
python 加密算法及其相关模块的学习(hashlib,RSA,random,string,math)
加密算法介绍
一,HASH
Hash,一般翻译做“散列”,也有直接音译为”哈希”的,就是把任意长度的输入(又叫做预映射,pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
摘要算法又称为哈希算法,它是通过一个函数,把任意长度的数据转换为一个长度固定的数据串,这个数据串使用的十六进制表示。摘要算法是一个单向函数,计算容易,如果想要反推摘要算法那是非常喜困难的,而且 如果对原数据做了一个bit的修改,都会导致计算出的摘要完全不同,我们经常使用摘要对比数据是否被修改过和密码的加密;
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,他把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值.也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系
二,MD5
2.1 什么是MD5算法
MD5讯息摘要演算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码杂凑函数,可以产生出一个128位的散列值(hash value),用于确保信息传输完整一致。MD5的前身有MD2、MD3和MD4。
2.2 MD5功能
输入任意长度的信息,经过处理,输出为128位的信息(数字指纹);
不同的输入得到的不同的结果(唯一性);
2.3 MD5算法的特点
- 压缩性:任意长度的数据,算出的MD5值的长度都是固定的
- 容易计算:从原数据计算出MD5值很容易
- 抗修改性:对原数据进行任何改动,修改一个字节生成的MD5值区别也会很大
- 强抗碰撞:已知原数据和MD5,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
2.4 MD5算法是否可逆?
MD5不可逆的原因是其是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
2.5 MD5用途
-
防止被篡改:
-
比如发送一个电子文档,发送前,我先得到MD5的输出结果a。然后在对方收到电子文档后,对方也得到一个MD5的输出结果b。如果a与b一样就代表中途未被篡改。
-
比如我提供文件下载,为了防止不法分子在安装程序中添加木马,我可以在网站上公布由安装文件得到的MD5输出结果。
-
SVN在检测文件是否在CheckOut后被修改过,也是用到了MD5.
-
-
防止直接看到明文:
- 现在很多网站在数据库存储用户的密码的时候都是存储用户密码的MD5值。这样就算不法分子得到数据库的用户密码的MD5值,也无法知道用户的密码。(比如在UNIX系统中用户的密码就是以MD5(或其它类似的算法)经加密后存储在文件系统中。当用户登录的时候,系统把用户输入的密码计算成MD5值,然后再去和保存在文件系统中的MD5值进行比较,进而确定输入的密码是否正确。通过这样的步骤,系统在并不知道用户密码的明码的情况下就可以确定用户登录系统的合法性。这不但可以避免用户的密码被具有系统管理员权限的用户知道,而且还在一定程度上增加了密码被破解的难度。)
-
防止抵赖(数字签名):
- 这需要一个第三方认证机构。例如A写了一个文件,认证机构对此文件用MD5算法产生摘要信息并做好记录。若以后A说这文件不是他写的,权威机构只需对此文件重新产生摘要信息,然后跟记录在册的摘要信息进行比对,相同的话,就证明是A写的了。这就是所谓的“数字签名”。
三,SHA-1
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。
SHA是美国国家安全局设计的,由美国国家标准和技术研究院发布的一系列密码散列函数。
由于MD5和SHA-1于2005年被山东大学的教授王小云破解了,科学家们又推出了SHA224, SHA256, SHA384, SHA512,当然位数越长,破解难度越大,但同时生成加密的消息摘要所耗时间也更长。目前最流行的是加密算法是SHA-256 .
四,MD5与SHA-1的比较
由于MD5与SHA-1均是从MD4发展而来,它们的结构和强度等特性有很多相似之处,SHA-1与MD5的最大区别在于其摘要比MD5摘要长32 比特。对于强行攻击,产生任何一个报文使之摘要等于给定报文摘要的难度:MD5是2128数量级的操作,SHA-1是2160数量级的操作。产生具有相同摘要的两个报文的难度:MD5是264是数量级的操作,SHA-1 是280数量级的操作。因而,SHA-1对强行攻击的强度更大。但由于SHA-1的循环步骤比MD5多80:64且要处理的缓存大160比特:128比特,SHA-1的运行速度比MD5慢。
五,使用MD5进行密码机密
我们日常生活中在各大网站上注册时填写的密码大部分都是使用MD5的方式储存在数据库中,还有一部分使用的是sha的方式,但是会有好多朋友在注册时填写的密码过于简单,简单的密码即便使用MD5方式加密了,黑客还可以事先计算出这些常用口令的MD5值,得到一个反推表,现在在网上随便搜索一下就可以看到MD5在线解密,这种网站都是事先将这些常用的口令使用MD5计算一下放在一个库中,我们将这种情况称之为‘撞库’;

由于常用口令很容易被黑客计算出来,这时又出现了一种方法来避免被反推出来,这个方法就是俗称的“加盐”,就是在你加密时在前面添加一个固定的字符串;
#!/usr/bin/python
# -*- encodeing:utf-8 -*-
import hashlib
md5 = hashlib.md5('盐'.encode('utf-8'))
md5.update(b'123.com')
print(md5.hexdigest())
#cbff36039c3d0212b3e34c23dcde1456
#69c974abecb370564b051094c820fc6a
#此时得到的加密值与之前的比是不一样的
还有一种更难破解的方式就是动态加盐
#!/usr/bin/python
# -*- encodeing:utf-8 -*-
import hashlib
usr = 'Fang'
md5 = hashlib.md5(usr[0:2].encode('utf-8')+ '盐'.encode('utf-8'))
# 这种方法就是取用户名的前两个字符 再加上 一个固定的字符,然后在加上密码
md5.update(b'123.com')
print(md5.hexdigest())
六,RSA加密算法
6.1,RSA 加密算法定义
RSA加密算法是一种非对称加密算法。在公开密钥加密和电子商业中RSA被广泛使用。RSA是1977年由罗纳德·李维斯特(Ron Rivest)、阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(Leonard Adleman)一起提出的。当时他们三人都在麻省理工学院工作。RSA就是他们三人姓氏开头字母拼在一起组成的。
6.2,RAS密码加密与解密
我们常用的密码在密码学中叫做口令。在传统密码:加密算法是秘密的。在现代密码系统中:加密算法是公开的,秘钥是秘密的。
而现代密码系统分为对称加密和非对称加密。
那么RSA加密解密过程图解如下(来自百度百科):
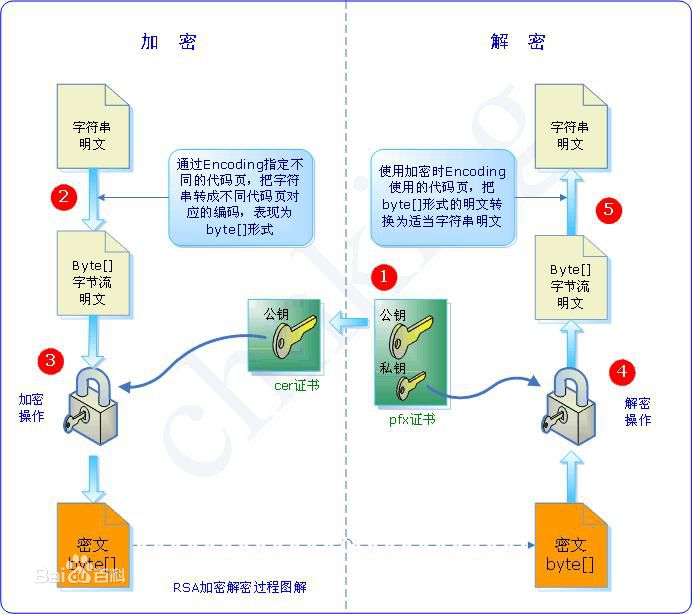
RAS非对称加密系统中。公钥是用来加密的(是公开的),私钥是用来解密的(是私有的)。举个例子:

那它通常先生存一对RSA秘钥,其中之一是保密秘钥,由用户保存;另外一个是公开密钥,可对外公开,甚至可在网络服务器上注册。为了提高保密强度,RSA密钥至少为500位长,一般推荐使用1024位。这就使加密的计算量很大。为减少计算量,在传送信息时,常用传统加密方法与公开密钥加密方法相结合的方法。即信息采用改进的DES或IDEA密钥加密,然后使用RSA密钥加密对话密钥和信息摘要。对方收到信息后,用不同的密钥解密并可核对信息摘要。
RSA算法是第一个能同时用于加密和数字签名的算法,也易于理解和操作。RSA是被研究得最广泛的公钥算法,从提出到现在至今的三十多年里,经历了各种攻击的考验,逐渐为人们接受,截止2017年被普遍认为是最优秀的公钥方案之一。
6.3,RSA加密算法过程
- 1,随机选取两个质数 p 和 q
- 2,计算 n=pq
- 3,选取一个与 Ø(n) 互质的小奇数 e, Ø(n) =(p-1)(q-1)
- 4,对模 Ø(n) ,计算e的乘法逆元d,即满足 (e*d) mod Ø(n) = 1
- 5,公钥(e, n), 私钥(d, n)
详细解析如下:
RSA中的公钥和私钥需要结合在一起工作。公钥用来对数据块加密,之后 ,只有对应的私钥才能用来解密。生成密钥时,需要遵循几个步骤以确保公钥和私钥的这种关系能够正常工作。这些步骤也确保没有实际方法能够从一个密钥推出另一个。
开始前,首先要选择两个大的素数,记为p和q。根据当今求解大数因子的技术水平,这两个数应该至少有200位,这们在实践中才可以认为是安全的。
然后,开始计算n:
n = pq
接下来,选择一个小的奇数e,它将成为公钥的一部分。选择e最需要考虑的重点是它与(p-1)(q-1)不能有相同的因子。换句话说,e与(p-1)(q-1)是互为素数关系的。比如,如果p=11而q=19,那么n=11 X 19=209。这里选择e=17,因为(p-1)(q-1)=10 X 18 =180,而17和180没有相同的因子。通常选择3、17、65、537作为e的值。使用这些值不会对RSA的安全性造成影响,因为解密数据还需要用到私钥。
一旦为e选择了一个值,接下来开始计算相对应的值d,d将成为私钥的一部分。d的值就是计算e的倒数对(p-1)(q-1)的取模结果,公式如下:
d = e-1 mod (p-1)(q-1)
这里d和e是模乘法逆元的关系。
思考一下这个问题:当d为多少时可以满足ed mod (p-1)(q-1) = 1 ?比如在等式 17d mod 180 = 1中,d的一个可能值是53。其他的可能值是233、413、593等。在实践中,可以利用欧几里德算法来计算模乘法逆元。这里就不再展开。
现在有了e和d的值,将(e,n)作为公钥P,将(d,n)作为私钥S并保持其不可见。表示为:
P = (e,n) , S = (d,n)
加密方使用P来加密数据,解密方使用S来解密。为了防止就算有人知道了P也无法推算出S,必须保证p和q的值绝对不能暴露。
P和S结合在一起提供的安全性来自于一个事实,那就是乘法是一种很好的单向函数。
单向函数是加密技术的基础。简单的说,单向函数就是在一个方向上能够很容易算出结果,但反向推导则是不切实际的。比如,在RSA算法中,计算p和q的成绩是一种单向函数,因为尽管计算p和q的成绩很容易,但将n反向因子分解为p和q则是极其耗时的。这里,选择的p和q的值要足够大才可以。
计算P和S的步骤起源于欧拉函数中的一些有趣性质。特别是,这些性质允许对模幂运算做一些有用的操作。
欧拉函数记为φ(n),定义所有小于n的正整数里和n互素的整数的个数。
只有当两个整数的唯一公因子为1时,才说这两个整数是互素的。例如,φ(8)=4,因为一共只用4个比8小的整数是互素的,它们是1,3,5,7。
欧拉方程有两个性质对RSA算法来说是特别重要的。
第一,当n是素数时,φ(n)=n-1。这是由于n的唯一因子是1和n,因此,n与之前的所有n-1个正整数都是互素的。
另一个有趣的性质是对于任意小于n且与n互素的正整数a,都有aφ(n) mod n = 1。例如,14 mod 8 = 1, 34mod 8 = 1, 54 mod 8 = 1, 74 mod 8 = 1。对上述方程两边都乘以a,得到:
(a)(aφ(n) mod n)=a,或者aφ(n)+1 mod n = a
因此,可以得到15 mod 8 = 1, 35 mod 8 = 3, 55 mod 8 = 5, 75 mod 8 = 7。
调整之后得到的等式非常强大。因为对于某些等式c = me mod n,该等于可以让我们找出一个d的值,使得cdmod n = m。
这就是RSA算法中允许加密数据,之后再解密回原文的恒等式。可以按照如下方式表示:
cd mod n = (me)d mod n = med mod n = mφ(n)+1 mod n = m mod n
欧拉函数和指数间的关系保证了加密的任意数据都能够唯一地解密回来。为了找出d的值,解方程d = e-1 φ(n) +1。不巧的是,对于方程d = e-1φ(n)+1不一定总是有整数解。为了解决这种问题,转而计算d mod φ(n)的值。换句话说,d = (e-1 φ(n) + 1) mod φ(n),可以简化为:
d = e-1 mod φ(n)
我们可以得到这样的简化形式,因为(φ(n)+1) mod φ(n) = (φ(n)+1) - φ(n) = 1。可以用任意的正整数替代φ(n)来证明等式成立。注意这个方程式同之前计算密钥的过程中得出d的推导式之间的相似之处。这提供了一种通过e和n来计算d的方法。当然了,e和n是公开的,对于攻击者来说是事先可知的,因此就有人问,这难道不是给了攻击者相同的机会来计算出私钥吗?讨论到这里,是时候来探讨一下RSA算法安全性保障的由来了。
RSA算法的安全性保障来自一个重要的事实,那就是欧拉函数是乘法性质的。这意味着如果p和q是互素的,那么有φ(pq)=φ(p)φ(q)。因此,如果有两个素数p和q,且n=p*q,则φ(n)=(p-1)(q-1),而且最重要的是:
d = e-1 mod (p-1)(q-1)
因此,尽管攻击者可能知道了e和n的值,为了计算出d必须知道φ(n),而这又必须同时得到p和q的值才能办到。由于p和q是不可知的,因此攻击者只能计算n的因子,只要给出的p和q的值足够大,这就是一个相当耗费时间的过程。
6.4,加密和解密数据分组

要使用RSA算法对数据进行加密和解密,首先要确定分组的大小。为了实现这一步,必须确保该分组可以保存的最大数值要小于n的位数。比如,如果p和q都是200位数字的素数,则n的结果将小于400位。因而,所选择的分组所能保存的最大值应该要以是接近于400。在实践中,通常选择的位数都是比n小的2的整数次幂。比如,如果n是209,要选择的分组大小就是7位,因为27 = 128比209小,但28 = 256又大于209。
要从缓冲区M中加密第(i)组明文Mi ,使用公钥(e,n)来获取M的数值,对其求e次幂,然后再对n取模。这将产生一组密文Ci。对n的取模操作确保了Ci将和明文的分组大小保持一致。因而,要加密明文分组有:
Ci = Mie mod n
之前提到过,欧拉函数是采用幂模运算来加密数据的基础,根据欧拉函数及其推导式,能够将密文解密回原文。
要对缓冲区中C中的第(i)组密文进行解密,使用私钥(d,n)来获取Ci的数值部分,对其求d次幂,然后再对n取模。这将产生一组明文Mi。因此,要解密密文分组有:
Mi = Cid mod n
6.5,RSA加密算法代码实现
代码如下:
# 取两个质数 p = 53 q = 59 n = p * q # 3127 fai = (p - 1) * (q - 1) # fai = 3016 e = 3 # fai/3 = 1005.333 # 除不尽,这是质数 d = 2011 # d是唯一的(这个自己算) # 这里我们反推一下d是否正确 # (e * d) % fai = 1 # (e, n)组成公钥 # (d, n)组成私钥 # 加密和解密的过程 # c = (m**e)%n # m = (c**d)%n
6.6,为什么使用RSA加密算法呢?
为什么RSA加密算法破解不了,两个质数计算乘法很简单,但是打乱拆分为两个质数很难。没有一个算法可以破解,所以只能一个一个试,就是说大数拆分很难。
Python的 提供的相关模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
一,HASH模块
下面举例说明了SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5算法的运算:
#使用update生成MD5加密的值,注意update在pycharm中没有提示,需要自行手打
import hashlib
m = hashlib.md5()
print("m:",m)
# m: <md5 HASH object @ 0x00000224BA2D0378>
m1 = m.update(b"Hello")
print("m1:",m1)
print("m:",m)
# m1: None
# m: <md5 HASH object @ 0x00000224BA2D0378>
m2 = m.update(b"It's me")
print("m2:",m2)
print("m:",m)
# m2: None
# m: <md5 HASH object @ 0x00000224BA2D0378>
print(m.digest())
# b']\xde\xb4{/\x92Z\xd0\xbf$\x9cR\xe3Br\x8a'
m3 = m.update(b"It's been a long time since last time we ...")
print("m3:",m3)
print("m:",m)
# m3: None
# m: <md5 HASH object @ 0x00000224BA2D0378>
print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
# b'\xa0\xe9\x89E\x03\xcb\x9f\x1a\x14\xaa\x07?<\xae\xfa\xa5'
# 32
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass
def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass
import hashlib
######## md5 ########
res = hashlib.md5()
print("md5",res)
# md5 <md5 HASH object @ 0x00000203F6610378>
res1 = res.update(b'admin')
print("md5_update:",res1)
print("md5",res)
# md5_update: None
# md5 <md5 HASH object @ 0x00000203F6610378>
print(res.hexdigest())
# 21232f297a57a5a743894a0e4a801fc3
######## sha1 ########
hash = hashlib.sha1()
print("sha1",hash)
# sha1 <sha1 HASH object @ 0x0000024CA2840378>
hash1 = hash.update(b'admin')
print("hash1:",hash1)
print("hash:",hash)
# hash1: None
# hash: <sha1 HASH object @ 0x0000024CA2840378>
print(hash.hexdigest())
# d033e22ae348aeb5660fc2140aec35850c4da997
######## sha256 ########
hash = hashlib.sha256()
print("hash",hash)
# hash <sha256 HASH object @ 0x000001D462B20378>
hash1 = hash.update(b'admin')
print("sha256:",hash1)
print("hash:",hash)
# sha256: None
# hash: <sha256 HASH object @ 0x000001D462B20378>
print(hash.hexdigest())
# 8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
######## sha384 ########
hash = hashlib.sha384()
print("hash:",hash)
# hash: <sha384 HASH object @ 0x000001D82F940378>
hash1 =hash.update(b'admin')
print("sha384:",hash1)
print("hash:",hash)
# sha384: None
# hash: <sha384 HASH object @ 0x000001D82F940378>
print(hash.hexdigest())
# 9ca694a90285c034432c9550421b7b9dbd5c0f4b6673f05f6dbce58052ba20e4248041956ee8c9a2ec9f10290cdc0782
二,random模块
下面直接上代码,明白的快
import random
res1 = random.randrange(1,10) #返回1-10之间的一个随机数,不包括10
print(res1)
#4
res2 = random.randint(1,10) #返回1-10之间的一个随机数,包括10
print(res2)
#6
res3 = random.randrange(0, 100, 2) #随机选取0到100间的偶数
print(res3)
#12
res4 = random.random() #返回一个随机浮点数
print(res4)
# 0.31929002952597907
res5 = random.choice('abce3#$@1') #返回一个给定数据集合中的随机字符
print(res5)
# @
res6 = random.sample('abcdefghij',3) #从多个字符中选取特定数量的字符
print(res6)
# ['j', 'h', 'a']
程序中有很多地方需要用到随机字符,比如登录网站的随机验证码,通过random模块可以很容易生成随机字符串,举例如下:
#生成随机字符串 import string import random res = ''.join(random.sample(string.ascii_lowercase + string.digits, 6)) print(res) # 3l82uv #洗牌 num = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] res2 = random.shuffle(num) print(num) # [3, 9, 5, 8, 4, 6, 1, 0, 2, 7]
2.1 random.sample() 函数用法
Python中 random.sample()方法可以随机地从指定列表中提取出N个不同的元素,但是注意,实践中发现,当N的值比较大的时候,该方法执行速度很慢(np.random模块中的choice方法可以有效的提升随机提取的效率)。
def sample(self, population, k):
"""Chooses k unique random elements from a population sequence or set.
Returns a new list containing elements from the population while
leaving the original population unchanged. The resulting list is
in selection order so that all sub-slices will also be valid random
samples. This allows raffle winners (the sample) to be partitioned
into grand prize and second place winners (the subslices).
Members of the population need not be hashable or unique. If the
population contains repeats, then each occurrence is a possible
selection in the sample.
To choose a sample in a range of integers, use range as an argument.
This is especially fast and space efficient for sampling from a
large population: sample(range(10000000), 60)
"""
# Sampling without replacement entails tracking either potential
# selections (the pool) in a list or previous selections in a set.
# When the number of selections is small compared to the
# population, then tracking selections is efficient, requiring
# only a small set and an occasional reselection. For
# a larger number of selections, the pool tracking method is
# preferred since the list takes less space than the
# set and it doesn't suffer from frequent reselections.
if isinstance(population, _Set):
population = tuple(population)
if not isinstance(population, _Sequence):
raise TypeError("Population must be a sequence or set. For dicts, use list(d).")
randbelow = self._randbelow
n = len(population)
if not 0 <= k <= n:
raise ValueError("Sample larger than population or is negative")
result = [None] * k
setsize = 21 # size of a small set minus size of an empty list
if k > 5:
setsize += 4 ** _ceil(_log(k * 3, 4)) # table size for big sets
if n <= setsize:
# An n-length list is smaller than a k-length set
pool = list(population)
for i in range(k): # invariant: non-selected at [0,n-i)
j = randbelow(n-i)
result[i] = pool[j]
pool[j] = pool[n-i-1] # move non-selected item into vacancy
else:
selected = set()
selected_add = selected.add
for i in range(k):
j = randbelow(n)
while j in selected:
j = randbelow(n)
selected_add(j)
result[i] = population[j]
return result
举例如下:
import random # 下面是给定已经数据 lis = [0, 1, 2, 3, 4, 5, 6] # random.sample用法:用于截取列表的指定长度的随机数,但是不回改变列表本身的序列 rs = random.sample(lis, 2) print(rs) print(rs) print(lis) ''' [4, 2] [4, 2] [0, 1, 2, 3, 4, 5, 6] ''' # 下面是随机出一定长度数据的要求,在随机长度里面,随机截取5个元素,然后返回 rs2 = random.sample(range(0, 9), 4) print(rs2) print(rs2) print(list(range(0, 9))) ''' [4, 3, 6, 0] [4, 3, 6, 0] [0, 1, 2, 3, 4, 5, 6, 7, 8] '''
2.2 random.uniform() 函数用法
Python 中 uniform() 方法将随机生成下一个实数,它在[x, y] 范围内。
语法如下:
import random # 注意:uniform() 是不能直接访问的,需要导入 random 模块 # 然后通过random静态对象调用该方法 random.uniform(x, y)
参数:
- x——随机数的最小值,包含该值
- y——随机数的最大值,不包含该值
返回一个浮点数N,取值范围如果 x<y,则为 x<=N<y,如果 y<x,则 Y<=N<=x。
实例如下:
>>> import random >>> random.uniform(5, 10) 8.722077624880372 >>> random.uniform(10, 1) 6.761586919196004 >>>
三,string模块
string模块

ascii_letters 获取所有ascii码中字母字符的字符串(包含大写和小写) ascii_uppercase 获取所有ascii码中的大写英文字母 ascii_lowercase 获取所有ascii码中的小写英文字母 digits 获取所有的10进制数字字符 octdigits 获取所有的8进制数字字符 hexdigits 获取所有16进制的数字字符 printable 获取所有可以打印的字符 whitespace 获取所有空白字符 punctuation 获取所有的标点符号
练习题:写一个6位随机验证码,要求至少包括一个数字,一个小写字母,一个大写字母
# 写一个6位随机验证码程序(使用random模块), # 要求验证码中至少包含一个数字、一个小写字母、一个大写字母. import random import string # ascii_letters:获取所有ascii码中字母字符的字符串(包含大写和小写) # digits:获取所有的10进制数字字符 res = ''.join(random.sample(string.digits+string.ascii_letters,6)) # res = ''.join(random.sample(string.ascii_lowercase + string.digits, 6)) print(res)
四,math模块
在数学之中,除了加减乘除四则运算之外——还有其它更多的运算,比如乘方、开方、对数运算等等,要实现这些运算,需要用到 Python 中的一个模块:Math
模块(module)是 Python 中非常重要的东西,你可以把它理解为 Python 的扩展工具。换言之,Python 默认情况下提供了一些可用的东西,但是这些默认情况下提供的还远远不能满足编程实践的需要,于是就有人专门制作了另外一些工具。这些工具被称之为“模块”
任何一个 Pythoner 都可以编写模块,并且把这些模块放到网上供他人来使用。
当安装好 Python 之后,就有一些模块默认安装了,这个称之为“标准库”,“标准库”中的模块不需要安装,就可以直接使用。
如果没有纳入标准库的模块,需要安装之后才能使用。模块的安装方法,我特别推荐使用 pip 来安装。这里仅仅提一下,后面会专门进行讲述,性急的看官可以自己 google。
math模块是标准库里面的,所以不用安装,可以直接调用
# _*_ coding: utf-8 _*_
#导入模块
import math
#dir(module)是一个非常有用的指令,可以通过他来差任何模块所包含的工具
res = dir(math)
print(res)
# ['__doc__', '__loader__', '__name__', '__package__', '__spec__',
# 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil',
# 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1',
# 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd',
# 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma',
# 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians',
# 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
'''
上面列举了math的所有方法,如果不会使用,
请输入help(math.方法名)
'''
# help(math.pow)
# Help on built - in function pow in module math:
#
# pow(...)
# pow(x, y)
#
# Return x ** y(x to the power of y).
print(math.pi)
# 3.141592653589793

 浙公网安备 33010602011771号
浙公网安备 33010602011771号