shell基础
1、什么是shell
Shell(外壳) 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
什么是脚本?
脚本简单地说就是一条条的文字命令(一些指令的堆积),这些文字命令是可以看到的(如可以用记事本打开查看、编辑)。
常见的脚本: JavaScript(JS,前端),VBScript, ASP,JSP,PHP(后端),SQL(数据库操作语言),Perl,Shell,python,Ruby,JavaFX,Lua等。
为什么要学习和使用shell?
Shell属于内置的脚本程序开发的效率非常高,依赖于功能强大的命令可以迅速地完成开发任务(批处理)
语法简单,代码写起来比较轻松,简单易学
常见的shell种类?(了解)
在linux中有很多类型的shell,不同的shell具备不同的功能,shell还决定了脚本中函数的语法,Linux中默认的shell是/bin/bash(重点),流行的shell有ash、bash、ksh、csh、zsh等,不同的shell都有自己的特点以及用途。
csh
C shell 使用的是“类C”语法,csh是具有C语言风格的一种shell,其内部命令有52个,较为庞大。目前使用的并不多,已经被/bin/tcsh所取代。
ksh
Korn shell 的语法与 Bourne shell 相同,同时具备了 C shell 的易用特点。许多安装脚本都使用 ksh ,ksh有42条内部命令,与bash相比有一定的限制性。
tcsh
tcsh是csh的增强版,与 C shell 完全兼容。
sh
是一个快捷方式,已经被/bin/bash所取代。
nologin
指用户不能登录
zsh
目前Linux里最庞大的一种shell:zsh。它有84个内部命令,使用起来也比较复杂。一般情况下,不会使用该shell。
bash
大多数Linux系统默认使用的shell,bash shell 是 Bourne shell 的一个免费版本,它是最早的 Unix shell,bash还有一个特点,可以通过help命令来查看帮助。包含的功能几乎可以涵盖shell所具有的功能,所以一般的shell脚本都会指定它为执行路径。
2、shell入门
编写规范:
代码规范:
#!/bin/bash [指定告知系统当前这个脚本要使用的shell解释器]
Shell相关指令
文件命名规范: 文件名.sh .sh是linux下bash shell 的默认后缀
使用流程:
①创建.sh文件 touch/vim
②编写shell代码
③执行shell脚本 脚本必须得有执行权限
案例1:创建test.sh,实现第一个shell脚本程序,输出hello world.
输出命令语法:#echo 123
注意:输出的内容如果包含字母和符号,则需要用引号包括起来。如果是纯数字可以包也可以不包,建议用双引号包含。

3、常用命令工具的使用:grep、sed、awk、cut、sort、unique、tee、paste
正则:(多用于处理文件中内容) 常常与grep或者vim编辑使用
\:转译符,使特殊意义的符号失去作用,作为普通文本符号输入;
^a:表示匹配以a为开始的行;
a$:表示匹配以a为结束的行;
a|b:表示匹配多个选项,满足其中一个即可;
[a-z]:表示匹配a-z任意一个字符;
*:表示匹配一个或者多个任意字符;
.:表示匹配单个字符
shell通配符(元字符):表示不是本意,!!!!用来匹配文件,对文件的处理常常与find搭配
*:匹配任意一个或者多个字符;
?:匹配任意一个字符;
[a-z]:表示匹配a-z任意一个字符;
():在shell中执行命令(cd /;ls) (touch abc;vim abc)
{}:相当于遍历{}中的所有内容 touch fi{1..9}创建fi1-fi9的处理
grep工具:用来处理文件,查找文件中对应的内容,通过正则表达式匹配文件中的关键字 正则表达式:通过单一字符来匹配关键字
(1)查找当前目录下包含 test 关键字的文件 grep -ri "test" ./ -r :递归匹配
(2)匹配 f1 文件中包含 test 关键字的行数 grep -c "test" f1 -i :忽略大小写
(3)匹配 f1 文件中的关键字 test grep -i "test" f1 -n显示关键字所在行号
(4)匹配 f1 文件中的关键字 test 并显示行号 grep -n "test" f1 -v 取反,即输入内容以外的内容
(5)匹配 f1 文件中以 a 开头的行 grep "^a" f1 -E 支持多个正则表达式
(6)匹配 f1 文件中以 a 结尾的行 grep "a$" f1
(7)匹配当前目录下所有包含以 a 结尾的文件 grep -r "a$" ./
(8)匹配 f1 文件中含有 te 的单词 grep "\<te"* f1(*前有空格) 或者 grep "\<te" f1
(9)匹配 f1 文件中以 te 或者 t 开头的单词 grep "\<te"* f1(*前没有空格)
(10)匹配 f1 文件中的 test 单词 grep "\<test\>" f1
(11)匹配 f1 文件中以 R 或 S 或 T 开头的行 grep "^[R-T]" f1
(12)匹配 f1 文件中以 T 开头并且第二个字符是 e 的行 grep "^T"e
(13) 匹配fi文件中以e之前有0个或多个T为开头的行 grep "^T*"e fi
egrep 即 grep -E,支持多个正则表达式。
1、?与+匹配 ?:匹配前面的正则表达式 0 次或 1 次 +:匹配前面的正则表达式 1 次或多次
vim f1 内容:
aaaaa
aabbb
abbba
cccca
1、? 匹配以 a 开头的行:egrep "^a?" f1 +匹配以 a 开头的行:egrep "^a+" f1
2、匹配 f1 文件中以 b 或 c 开头的行 egrep "(^b|^c)" f1
3、匹配 f1 文件中不包含 test 关键字的行 egrep -v "test" f1
4、匹配 f1 文件中不包含 good 和 morning 关键字的行 egrep -v "^(good|morning)" f1
Cut 工具:
cut工具用于列截取
-c: 以字符为单位进行分割。
-d: 自定义分隔符,默认为制表符。
-f: 与-d一起使用,指定显示哪个区域。
[:alnum:] all letters and digits//所有字母和数字
[:alpha:] all letters//所有字母
[:blank:] all horizontal whitespace//所有水平空白
[:cntrl:] all control characters//所有控制字符
Ctrl-H 退格符
Ctrl-J 新行
Ctrl-M 回车
[:digit:] all digits//所有数字
[:graph:] all printable characters, not including space//所有可打印的字符,不包含空格
[:lower:] all lower case letters//所有小写字母
[:print:] all printable characters, including space//所有可打印的字符,包含空格
[:punct:] all punctuation characters//所有的标点符号
[:space:] all horizontal or vertical whitespace//所有水平或垂直的空格
[:upper:] all upper case letters//所有大写字母
[:xdigit:] all hexadecimal digits//所有十六进制数字
[=CHAR=] all characters which are equivalent to CHAR//所有字符
例:
(1)# cut -d: -f1 passwd cut -d: -f1,3 passwd | head -4选前四行及第一和第三列


截取前6个字符 截取第6个及以后的字符 截取第6-15个字符



sort工具
sort:将文件的每一行作为一个单位,从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
-u :去除重复行
-r :降序排列,默认是升序
-o : 将排序结果输出到文件中 类似 重定向符号>
-n :以数字排序,默认是按字符排序
-t :分隔符
-k :第N列
-b :忽略前导空格。
-R :随机排序,每次运行的结果均不同。
按照数字排序 以冒号分隔第三列进行uid排序 将排序结果输出到文件中 类似 重定向符号>


sed 工具
通过正则表达式,对指定文件的内容进行截取、过滤、修改。参数 i 表示执行操 作,如果不加参数 i 只会匹配出而不会对源文件进行修改操作。
| 参数 | 完整参数 | 说明 |
|---|---|---|
| -e script | --expression=script | 以选项中的指定的script来处理输入的文本文件 |
| -f script | --files=script | 以选项中的指定的script文件来处理输入的文本文件 |
| -h | --help | 显示帮助 |
| -n | --quiet --silent | 仅显示script处理后的结果 |
| -V | --version | 显示版本信息 |
文件:指定待处理的文本文件列表
sed命令
| 命令 | 说明 |
|---|---|
| d | 删除,删除选择的行 |
| D | 删除模板块的第一行 |
| s | 替换指定字符 |
| h | 拷贝模板块的内容到内存中的缓冲区 |
| H | 追加模板块的内容到内存中的缓冲区 |
| g | 获得内存缓冲区的内容,并替代当前模板块中文本 |
| G | 获得内存缓冲区的内容,并追加到当前模板块文本的后面 |
| l | 列表不能打印字符的清单 |
| n | 读取下一个输入行,用下一个命令处理新的行而不是第一个命令 |
| N | 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码 |
| p | 打印模板块的行 |
| P | 打印模板块的第一行 |
| q | 退出sed |
| b label | 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾 |
| r file | 从file中读行 |
| t label | if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾 |
| T label | 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾 |
| w file | 写并追加模板块到file末尾 |
| W file | 写并追加模板块的第一行到file末尾 |
| ! | 表示后面的命令对所有没有被选定的行发生作用 |
| = | 打印当前行号 |
| # | 把注释扩展到第一个换行符以前 |
sed替换标记
| 命令 | 说明 |
|---|---|
| g | 表示行内全面替换 |
| p | 表示打印行 |
| w | 表示把行写入一个文件 |
| x | 表示互换模板块中的文本和缓冲区中的文本 |
| y | 表示把一个字符翻译为另外的字符(但是不用于正则表达式) |
| \1 | 子串匹配标记 |
| & | 已匹配字符串标记 |
sed元字符集
| 命令 | 说明 |
|---|---|
| ^ | 匹配行开始,如:/^sed/匹配所有以sed开头的行。 |
| $ | 匹配行结束,如:/sed$/匹配所有以sed结尾的行。 |
| . | 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。 |
| * | 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。 |
| [] | 匹配一个指定范围内的字符,如/[sS]ed/匹配sed和Sed。 |
| [^] | 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。 |
| (..) | 匹配子串,保存匹配的字符,如s/(love)able/\1rs,loveable被替换成lovers。 |
| & | 保存搜索字符用来替换其他字符,如s/love/&/,love这成love。 |
| < | 匹配单词的开始,如:/<love/匹配包含以love开头的单词的行。 |
| > | 匹配单词的结束,如/love>/匹配包含以love结尾的单词的行。 |
| x{m} | 重复字符x,m次,如:/0{5}/匹配包含5个0的行。 |
| x{m,} | 重复字符x,至少m次,如:/0{5,}/匹配至少有5个0的行。 |
| x{m,n} | 重复字符x,至少m次,不多于n次,如:/0{5,10}/匹配5~10个0的行。 |
以上sed说明出自:https://www.cnblogs.com/maxincai/p/5146338.html
1、删除 passwd 文件中的 1-3 行 sed -i '1,3d' passwd
2、删除 passwd 文件中的第 16 行 sed -i '16d' passwd
3、删除 passwd 文件中的第 10 行至文件末尾 sed -i '10,$d' passwd
4、删除 passwd 文件中包含关键字"ftp"的行 sed -i '/ftp/d' passwd(d 就是 delete 的意思)
5、匹配 passwd 文件中包含关键字 halt 的行 sed -n '/halt/p' passwd(p 就是 print 的意思)
6、匹配 passwd 文件中以 h 或 s 开头,后面为 alt 关键字的行 sed -n '/^[hs]alt/p' passwd
7、将 passwd 文件中所有的 adm 替换为 root sed -i 's/adm/root/g' passwd
8、将 passwd 文件中的第 1-3 行删除,并将所有的 root 替换为 xxx sed -i -e '1,3d' -e 's/root/xxx/gp' passwd
awk工具
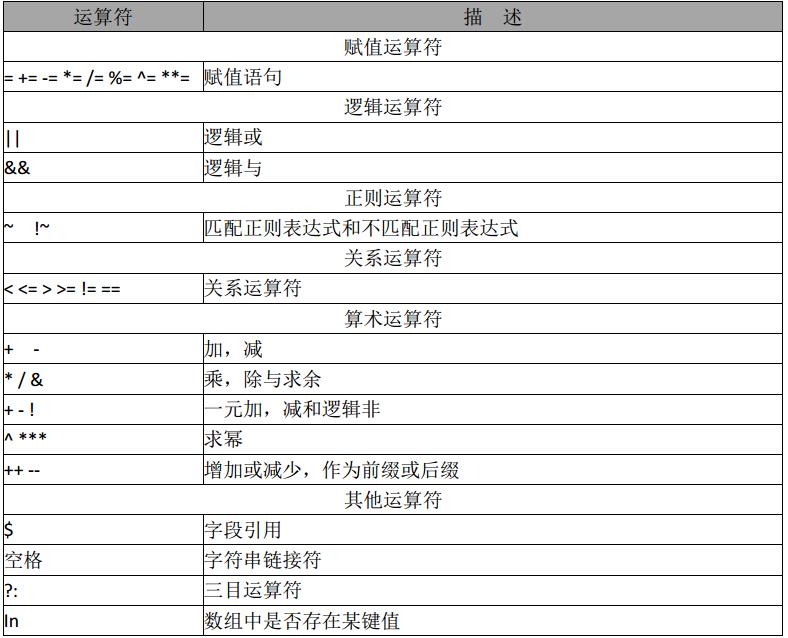
awk运算符
常用 awk 内置变量

awk 正则

awk 的 if、循环和数组
条件语句
awk 提供了非常好的类似于 C 语言的 if 语句。
{
if ($1=="foo"){
if($2=="foo"){
print "uno"
}else{
print "one"
}
}elseif($1=="bar"){
print "two"
}else{
print "three"
}
}
使用 if 语句还可以将代码:
! /matchme/ { print $1 $3 $4 }
转换成:
{
if ( $0 !~ /matchme/ ) {
print $1 $3 $4
}
}
循环结构
我们已经看到了 awk 的 while 循环结构,它等同于相应的 C 语言 while 循环。 awk 还有"do...while"循环,它在代码块结尾处对条件求值,而不像标准 while 循环那样在开始处求值。
它类似于其它语言中的"repeat...until"循环。以下是一个示例:
do...while 示例
{
count=1do {
print "I get printed at least once no matter what"
} while ( count !=1 )
}
与一般的 while 循环不同,由于在代码块之后对条件求值, "do...while"循环永远都至少执行一次。换句话说,当第一次遇到普通 while 循环时,如果条件为假,将永远不执行该循环。
for 循环
awk 允许创建 for 循环,它就象 while 循环,也等同于 C 语言的 for 循环:
for ( initial assignment; comparison; increment ) {
code block
}
以下是一个简短示例:
for ( x=1;x<=4;x++ ) {
print "iteration", x
}
此段代码将打印:
iteration1 iteration2 iteration3 iteration4
break 和 continue
此外,如同 C 语言一样, awk 提供了 break 和 continue 语句。使用这些语句可以更好地控制 awk 的循环结构。以下是迫切需要 break 语句的代码片断:
while 死循环
while (1) {
print "forever and ever..."
}
while 死循环 1 永远代表是真,这个 while 循环将永远运行下去。
以下是一个只执行十次的循环:
#break 语句示例
x=1
while(1) {
print "iteration", x
if ( x==10 ) {
break
}
x++
}
这里, break 语句用于“逃出”最深层的循环。 "break"使循环立即终止,并继续执行循环代码块后面的语句。
continue 语句补充了 break,其作用如下:
x=1while (1) {
if ( x==4 ) {
x++
continue
}
print "iteration", x
if ( x>20 ) {
break
}
x++
}
这段代码打印"iteration1"到"iteration21", "iteration4"除外。如果迭代等于 4,则增加 x并调用 continue 语句,该语句立即使 awk 开始执行下一个循环迭代,而不执行代码块的其余部分。如同 break 一样,
continue 语句适合各种 awk 迭代循环。在 for 循环主体中使用时, continue 将使循环控制变量自动增加。以下是一个等价循环:
for ( x=1;x<=21;x++ ) {
if ( x==4 ) {
continue
}
print "iteration", x
}
在while 循环中时,在调用 continue 之前没有必要增加 x,因为 for 循环会自动增加 x。
数组
AWK 中的数组都是关联数组,数字索引也会转变为字符串索引
{
cities[1]=”beijing”
cities[2]=”shanghai”
cities[“three”]=”guangzhou”
for( c in cities) {
print cities[c]
}
print cities[1]
print cities[“1”]
print cities[“three”]
}
for…in 输出,因为数组是关联数组,默认是无序的。所以通过 for…in 得到是无序的数组。如果需要得到有序数组,需要通过下标获得。
数组的典型应用
用 awk 中查看服务器连接状态并汇总
netstat -an|awk '/^tcp/{++s[$NF]}END{for(a in s)print a,s[a]}'
ESTABLISHED 1
LISTEN 20
统计 web 日志访问流量,要求输出访问次数,请求页面或图片,每个请求的总大小,总访问流量的大小汇总
awk '{a[$7]+=$10;++b[$7];total+=$10}END{for(x in a)print b[x],x,a[x]|"sort -rn -k1";print
"total size is :"total}' /app/log/access_log
total size is :172230
21 /icons/poweredby.png 83076
14 / 70546
8 /icons/apache_pb.gif 18608
a[$7]+=$10 表示以第 7 列为下标的数组( $10 列为$7 列的大小),把他们大小累加得到
$7 每次访问的大小,后面的 for 循环有个取巧的地方, a 和 b 数组的下标相同,所以一
条 for 语句足矣
常用字符串函数


转自:https://www.cnblogs.com/ginvip/p/6352157.html
通过正则表达式,截取行与列。 注:df -h 命令用于查询磁盘的使用情况。
1、匹配 passwd 中包含 root 关键字的行 awk '/root/' passwd
2、截取 df -h 命令输出结果的第 2 行 df -h|awk 'NR==2'
3、截取 df -h 命令输出结果的第 2 列 df -h|awk '{print $2}'
4、截取 df -h 命令输出结果的第 2 列和第 3 列 df -h|awk '{print $2,$3}'
5、截取 df -h 命令输出结果包含 sda3 关键字所在行的第 2 列 df -h|awk '/sda3/ {print $2}'
6、以指定格式显示 date 命令的年和月份 date|awk '{print "Year:" $6 "\tMonth:"$2}' \t:制表符,为 8 个字符宽度 \n:制表符,换行
7、截取 df -h 命令输出结果中包含 sda3 关键字的行并显示行号 df -h|awk '/sda3/ {print NR,$0}' $0 表示一整行数据。
8、匹配 df -h 命令输出结果中第一列包含关键字 sda3 的行 df -h|awk '$1 ~ /sda3/'
9、匹配 df -h 命令输出结果中第一列不包含关键字 sda3 的行 df -h|awk '$1 !~ /sda3/'
10、指定分隔符为:截取 passwd 文件中的第 2 列 awk -F ":" '{print $2}' passwd
paste工具
paste工具用于合并文件行
-d:自定义间隔符,默认是tab -s:串行处理,非并行



tee工具
tee工具从标准输入读取并写入标准输出和文件,即:双向覆盖重定向<屏幕输出|文本输入>
-a 双向追加重定向



 浙公网安备 33010602011771号
浙公网安备 33010602011771号