
Java基础—集合小结
Java的集合定义在java.util包中,主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue。常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等。

一、List
List是常用的集合类型,是有序的Collection,能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。
常用实现类:ArrayList、Vector、LinkedList。
1.1、ArrayList
基于数组实现,增删慢,查询快,线程不安全。
ArrayList是使用最广泛的List实现类,其内部数据结构基于数组实现,提供了对List的增加(add)、删除(remove)和访问(get)功能。
由于ArrayList底层是使用的数组实现,所以其元素是连续存储的。所以当需要在ArrayList的中间位置插入或者删除元素时,需要将该元素后的所有元素进行移动。
ArrayList的默认构造方法如下:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//内部使用一个空数组
}
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};//默认使用空数组
指定初始容量的构造方法:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;//也是个空数组
} else {
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
ArrayList的默认添加元素的方法如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!——判断是否需要扩容
elementData[size++] = e;//在当前最后一个元素之后添加
return true;
}
指定位置添加元素的方法:
public void add(int index, E element) {
rangeCheckForAdd(index);//检查下标是否越界
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1, size - index);//调用系统本地的数组复制方法
elementData[index] = element;
size++;
}
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
ArrayList的扩容方法:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);//取默认容量和当前插入索引的最大值
}
ensureExplicitCapacity(minCapacity);
}
private static final int DEFAULT_CAPACITY = 10;//默认容量为10
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)//当已经超出数组最大容量时,进行扩容
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//旧有容量
int newCapacity = oldCapacity + (oldCapacity >> 1);//扩展1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//复制数组
}
1.2、Vector
基于数组实现,增删慢,查询快,线程不安全。
Vector的结构和ArrayList一样,都是基于数组实现的,不同的是,Vector是线程安全的。
查看源码可以知道Vector与ArrayList的方法实现都一样,只是Vector的方法有synchronized修饰。
1.3、LinkedList
基于双向链表实现,增删快,查询慢,线程不安全。
LinkedList采用双向链表结构存储元素,因此随机插入和删除效率高。此外,LinkedList孩提痛了在List接口中未定义的方法,用于操作链表头和为的元素,故而,可以当作栈、队列或者双向队列使用。
LinkedList的查询方法:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//如果查询的元素位于前半段,则从头部开始向后查询;反之则从尾部开始向前查询
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
二、Queue
Queue是队列结构,Java中比较常用的队列如下:
- ArrayBlockingQueue:基于数组数据结构实现的有界阻塞队列。
- LinkedBlockingQueue:基于链表数据结构实现的有界阻塞队列。
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
- DelayQueue:支持延迟操作的无界阻塞队列。
- SynchronousQueue:用于线程同步的阻塞队列。
- LinkedTransferQueue:基于链表数据结构实现的无界阻塞队列。
- LinkedBlockingDeque:基于链表数据结构实现的双向阻塞队列。
三、Set
无序、不可重复。
Set核心是独一无二的性质。用于存储无序且不相等的元素。对象的相等性在本质上是对象的HashCode值相等。Java依据的是对象的内存地址计算出对象的HashCode值。
3.1、HashSet
HashMap实现,无序。
HashSet存放的是散列值。元素的散列值是通过元素的hashCode()方法计算得到的,HashSet首先就判断两个元素的散列值是否相等,如果散列值相等,则通过equals()方法比较,如果equals()方法返回的结果也是true,HashSet则将其视为相同元素,否则认为是不同元素。
四、Map
4.1、HashMap
数组 + 链表/二叉树实现,线程不安全,key唯一
HashMap是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap基于键的HashCode值唯一标识一条数据,同时基于键的HashCode值进行数据的存取。因此可以快速的更新和查询数据。key和value允许为null。
jdk1.8之前,HashMap的基本结构如下:
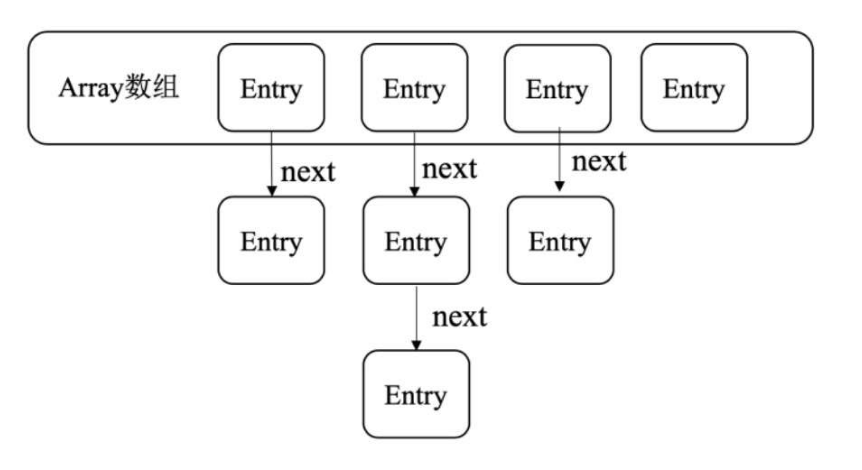
HashMap内部是一个数组,数组中的每个元素是一个单向链表,链表中的每个元素都是嵌套类Entry的实例,Entry包含4个属性:key、value、hash值和指向下一个元素的指针next。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
HashMap常用参数:
- capacity:数组容量,默认是16,可以扩容,每次扩容两倍。
- loadFactor:负载因子,默认0.75。
- threshold:扩容阈值,其值为capacity * loadFactor。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The next size value at which to resize (capacity * load factor).
*/
int threshold;
HashMap在查找数据时,根据hash值可以快速定位到数组的具体位置,然后遍历链表找到所需数据。
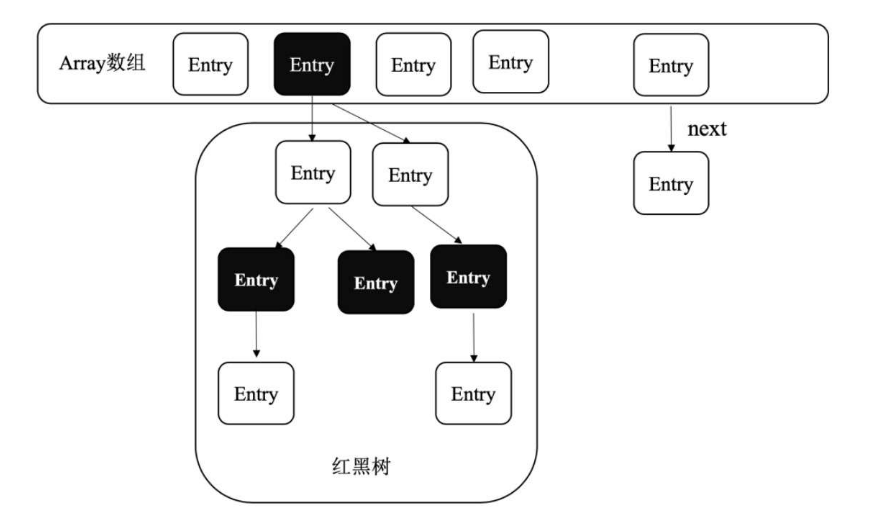
为了减少链表遍历的开销,jdk1.8开始,对HashMap进行了优化,将数据结构修改为数组+链表/红黑树。在链表的元素超过8(即TREEIFY_THRESHOLD参数)个以后,将链表树化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号