
预测学习、深度生成式模型、DcGAN、应用案例、相关paper
我对GAN“生成对抗网络”(Generative Adversarial Networks)的看法:
前几天在公开课听了新加坡国立大学【机器学习与视觉实验室】负责人冯佳时博士在【硬创公开课】的GAN分享。GAN现在对于无监督图像标注来说是个神器。
Deep? 生成模型GAN就是一种在拟合一张图像数组分布的一种模型,是概率统计结合深度学习之后的一次升级。
GAN是概率统计到深度学习世界“秀”存在
生成模型分为两个部分:生成模型+判别模型。生成模型学习联合概率分布p(x,y),而判别模型学习条件概率分布p(y|x)。
他们之间对抗均衡的过程,就相当于统计中的蒙特卡洛拟合最佳分布的过程。
分布公式的重要性:分布公式之后,那么可以造无数个这样的分布。
一、运行机制
相关GAN论文汇总,包含code:https://github.com/zhangqianhui/AdversarialNetsPapers
1、生成模型
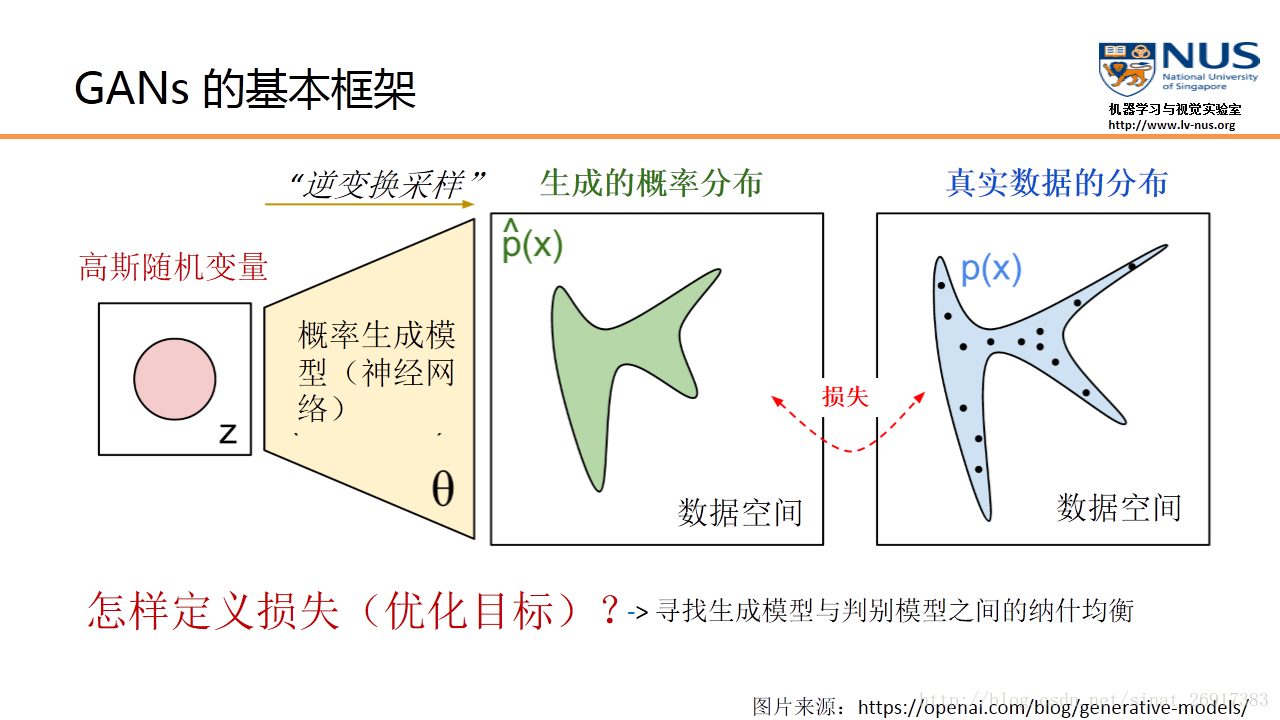
一个最朴素的GAN模型,实际上是将一个随机变量(可以是高斯分布,或0到1之间的均匀分布),通过参数化的概率生成模型(通常是用一个神经网络模型来进行参数化),进行概率分布的逆变换采样,从而得到一个生成的概率分布(图中绿色的分布模型)。其训练目标,就是要最小化判别模型D的判别准确率。
生成模型就是一种寻找分布最优参数的过程,而这些参数更新不是来自于数据样本本身(不是对数据的似然性进行优化),而是来自于判别模型D的一个反传梯度
通过优化目标,使得我们可以调节概率生成模型的参数\theta,从而使得生成的概率分布和真实数据分布尽量接近。
但是这里的分布参数不再跟传统概率统计一样了,这些参数保存在一个黑盒中:最后所学到的一个数据分布Pg(G),没有显示的表达式。它只是一个黑盒子一样的映射函数:输入是一个随机变量,输出是我们想要的一个数据分布。
让我们回顾一下正态概率密度函数:
正态随机变量服从的分布就称为正态分布,记作 ,读作X服从正态分布
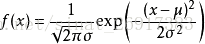
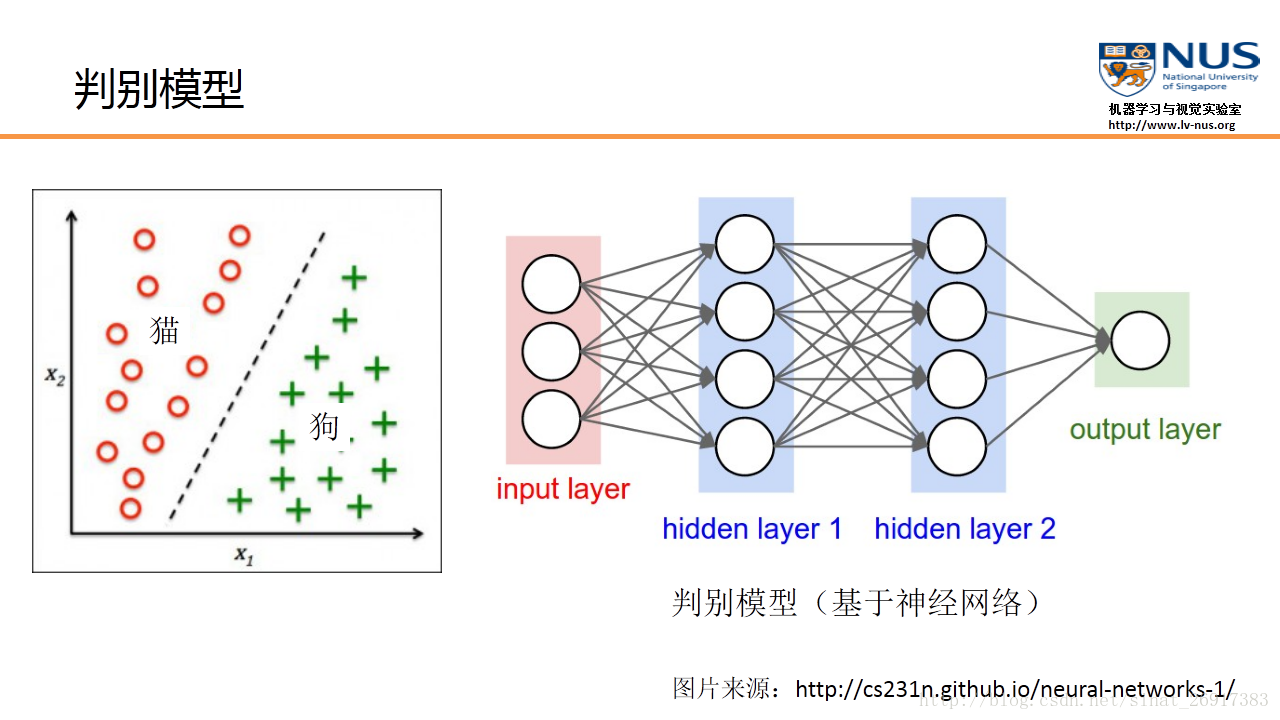
2、判别模型
判别模型D的训练目的就是要尽量最大化自己的判别准确率。当这个数据被判别为来自于真实数据时,标注 1,自于生成数据时,标注 0。
GAN创新性地引入了一个判别模型(常用的有支持向量机和多层神经网络)。它的优化过程就是在寻找生成模型和判别模型之间的一个纳什均衡。
(注:所有的理论都认为 GAN应该在纳什均衡(Nash equilibrium)上有卓越的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。当博弈双方都由神经网络表示时,在没有实际达到均衡的情况下,让它们永远保持对自己策略的调整是可能的。???答案是不可能的!!!)
3、目标函数——生成模型和判别模型的均衡
如果我们把生成模型比作是一个伪装者的话,那么判别模型就是一个警察的角色。伪装者的目的,就是通过不断的学习来提高自己的伪装能力,从而使得自己提供的数据能够更好地欺骗这个判别模型。而判别模型则是通过不断的训练来提高自己判别的能力,能够更准确地判断数据来源究竟是哪里。
在训练过程中,GAN采用了一种非常直接的交替优化方式,它可以分为两个阶段:
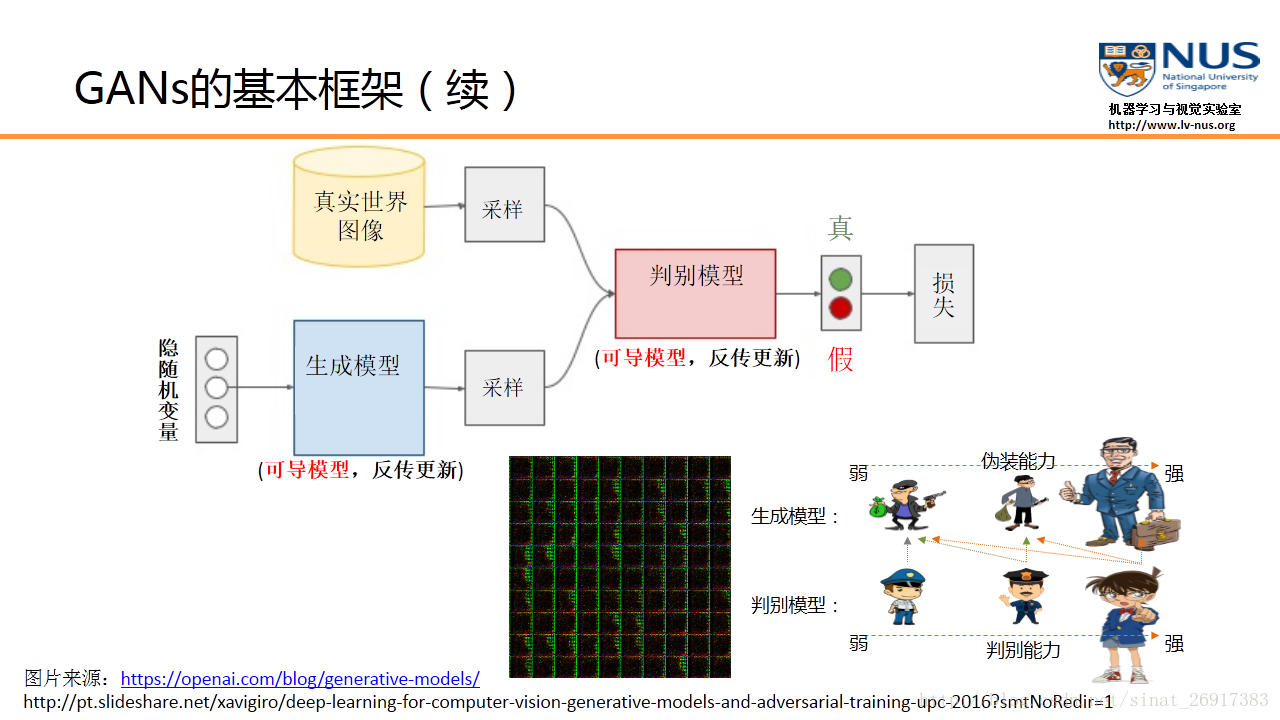
- 第一个阶段:固定判别模型D,然后优化生成模型G,使得判别模型的准确率尽量降低。
- 第二个阶段:固定生成模型G,来提高判别模型的准确率。
图(a)中黑色大点虚线P(x)是真实的数据分布,绿线G(z)是通过生成模型产生的数据分布(输入是均匀分布变量z,输出是绿色的曲线)。蓝色的小点虚线D(x)代表判别函数。
在图(a)中,我们可以看到,绿线G(z)分布和黑色P(x)真实分布,还有比较大的差异。这点也反映在蓝色的判别函数上,判别函数能够准确的对左面的真实数据输入,输出比较大的值。对右面虚假数据,产生比较小的值。但是随着训练次数的增加,图(b)和图(c)反映出,绿色的分布在逐渐靠近黑色的分布。到图(d),产生的绿色分布和真实数据分布已经完全重合。这时,判别函数对所有的数据(无论真实的还是生成的数据),输出都是一样的值,已经不能正确进行分类。G成功学习到了数据分布,这样就达到了GAN的训练和学习目的。
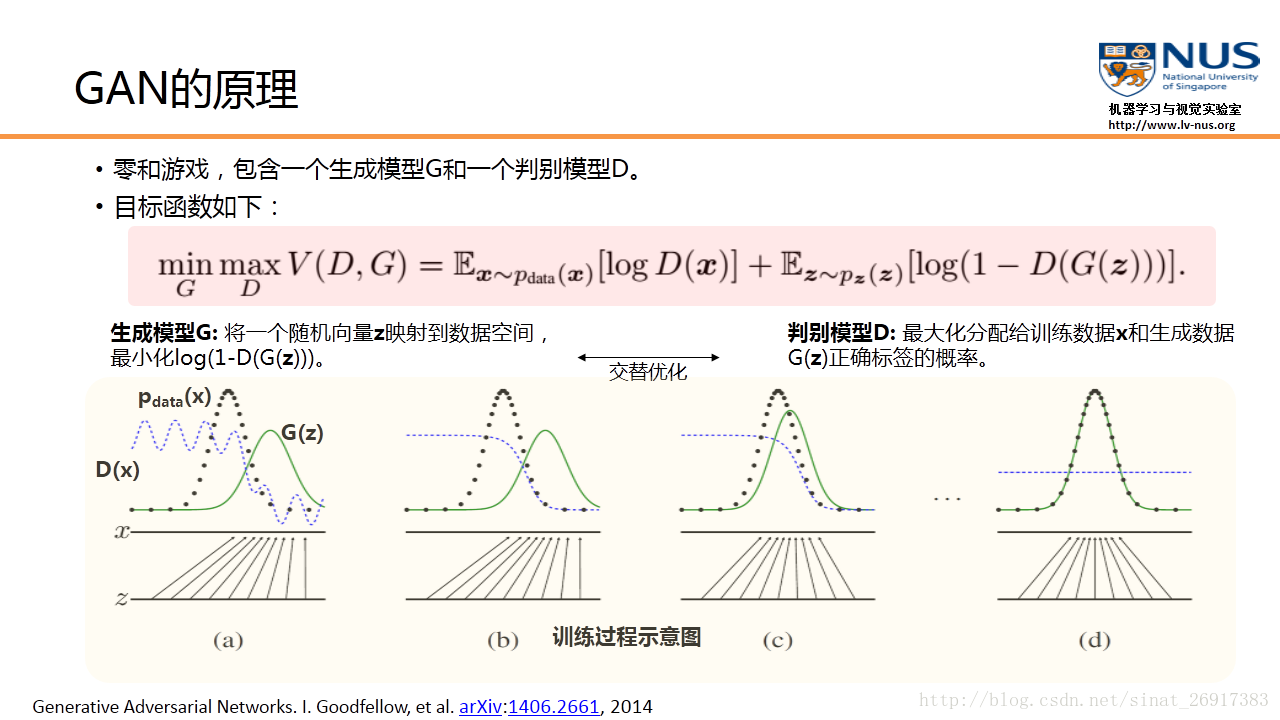
4、GAN的全局最优解和收敛性
- GAN是存在全局最优解的。这个全局最优解可以通过一些简单的分析得到。首先,如果固定G,那么D的最优解就是一个贝叶斯分类器。将这个最优解形式带入,可以得到关于G的优化函数。简单的计算可以证明,当产生的数据分布与真实数据分布完全一致时,这个优化函数达到全局最小值。
- 另外一点,是关于GAN的收敛性。如果G和D的学习能力足够强,两个模型可以收敛。但在实际中,GAN的优化还存在诸如不稳定等一些问题。如何平衡两个模型在训练中是一个很重要的问题。
二、GAN变种模型之间的继承关系
本节内容来源于pperWeekly公众号的《PaperWeekly 第二十期 — GAN(Generative Adversarial Nets)研究进展》
.
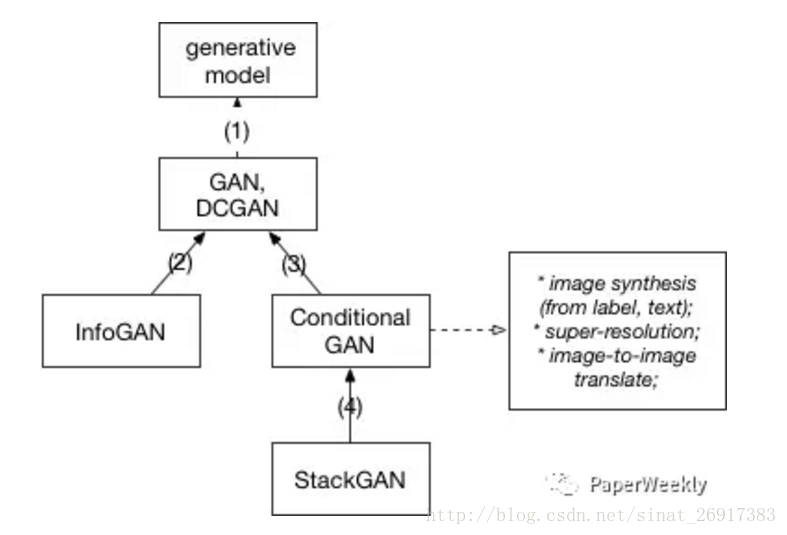
1、DCGAN
Ian J. Goodfellow等人的文章提出了GAN的模型和训练框架,但是没有描述具体的实现,而DCGAN[2] 这篇文章讲的就是用deep convolutional network实现一个生成图片的GAN模型。描述了很多实现上细节,尤其是让GAN模型stable的方法。
DCGAN的原理和GAN是一样的,这里就不在赘述。它只是把上述的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
1. 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
2. 在D和G中均使用batch normalization;
3. 去掉FC层,使网络变为全卷积网络;
4. G网络中使用ReLU作为激活函数,最后一层使用tanh;
5. D网络中使用LeakyReLU作为激活函数;
DCGAN中的G网络示意:

其中在TF中的一个漫画头像案例:
从动漫图库网站爬取漫画图片、头像截取,使用github上一个基于opencv的工具:nagadomi、fine-tuning(carpedm20/DCGAN)
整个案例来源于雷锋网网址:http://www.leiphone.com/news/201701/yZvIqK8VbxoYejLl.html
. 关于这篇论文《Unsupervised representation learning with deep convolutional generative adversarial networks》Radford A, Metz L, Chintala S. [J]. arXiv preprint arXiv:1511.06434, 2015.
( 注:以下来自于:GANs之DCGANs 。这篇论文的提出看似并没有很大创新,但其实它的开源代码现在被使用和借鉴的频率最高。这一切必须归功于这篇工作中比 LAPGAN [2-Denton E L, Chintala S, Fergus R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks[C]//Advances in neural information processing systems. 2015: 1486-1494.] 更 robust 的工程经验分享。也就是说,DCGAN,Deep Convolutional Generative Adversarial Networks,这个工作[1],指出了许多对于GAN这种不稳定学习方式重要的架构设计和针对CNN这种网络的特定经验。重点来看:
比如他们提出既然之前已经被提出的strided convolutional networks 可以从理论上实现和有pooling的 CNN一样的功能和效果,那么strided convolutional networks作为一个可以 fully differentiable的generator G,在GAN中会表现得更加可控和稳定。
又比如,本来 Facebook的LAPGAN中指出Batch Normalization(BN)被用在 GAN 中的D上会导致整个学习的collapse ,但是DCGAN中则成功将 BN 用在了 G 和 D 上。这些工程性的突破无疑是更多人选择DCGAN 这一工作作为 base 的重要原因。
另一方面,他们在 visualize generative models 也有许多贡献。比如他们学习了 ICLR 2016 论文《Generating Sentences From a Continuous Space》中的 interpolate space 的方式,将生成图片中的 hidden states 都 show 了出来,可以看出图像逐渐演变的过程。
...................................................
通过GAN构建表征,然后重用部分生成模型、判别模型作为有监督学习的特征提取器。 GAN是“最大似然方法”的一个有吸引力的替代方法。 对于表征学习,无需启发式损失函数是有吸引力的。GAN有一个通病:训练过程的unstable : 经常导致生成器产出无意义的输出。目前在试图理解和可视化GANs学到什么以及多层GANs的中间层标准方面研究非常有限。
文章主要贡献:
- 提出和评估了一系列卷积GANs在结构拓扑方面约束条件,让其更加稳定。我们将其命名为深度卷积生成式对抗网络Deep Convolutional GANs
- 使用训练好的判别模型用于图像分类,和其他无监督方法的结果具有可比较性。
- 可视化了卷积核
- 生成模型具有向量算是运算性能 )
2、InfoGAN
为了使输入包含可以解释,更有信息的意义,InfoGAN[7]的模型在z之外,又增加了一个输入c,称之为隐含输入(latent code),然后通过约束c与生成数据之间的关系,使得c里面可以包含某些语义特征(semantic feature),比如对MNIST数据,c可以是digit(0-9),倾斜度,笔画厚度等。具体做法是:首先我们确定需要表达几个特征以及这些特征的数据类型,比如是类别(categorical)还是连续数值,对每个特征我们用一个维度表示ci 。
.
3、Conditional GAN
conditional的意思就是,生成图片的模型变成了 P(X|z, c),而c是我们额外提供的信息。与info区别:(1)Info中c信息是需要网络去学习提取的特征,而这里是需要我们输入网络的信息。 (2)Info中c只输入生成网络,而这里需要同时输入生成和识别网络,以便让网络学习到它们之间的关联。
. ( 注: 与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。为了解决GAN太过自由这个问题,一个很自然的想法是给GAN加一些约束,于是便有了Conditional Generative Adversarial Nets(CGAN)【Mirza M, Osindero S. Conditional】。这项工作提出了一种带条件约束的GAN,在生成模型(D)和判别模型(G)的建模中均引入条件变量y(conditional variable y),使用额外信息y对模型增加条件,可以指导数据生成过程。这些条件变量y可以基于多种信息,例如类别标签,用于图像修复的部分数据[2],来自不同模态(modality)的数据。如果条件变量y是类别标签,可以看做CGAN 是把纯无监督的 GAN 变成有监督的模型的一种改进。来自于:GANs学习系列6-条件GANs )
4、StackGAN
StackGAN[8] 模型本质就是是Conditional GAN,只不过它使用了两层conditional GAN模型,第一层模型 P(X1|z, c) 利用输入的文字信息c生成一个较低分辨率的图片。之后第二层模型 P(X|c,,X1) 基于第一层生成的图片以及文字信息生成更加优化的图片。
最新NIPS2016也有最新的关于训练GAN模型的总结 [How to Train a GAN? Tips and tricks to make GANs work] (https://github.com/soumith/ganhacks “GAN tricks”)。
.
5、iGAN:Interactive Image Generation via Generative Adversarial Networks
github地址:https://github.com/junyanz/iGAN
效果:划一个弧线,然后就可以模拟出山体等实景来。 这貌似是百度发表的一篇论文。
.
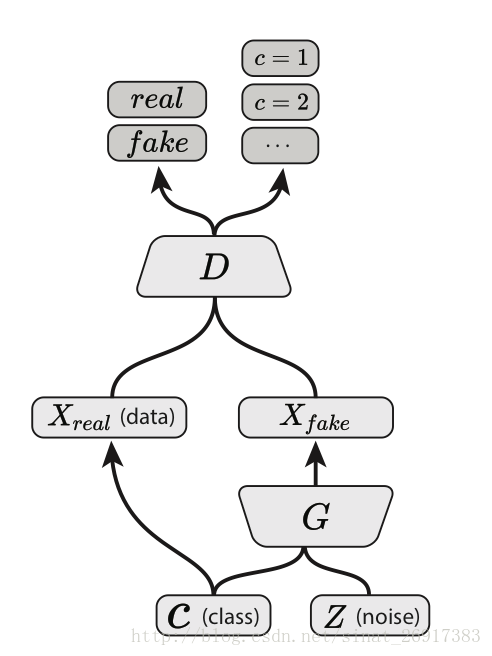
6、AC-GAN(auxiliary classifier GAN)
paper : https://arxiv.org/abs/1610.09585

AC-GAN的Discriminator中会输出相应的class label的概率,然后更改loss fuction,增加class预测正确的概率, ac-gan是一个tensorflow相关的实现,基于作者自己开发的sugartensor,感觉和paper里面在loss函数的定义上差异.
实验案例可参考:GAN的理解与TF的实现
6、 FAIR 提出常见 GAN 训练方法的替代方法:WGAN
本节内容来源于
1、机器之心翻译组
2、作者:郑华滨 来源:知乎 链接:https://zhuanlan.zhihu.com/p/25071913
论文的主要贡献:
而今天的主角Wasserstein GAN(下面简称WGAN)成功地做到了以下爆炸性的几点:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
- 基本解决了collapse mode的问题,确保了生成样本的多样性
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高
- 以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
而改进后相比原始GAN的算法实现流程却只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
WGAN 模型的 pytorch 代码实现
https://gist.github.com/soumith/71995cecc5b99cda38106ad64503cee3
论文链接:https://arxiv.org/pdf/1701.07875v1.pdf
其中WGAN发展迅猛,这几天讨论的人特别多,这里看一个案例《人脸数据集和mnist的案例》
对 keras : tensorflow https://github.com/zdx3578/DeepLearningImplementations/tree/master/WassersteinGAN
内容目录:
celebA人脸数据集训练效果
mnist 数字训练学习效果
环境搭建要点。
图片1
图片2
图片来源:【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
.
三、GAN在NLP应用的难点
来源于知乎《GAN在自然语言处理方面有哪些有趣的文章和应用?》
为什么Ian在reddit上说GAN做不了是因为word embedding加减无意义就做不了呢?既然这样,我在latent vector上做加减不就行了吗?这个方法看上去可以,实际上很难work。
使用generative model解决language generation最大的问题在于latent space存在非常多的desert hole。在training的时候,text的latent vector有聚拢的倾向。不过解决的方法也是有很多的。最简单的方法是用VAE而不是用GAN。GAN本身的训练方式是非常依赖连续空间的。在训练的时候,我们的目标就是连续空间上的pixel值。在这一点上,VAE就没有这个假设。因此VAE是自然的选择。另外一个方法是结合policy gradient,把它做成一个RL的问题。[2] 是一篇非常有意思的文章。通过把word选择由softmax output选择变成policy选择,作者巧妙的避开了GAN和word embedding不兼容的问题。
.
四、GAN的应用实例
因为内部对抗训练的机制,GAN可以解决一些传统的机器学习中所面临的数据不足的问题,因此可以应用在半监督学习、无监督学习、多视角、多任务学习的任务中。还有,就是最近有一些工作已经将进行成功应用在强化学习中,来提高强化学习的学习效率。
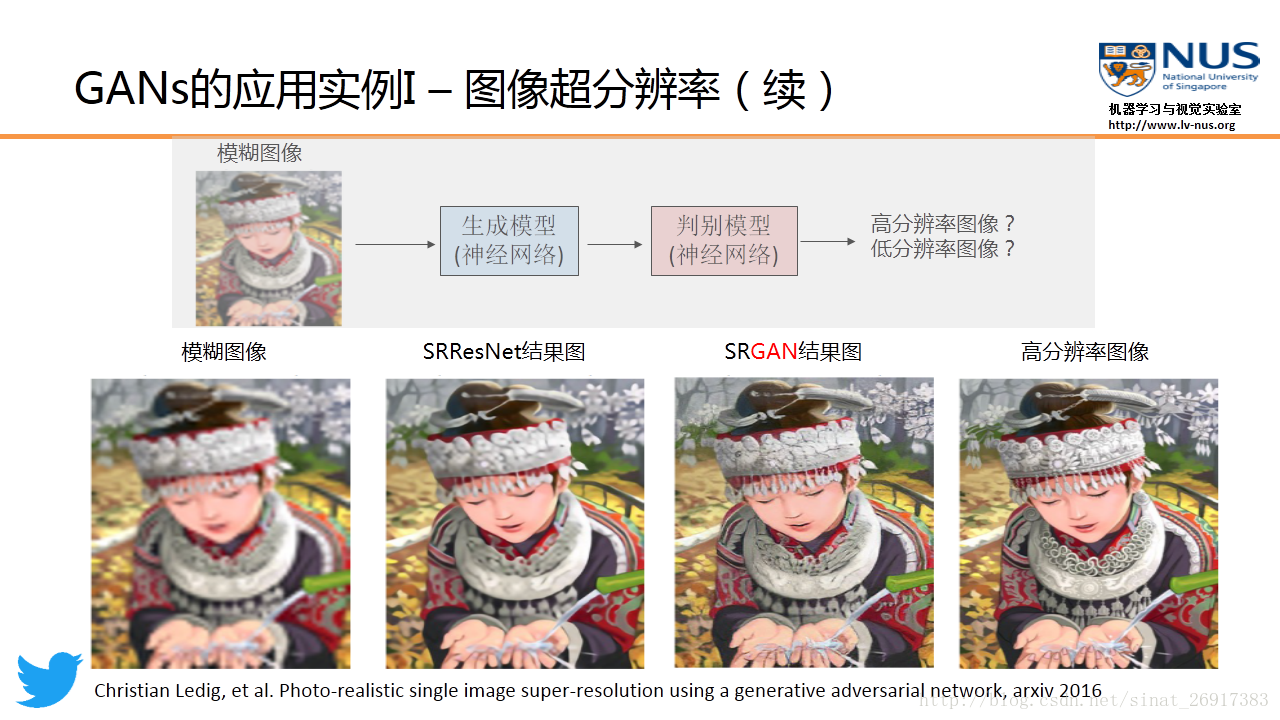
应用实例 1:图像超分辨率(Twitter)
Twitter 公司最近发表了一篇图像超分辨率的论文,就是应用了GAN模型。图像超分辨率的目的,是将一个低分辨率的模糊图像,进行某种变换,得到一个高分辨率的带有丰富细节的清晰图像。
在 Twitter 这篇论文中,他们用一个16个残差块的网络来参数化生成模型。而判别模型使用的是一个VGG网络。这个实验结果也说明了使用GAN模型能够得到更好的结果。与以往基于深度学习模型做图像超分辨率的结果相比的话(比如SRResNet等),我们可以看到GAN的结果图能够提供更丰富的细节。这也就是GAN做图像生成时的一个显著优点,即能够提供更锐利的数据细节。
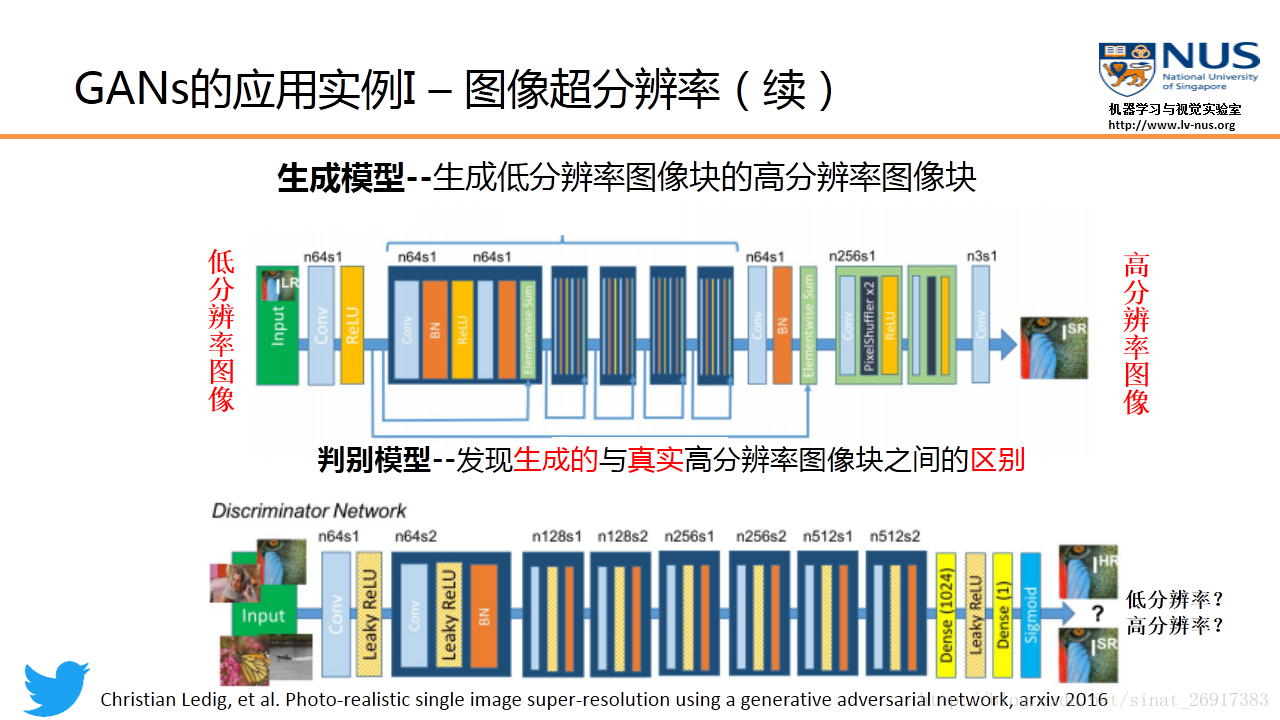
.
应用实例 2:数据合成(Apple)
Apple最近刚刚发表了其第一篇AI论文,论文要解决的问题,就是如何使得模拟的数据更加逼真,与真实图像的差异性尽量小。这篇论文中使用了类似GAN的框架,将模拟器(Simulator)产生的虚拟数据作为输入,通过一个叫做改进器(Refiner)的模型(对应生成模型)来产生改进后的虚拟数据。再同样的,使用一个判别器,来判断所产生的图像是真实的,还是虚拟的 。
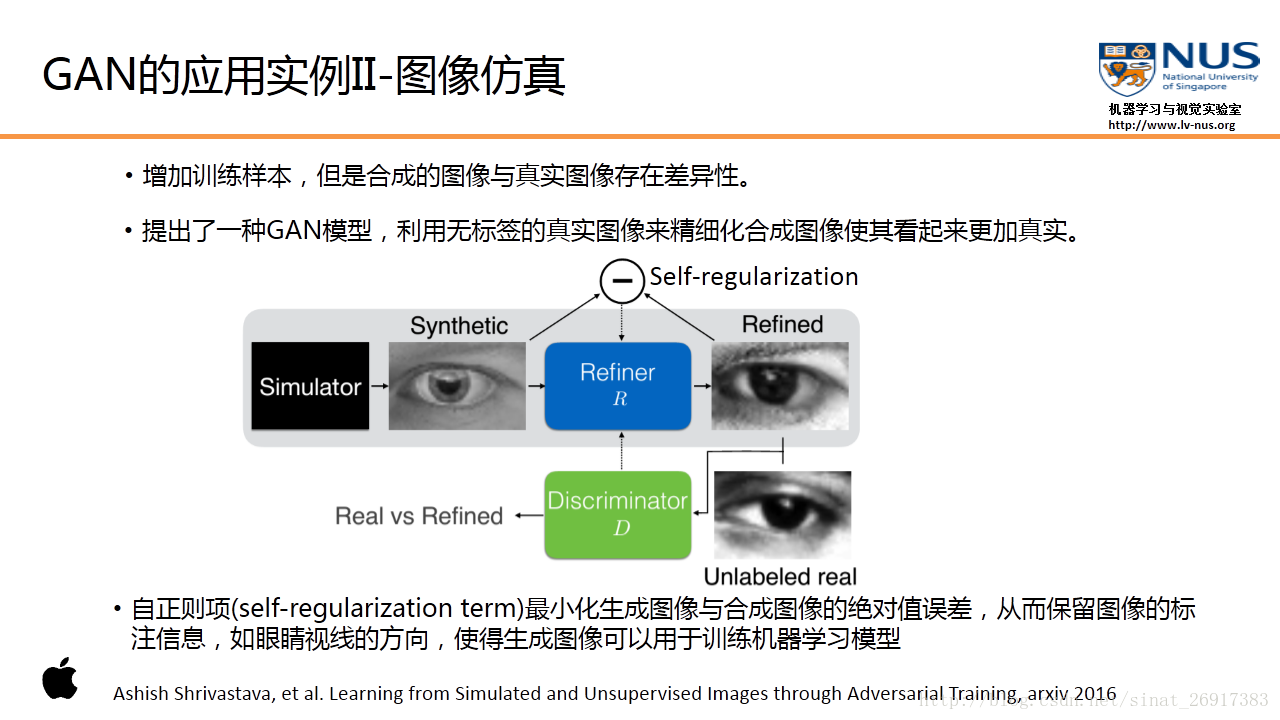
.
应用实例3:图像到图像的翻译+文本到图像的翻译
比如说将语义标注图、灰度图或边缘图作为GAN的输入,那么我们希望它输出能够和输入图一致的真实图像,例如这里的街景图和彩色图。
文本到图像的翻译。GAN的输入是一个描述图像内容的一句话,比如“一只有着粉色的胸和冠的小鸟”,那么所生成的图像内容要和这句话所描述的内容相匹配。

.
应用实例4:人脸去遮挡
新加坡国立大学【机器学习与视觉实验室】研究项目。保持人的身份信息的GAN模型,实验结果证明,这个模型不仅能够检测和去掉在人脸上的遮挡,同时还能保持人的身份信息,从而提高人脸的识别准确率。

.
应用实例5:小物体的检测
新加坡国立大学【机器学习与视觉实验室】研究项目。在小物体的检测上,例如在自动驾驶领域对交通标志进行检测。“感知GAN模型”(Perceptual GAN),应用在小物体特征表示的超分辨率上,而不是对原始图像进行超分辨率,使得小物体的特征表示和大物体的特征角表示尽量接近,这样我们就能够成功检测到小物体。我们将这个感知GAN模型应用在了交通标志检测上,取得了比较好的实验结果。

.
应用实例6 :基于CGAN的图像除雨方法(ID-CGAN)
《Image De-raining Using a Conditional Generative Adversarial Network》H Zhang, V Sindagi, V M. Patel [Rutgers University] (2017)
基于GANs,重设loss函数,来达到一定的除去雨滴的效果。

github链接:https://github.com/ruimashita/caffe-train
.
应用实例7 :太空:绘制宇宙历史中的引力透镜效应
在基础科学中,生成人工智能(Generative AI)看起来更有前途,Welling 说,他正在帮助开发 Square Kilometre Array (SKA),一座在南非和澳大利亚建立的射电天文台。SKA 将产生大量的数据,它的图像需要被压缩成低噪声但不完整的数据。生成人工智能模型将会帮助重构并填补这些数据的空白部分,产生天文学家能够进行实验的天空图像。
卡耐基梅隆大学的天体物理学家 Rachel Mandelbaum 带领的一只团队正在实验使用 GAN 和 VAE 模拟因引力透镜效应而看起来畸形的星系图像。研究人员打算研究大量的星系图像,来绘制宇宙历史中的引力透镜效应(gravitational lensing)。这能演示宇宙的物质如何随时间变化的分布,为研究导致宇宙爆炸的暗能量的性质提供线索。但为了做到这点,天文学家需要能够可靠地软件分离引力透镜与其他影响。Mandelbaum 说合成图像能够改进该项目的准确性。
许多科学家希望最新的人工智能神经网络能够帮助他们发现大型、复杂的数据集中的模式,但一些人对黑箱系统的解释难以信任,它内部的工作机制是神秘的。即使虚拟神经元看起来给出了正确的答案,它们可能对世界会有着错误的理解。Cranmer 说假如生成元素可能会有所帮助,「如果它能生成看起来真实的数据,那它就更具有说服力。无论黑箱是什么,它确实学到了物理性质。」
来源:机器之心编译 原文:http://www.nature.com/news/astronomers-explore-uses-for-ai-generated-images-1.21398
应用实例7 :基于CGAN的人脸图像老化预测
《Face Aging With Conditional Generative Adversarial Networks》 Grigory Antipov, Moez Baccouche, Jean-Luc Dugelay (Submitted on 7 Feb 2017 (v1), last revised 30 May 2017 (this version, v2))
论文地址:http://web.eecs.utk.edu/%7Ezzhang61/docs/papers/2017_CVPR_Age.pdf
文章用于生成不同年龄的图片,采用的模型是条件对抗网络, 主要创新点是, 首先通过一个网络,提取图像特征向量, 并通过身份保持网络, 优化图像的特征向量 ,特到特征向量z∗, 之后便可以对于每个输入年龄 , 查找其年龄向量,并将该年龄向量与输入图片特征向量z∗串联, 输入生成网络,生成目标年龄图片.
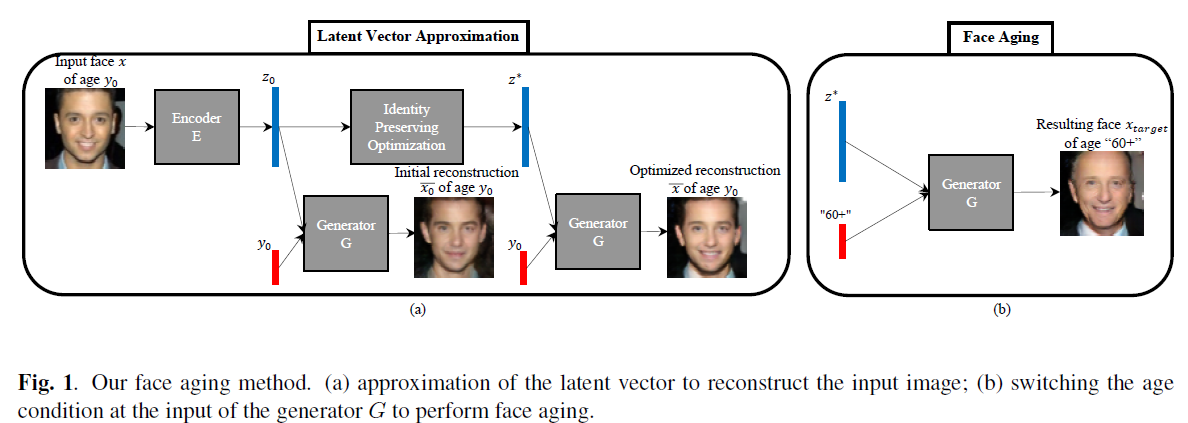
GANs结合自己的独特的判别式和生成式模型结合,产生一个约定条件下的预测模型,可使自身应用于预测学习的范畴。
完整翻译:基于条件GAN的人脸老化模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号