访问外网,程序跑的时间会长一点,耐心等待!
全部源代码:
# -*- coding = utf-8 -*-
# @Time : 2022/5/13 9:33
# @Author :王敬博
# @File : spider.py
# @Software: PyCharm
from bs4 import BeautifulSoup #网页解析
import re #正则表表达式文字匹配
import parsel as parsel
import urllib.request,urllib.error #指定url,获取网页数据
import pymysql.cursors #连接mysql数据库
num = 1;
def main():
baseurl = "https://openaccess.thecvf.com/CVPR2019?day=2019-06-18"
(datalist,num) = getData(baseurl)
print("爬取完毕!")
#调研分析数据函数
conn(datalist,num) #调用保存函数
print("保存到数据库!")
def askURL(url):
head = { #伪装请求头,模拟浏览器访问
"User-Agent":" Mozilla / 5.0(Linux;Android6.0;Nexus5 Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 99.0.4844.51Mobile Safari / 537.36"
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html #返回爬到所有的html数据
def getData(baseurl):
html = askURL(baseurl)
selector = parsel.Selector(html)
datalist = []
titlelist = []
authorlist = []
abstractlist = [] #摘要列表
datelist = [] #时间列表
pdflist = [] #pdf链接列表
href_list = selector.xpath('//dl/dt/a/@href').getall()
href_list1 = []
for href in href_list:
href1 = 'https://openaccess.thecvf.com/'+href
href_list1.append(href1)
num = len(href_list1)
for href in href_list1:
href_data = askURL(href)
selector_02 = parsel.Selector(href_data)
paper_title =selector_02.xpath('// *[ @ id = "papertitle"]/text()').get()
title = paper_title.strip()
titlelist.append(title)
paper_author = selector_02.xpath('//*[@id="authors"]/b/i/text()').get()
authorlist.append(paper_author)
papaer_abstract = selector_02.xpath('//*[@id="abstract"]/text()').get()
abstract = papaer_abstract.strip()
abstractlist.append(abstract)
paper_date = selector_02.xpath('//*[@id="authors"]').get()
finddata = re.compile(r'(CVPR)(.*),')
paper_date = str(re.findall(finddata,paper_date))
date = paper_date.replace("[('CVPR', '),"," ")
date = date.replace("')]","")
date = date.strip()
datelist.append(date)
pdflink = selector_02.xpath('//*[@id="content"]/dl/dd/a[1]').get()
findpdflink = re.compile(r'<a href="../../(.*?)">pdf</a>')
pdflink = str(re.findall(findpdflink, pdflink))
pdflink = pdflink.replace("['", "")
pdflink = pdflink.replace("']", "")
pdflink = "https://openaccess.thecvf.com/" + pdflink
pdflist.append(pdflink)
for i in range(0,len(href_list1)):
print(f"--------------正在爬取第{i}条--------------")
data = []
data.append(titlelist[i])
data.append(authorlist[i])
data.append(abstractlist[i])
data.append(pdflist[i])
data.append(datelist[i])
datalist.append(data)
return datalist,num
def conn(datalist,num): #改成自己的数据库信息即可
conn = pymysql.connect(host='localhost',user='root',password='1767737316.',database='paperdata',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor()
for i in range(0,num):
print(f"--------------正在保存第{i+1}条--------------")
list = datalist[i]
data1 = tuple(list)
#print(data1)
sql = 'insert into paper(title,author,abstract,pdflink,date1) values(%s,%s,%s,%s,%s)' #五个字符串对应MySQL的列名
# (2)准备数据 ,此外设置的字符长度一定要大一点。
# (3)操作
try:
cursor.execute(sql, data1)
conn.commit()
except Exception as e:
print('插入数据失败', e)
conn.rollback() # 回滚
# 关闭游标
# cursor.close()
# 关闭连接
# conn.close()
if __name__ == "__main__":
main()
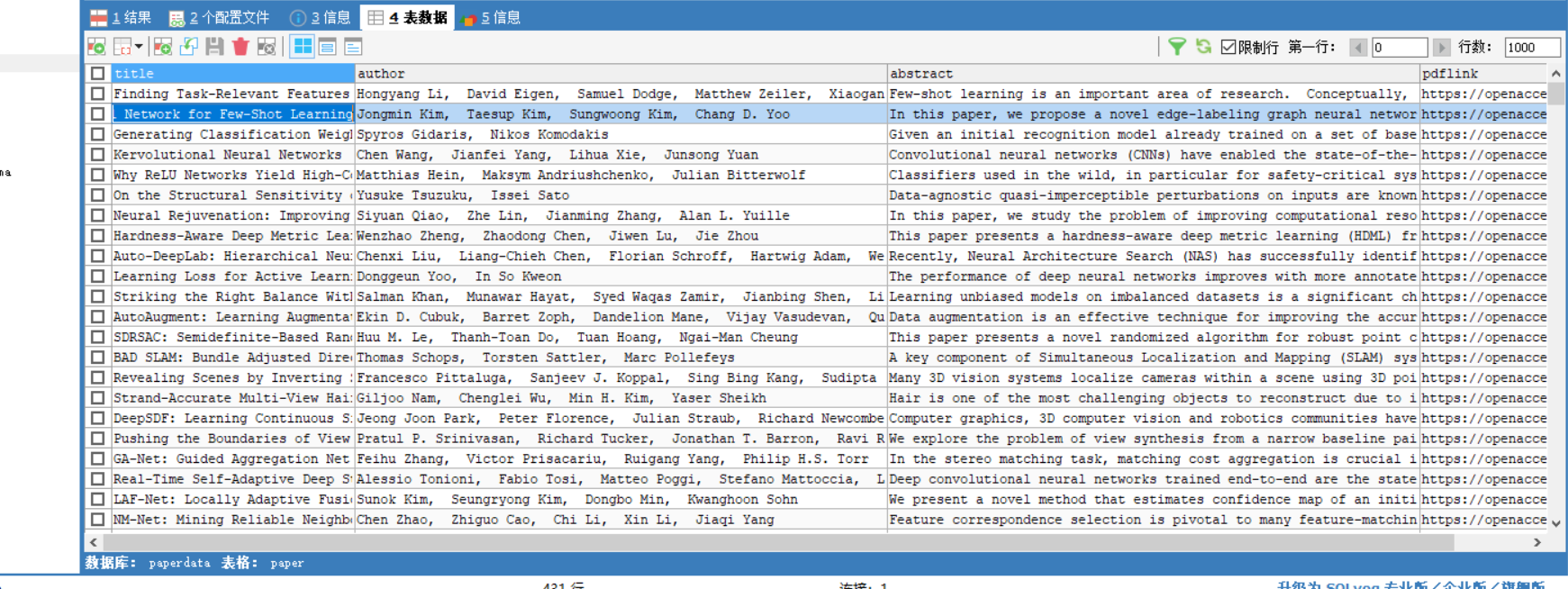
截图



 浙公网安备 33010602011771号
浙公网安备 33010602011771号