
数据模型:
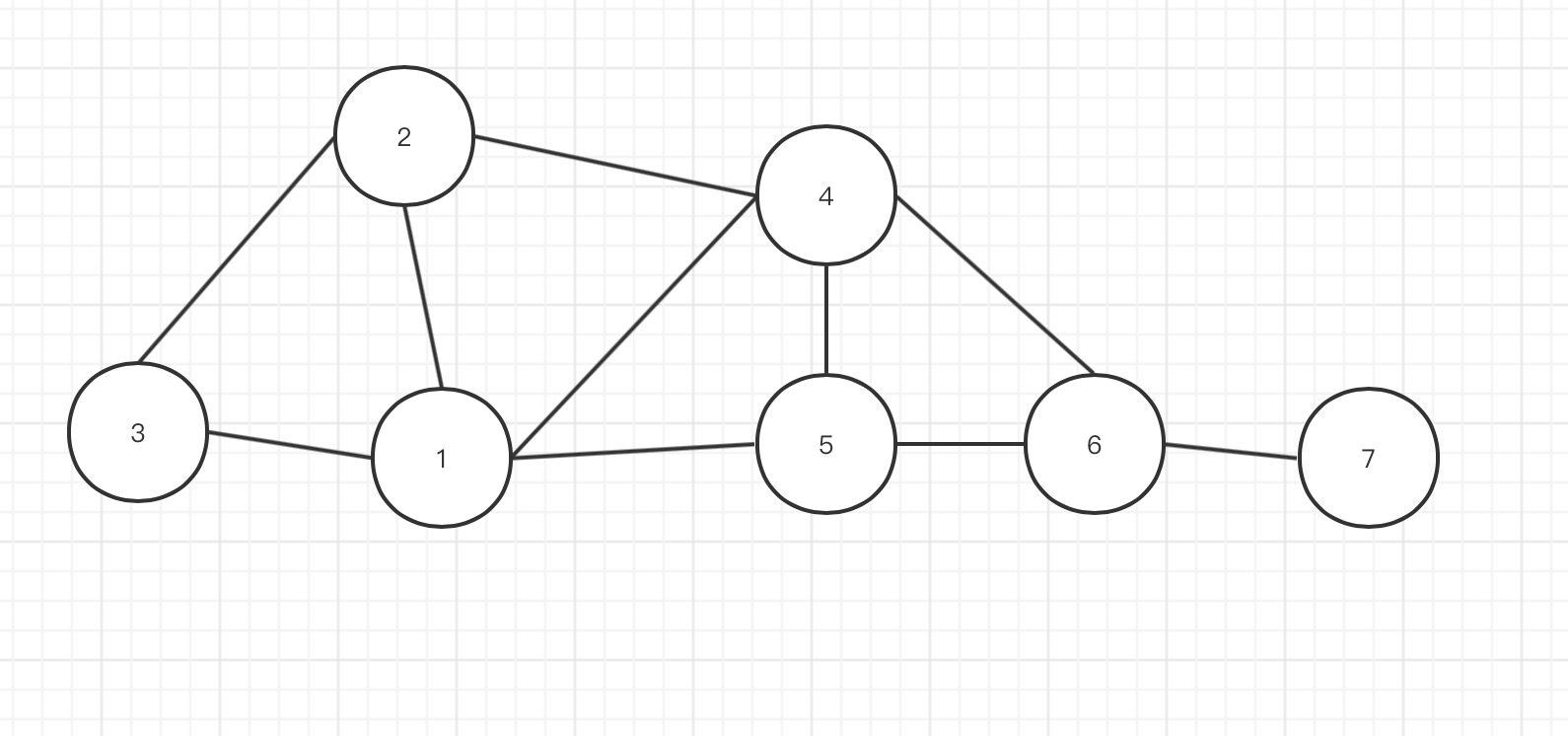
通过模型,得到好友关系:
1 2,3,4,5
2 1,3,4
3 1,2
4 1,2,5,6
5 1,4,6
6 4,5,7
7 6
实现好友推荐的思路:
1、罗列对象的直接好友关系,及对象好友之间的关系.即两两关系
1 2,3,4,5---->
((1,2),0)((1,3),0)((1,4),0)((1,5),0)((2,3),1)((2,4),1).....
2、直接关系权重为0,间接关系权重为1.并将两两关系对象排序,即不会出现(1,2) 和(2,1)的情况。
3、reduce阶段若两两关系存在权重为0的记录,或分组后权重和小于计数和,则说明此两两关系存在直接关系,不需要推荐。
4、对于留下的间接关系,权重和越大,则说明两两间的共同好友越多,即越值得推荐好友。
示例代码:
package com.msb.hadoop.fof; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class MyFof { public static void main(String[] args) throws Exception { //1、创建配置实例 Configuration conf = new Configuration(true); //2、设置参数 //3、创建job实例 Job job = Job.getInstance(conf, "MyFof"); //4、设置Job启动类 job.setJarByClass(MyFof.class); //5、添加输入路径 FileInputFormat.addInputPath(job,new Path("/fs/in")); //6、配置输出路径 FileOutputFormat.setOutputPath(job,new Path("/fs/out")); //7、设置map类 job.setMapperClass(FMapper.class); //8、设置output key类 job.setOutputKeyClass(Text.class); //9、设置output value类 job.setOutputValueClass(IntWritable.class); //10、设置reducer类 job.setReducerClass(FReducer.class); //11、运行job job.waitForCompletion(true); } } package com.msb.hadoop.fof; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.StringTokenizer; public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Text mk = new Text(); private IntWritable mv = new IntWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //value:1 2,3,4,5 StringTokenizer strs = new StringTokenizer(value.toString()); String[] s = value.toString().split(" "); String main = s[0]; String[] sps = s[1].split(","); for (int i = 0; i < sps.length; i++) { //输出有直接关系 mk.set(sortString(main,sps[i])); mv.set(0);//直接关系存储为0 context.write(mk, mv); //循环输出间接关系 for(int j = i+ 1; j < sps.length; j++){ mk.set(sortString(sps[i], sps[j])); mv.set(1);//间接关系存储为1 context.write(mk, mv); } } } private String sortString(String str1, String str2){ String res = null; if (str1.compareTo(str2) >= 0) {//主对象大于字对象,则反转 res = str2+","+str1; }else{ res = str1+","+str2; } return res; } } package com.msb.hadoop.fof; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; public class FReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private Text rk = new Text(); private IntWritable rv = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { Iterator<IntWritable> iter = values.iterator(); int sum = 0; int cnt = 0; while (iter.hasNext()) { IntWritable next = iter.next(); sum += next.get(); cnt += 1; } if (sum == cnt) {//若相等,则说明是间接 rk.set(key); rv.set(sum); context.write(rk, rv); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号