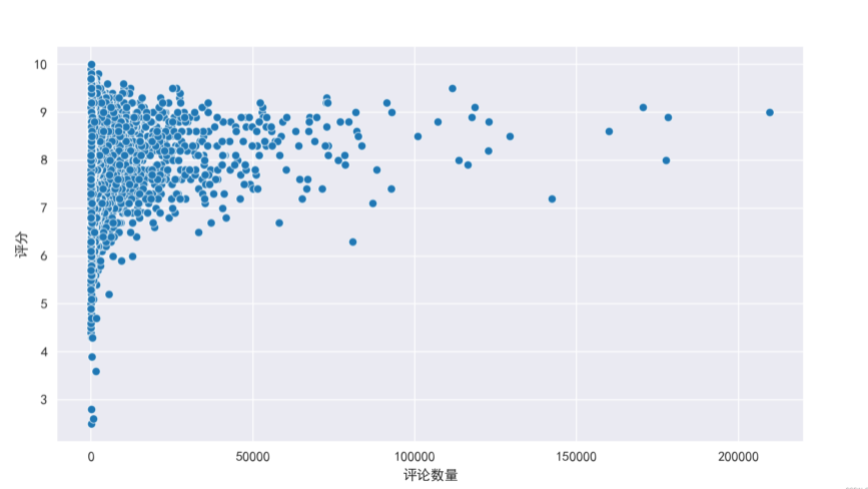
r=0.02,以0.2为区间划分,则在[-0.2,2]之间,‘评分’与‘评论数量’之间的相关性属于无相关
sns.scatterplot(x='评论数量',y='评分',data=data_corr)
哪些书籍值得推荐
作者为发行书籍数前10000名
出版社为发行书籍数前1000名
价格高于总体价格30%(22.62元)
评分高于7.1分
评论数量不低于10个
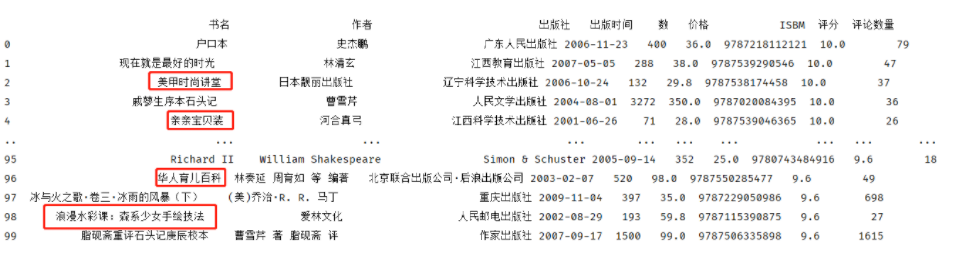
按评分高低,筛选前百书籍
1 rec_1 = data_drop_dup_bookname.groupby('作者').agg({'书名':'count'}).sort_values('书名',ascending=False).head(10000).reset_index()['作者'] 2 rec_2 = data_drop_dup_bookname.groupby('出版社').agg({'书名':'count'}).sort_values('书名',ascending=False).head(1000).reset_index()['出版社'] 3 recomment_book = data_drop_dup_bookname.loc[(data_drop_dup_bookname['作者'].isin(rec_1)) & 4 (data_drop_dup_bookname['出版社'].isin(rec_2)) & 5 (data_drop_dup_bookname['价格'] > 22.6) & 6 (data_drop_dup_bookname['评分'] > 7.1) & 7 (data_drop_dup_bookname['评论数量'] > 10)] 8 print(recomment_book.sort_values(by='评分',ascending=False).reset_index(drop=True).head(100).iloc[:,:-3])
四、总结‘
上文中提到的各种限定条件也是根据数据来划分而已,实际需要结合业务场景来划分才会更有说服力;
由于数据缺失严重、同书籍重复出现、无唯一指标,书籍信息失真等等...,关键‘时间’字段也是重新调整过,因此本文也只做的针对该数据源的描述性分析;
在本次数据分析中,我通过对于Python的相关学习,再次强化了自身技能,运用了Python强大的能力来进行数据爬取、分析、解析。但是在过程中会碰到许多困难,还需强化自己相关知识。
五、完整代码
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import random # 基础设置 data = pd.read_csv(r'C:\Users\x\Desktop\douban\book_douban.csv') # 调整格式 pd.set_option('expand_frame_repr', False) # 当列太多时显示不清楚 pd.set_option('display.unicode.east_asian_width', True) # 设置输出右对齐 plt.figure(figsize=(20, 10), dpi=200) # 中文设置 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于显示中文 plt.rcParams['axes.unicode_minus'] = False # 用于解决保存图像是负号‘-’显示为方框的问题 # 绘图风格 sns.set_style('darkgrid', {'font.sans-serif': ['SimHei']}) sns.color_palette('colorblind') # 删除多余列 # print(data.columns) data = data.iloc[:, :-1] # 数据结构 # print(data.info()) # 图形设置 def Multiple_figures(data): for index, col in enumerate(data.columns): plt.subplot(3, 3, index + 1) x = data[col].value_counts().head(3).index y = data[col].value_counts().head(3).values sns.barplot(x=x, y=y) plt.title('图%d:%s' % (index + 1, col), fontsize=10) # 设置标题 plt.subplots_adjust(wspace=0.5, hspace=0.5) # 设置图形间隔 plt.xticks(fontsize=6) # 数据清洗 data_clear_1 = data.drop(data[data['书名'] == '点击上传封面图片'].index) # 清洗错乱的书名 data_clear_2 = data_clear_1.dropna(subset=['作者']) # 清除含有空值的信息 drop_col_list = ['作者', '出版社', '价格', 'ISBM', '数'] # 清除带有"None"字符串的信息 for i in drop_col_list: data_clear_2 = data_clear_2.drop(data_clear_2.loc[data_clear_2[i] == 'None'].index).reset_index(drop=True) date_list = pd.date_range('1/1/2001', '12/31/2010') # 重新配置时间并调整时间格式 for j in range(len(data_clear_2)): data_clear_2.iloc[j, 3] = random.choice(date_list) data_clear_2.replace('None', 0, inplace=True) data_clear_2['评论数量'] = data_clear_2['评论数量'].astype('int') # 转换为数值类型 # 筛选无法转换为数值的字符串进行删除 data_clear_2['数'] = data_clear_2['数'].apply(pd.to_numeric, errors='coerce').fillna(0.0).astype('int') data_clear_2 = data_clear_2.drop(data_clear_2.loc[data_clear_2['数'] == 0].index).reset_index(drop=True) str_list = [] for i in range(len(data_clear_2['价格'])): if pd.to_numeric(data_clear_2.iloc[i, 5], errors='ignore'): # 判断转换是否可以转换为数值类型 data_clear_2.iloc[i, 5] = pd.to_numeric(data_clear_2.iloc[i, 5], errors='ignore') # 保留可转换的字符串 else: str_list.append(i) # 不可转换的字符串行索引列表 data_clear_3 = data_clear_2.drop(str_list).reset_index(drop=True) # 删除后,重置索引 data_clear_3 = data_clear_3.iloc[1:] # 特殊字符串 data_clear_3['价格'] = data_clear_3['价格'].apply(pd.to_numeric, errors='coerce').fillna(0.0).astype('float') data_clear_3['出版时间'] = pd.to_datetime(data_clear_3['出版时间']).dt.floor('d') # 转换时间格式 # print(data_clear_3.info()) # print('-' * 100) # print(data_clear_3.describe()) # 描述性统计 # 书名 data_bookname = data_clear_3.groupby('书名').agg({'作者': 'count'}) \ .sort_values(by='作者', ascending=False).head().reset_index() # 按书名分类,统计总数 # g1 = sns.barplot(x='书名', y='作者', data=data_bookname) # for i, row in data_bookname.iterrows(): # g1.text(row.name, row.作者, row.作者, ha='center', c='black') data_bookname_rank = data_clear_3[data_clear_3['书名'].isin(data_bookname['书名'].values)].sort_values( by='书名').reset_index(drop=True).iloc[:, :3] # print(data_bookname_rank) # 作者 data_drop_dup_bookname = data_clear_3.drop_duplicates(subset='书名', keep='first').reset_index(drop=True) # 删除重复书名 # print(data_drop_dup_bookname) data_author = data_drop_dup_bookname.groupby('作者').agg({'书名': 'count'}) \ .sort_values('书名', ascending=False).head(5).reset_index() # 按作者分类,统计总数 # g2 = sns.barplot(x='作者', y='书名', data=data_author) # for i, row in data_author.iterrows(): # g2.text(row.name, row.书名, row.书名, ha='center', c='black') # print(data_drop_dup_bookname) # print('-'*100) # print(data_drop_dup_bookname[data_drop_dup_bookname['作者']== '亦舒'].sort_values(by='评分',ascending=False).head().reset_index(drop=True)) # print('-'*100) # print(data_drop_dup_bookname[data_drop_dup_bookname['作者'] == '鲁迅'].sort_values(by='评分',ascending=False).head().reset_index(drop=True)) # 出版社 data_publisher = data_drop_dup_bookname.groupby('出版社').agg({'书名': 'count'}) \ .sort_values('书名', ascending=False).head().reset_index() # 按出版社分类,统计总数 # print(data_publisher) # g3 = sns.barplot(x='出版社', y='书名', data=data_publisher) # for i, row in data_publisher.iterrows(): # g3.text(row.name, row.书名, row.书名, ha='center', c='black') # print('-'*100) # for i in data_publisher['出版社']: # print(data_drop_dup_bookname[data_drop_dup_bookname['出版社']== i]. # sort_values(by='评分',ascending=False).head(1).reset_index(drop=True)) # print('-' * 100) # 出版时间 data_drop_dup_bookname['year'] = data_drop_dup_bookname['出版时间'].dt.year data_drop_dup_bookname['month'] = data_drop_dup_bookname['出版时间'].dt.month data_drop_dup_bookname['year_month'] = data_drop_dup_bookname['出版时间'].apply(lambda x: x.strftime('%Y-%m')) data_year_cnt = data_drop_dup_bookname.groupby('year').agg({'书名': 'count'}).reset_index() # 按年份统计 # print(data_year_cnt) # g4_year = sns.pointplot(x='year', y='书名', data=data_year_cnt) # for i, row in data_year_cnt.iterrows(): # g4_year.text(row.name, row.书名+1, row.书名, ha='left', c='black') # print('-'*100) # plt.show() data_month_cnt = data_drop_dup_bookname.groupby('month').agg({'书名': 'count'}).reset_index() # 按年份统计 # print(data_month_cnt) # g4_month = sns.pointplot(x='month', y='书名', data=data_month_cnt) # for i, row in data_month_cnt.iterrows(): # g4_month.text(row.name, row.书名+1, row.书名, ha='left', c='black') # print('-'*100) # plt.show() data_year_month_cnt = data_drop_dup_bookname.groupby('year_month').agg({'书名': 'count'}).reset_index() # 按年份统计 # print(data_year_month_cnt) # g4_year_month = sns.pointplot(x='year_month', y='书名', data=data_year_month_cnt) # for i, row in data_year_month_cnt.iterrows(): # g4_year_month.text(row.name, row.书名+1, row.书名, ha='left', c='black') # print('-'*100) # print(data_drop_dup_bookname.groupby('month').agg({'评分': 'mean'}).reset_index()) # plt.show() # 数 data_page = data_drop_dup_bookname.groupby('数').agg({'书名': 'count'}) \ .sort_values(by='数', ascending=False).reset_index().rename(columns={'书名': 'nums'}) # print(data_page.describe()) # print(data_drop_dup_bookname[data_drop_dup_bookname['数'] == 240000]) # print('-'*100) # 最高前10页数 data_page_head = data_page.head(10).reset_index(drop=True) # print(data_page_head) # for i in data_page_head['数']: # print(data_drop_dup_bookname[data_drop_dup_bookname['数'] == i][['书名','ISBM','数']]) # print('-'*100) # 最低前10页数 data_page_tail = data_page.tail(10).reset_index(drop=True) # print(data_page_tail) # for i in data_page_tail['数']: # print(data_drop_dup_bookname[data_drop_dup_bookname['数'] == i][['书名','ISBM','数']]) # print('-'*100) # 价格 # print(len(data_drop_dup_bookname)) data_price = data_drop_dup_bookname.drop(data_drop_dup_bookname[data_drop_dup_bookname['价格'] < 0.5].index) # print(len(data_drop_dup_bookname)) data_price = data_price.groupby('价格').agg({'书名': 'count'}) \ .sort_values(by='价格', ascending=False).reset_index().rename(columns={'书名': 'nums'}) # print(data_price.describe()) # print(data_price) # print(data_drop_dup_bookname[data_drop_dup_bookname['价格'] == 999]) data_price_nums = data_drop_dup_bookname.groupby('价格').agg({'书名': 'count'}) \ .sort_values(by='书名', ascending=False).head().reset_index().rename(columns={'书名': 'nums'}) # g6 = sns.barplot(x='价格',y='nums',data=data_price_nums,order=data_price_nums['价格'].values.astype('int')) # for i,row in data_price_nums.iterrows(): # g6.text(row.name,row.nums+1,row.nums,ha='center',c='black') data_price_quantile = data_price['价格'].quantile([i / 10 for i in range(11)]) # print(data_price_quantile) # ISBM # print(len(data_drop_dup_bookname)) # print(data_drop_dup_bookname['ISBM'].nunique()) data_duplicated = data_drop_dup_bookname['ISBM'].duplicated(keep=False) # print(data_drop_dup_bookname[data_duplicated == True]) # 评分 data_grade = data_drop_dup_bookname.drop(data_drop_dup_bookname[data_drop_dup_bookname['评分'] == 0.0].index) # print(data_grade['评分'].describe()) # print(data_grade[data_grade['评分'] == 2.5]) # print(data_grade[data_grade['评分'] == 10.0]) data_grade_g = data_grade.groupby('评分').agg({'书名': 'count'}) \ .sort_values(by='书名', ascending=False).head(10).reset_index().rename(columns={'书名': 'nums'}) # g8 = sns.barplot(x='评分',y='nums',data=data_grade_g,order=data_grade_g['评分'].values) # for i,row in data_grade_g.iterrows(): # g8.text(row.name,row.nums+1,row.nums,ha='center',c='black') # plt.show() data_grade['scale'] = pd.cut(data_grade['评分'], bins=[i for i in range(2, 11)], labels=range(2, 10)) data_grade_s = data_grade.groupby('scale').agg({'价格': 'count'}).reset_index().rename(columns={'价格': 'nums'}) # print(data_grade_s) # 评论数量 data_comment_h = data_drop_dup_bookname.groupby('评论数量').agg({'书名': 'count'}) \ .sort_values(by='评论数量', ascending=False).reset_index().rename(columns={'书名': 'nums'}) # print(data_comment_h) # print('-'*100) # for i in data_comment_h['评论数量'].head(): # print(data_drop_dup_bookname[data_drop_dup_bookname['评论数量'] == i][['书名','作者','评分','价格','评论数量','ISBM']]) # print('-' * 100) data_comment = data_drop_dup_bookname.groupby('评论数量').agg({'书名': 'count'}) \ .sort_values(by='书名', ascending=False).reset_index().rename(columns={'书名': 'nums'}) data_comment = data_comment.drop(data_comment[data_comment['评论数量'] == 0].index).reset_index(drop=True) # print(data_comment.describe()) data_comment = data_comment.head(10) # g9 = sns.barplot(x='评论数量',y='nums',data=data_comment,order=data_comment['评论数量'].values) # for i,row in data_comment.iterrows(): # g9.text(row.name,row.nums+1,row.nums,ha='center',c='black') # plt.show() # Multiple_figures(data_clear_3) # 数据分析 # 有哪些评分和作品数量都很高的作者 author_cnt_nums = data_drop_dup_bookname.groupby('作者').agg({'书名': 'count', '评分': 'mean'}).sort_values(by='书名', ascending=False).reset_index().rename( columns={'书名': 'nums'}) # print(author_cnt_nums.head(20)['作者']) # print('-'*100) author_top20 = data_drop_dup_bookname[data_drop_dup_bookname['作者'].isin(author_cnt_nums.head(20)['作者'])].sort_values( by=['作者', '评分', '评论数量'], ascending=False) author_top20_bookname = author_top20.groupby('作者').head(1).reset_index(drop=True) # print(author_top20) # print('-'*100) # print(author_top20_bookname) # print(author_top20_bookname[author_top20_bookname['评分'] > 8.6]['书名'].reset_index(drop=True)) # 书籍的评分和评论数量之间是否存在相关性 data_corr = data_drop_dup_bookname.drop(data_drop_dup_bookname.loc[(data_drop_dup_bookname == 0).any(1)].index) data_corr = data_corr.drop(data_corr[data_corr['数'] < 25].index) data_corr = data_corr.drop(data_corr[data_corr['价格'] < 0.5].index) # print(data_corr.describe()) # print('-'*100) # print(data_corr.corr().round(2)) # sns.scatterplot(x='评论数量',y='评分',data=data_corr) # plt.show() # 哪些书籍值得推荐 rec_1 = \ data_drop_dup_bookname.groupby('作者').agg({'书名': 'count'}).sort_values('书名', ascending=False).head(10000).reset_index()[ '作者'] rec_2 = \ data_drop_dup_bookname.groupby('出版社').agg({'书名': 'count'}).sort_values('书名', ascending=False).head(1000).reset_index()[ '出版社'] recomment_book = data_drop_dup_bookname.loc[(data_drop_dup_bookname['作者'].isin(rec_1)) & (data_drop_dup_bookname['出版社'].isin(rec_2)) & (data_drop_dup_bookname['价格'] > 22.6) & (data_drop_dup_bookname['评分'] > 7.1) & (data_drop_dup_bookname['评论数量'] > 10)] print(recomment_book.sort_values(by='评分', ascending=False).reset_index(drop=True).head(100).iloc[:, :-3])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号