

Tensorflow2.0笔记19——iris 数据集代码复现
Tensorflow2.0笔记
本博客为Tensorflow2.0学习笔记,感谢北京大学微电子学院曹建老师
2.iris 数据集代码复现
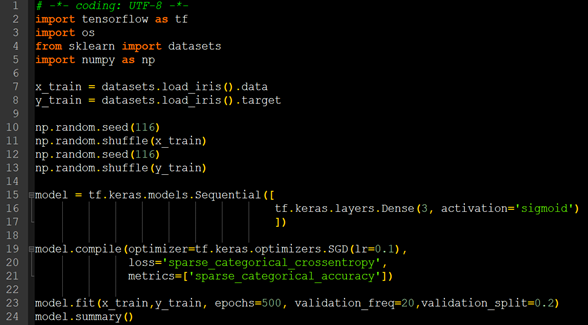
第一步:import 相关模块:
import tensorflow as tf from sklearn import datasets
import numpy as np
第二步:指定输入网络地训练集和测试集:
x_train = datasets.load_iris().data y_train = datasets.load_iris().target
其中测试集的输入特征 x_test 和标签 y_test 可以像x_train 和 y_train 一样直接从数据集获取,也可以如上述在 fit 中按比例从训练集中划分,本例选择从训练集中划分,所以只需加载 x_train,y_train 即可。
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116) np.random.shuffle(y_train)
tf.random.set_seed(116)
以上代码实现了数据集的乱序。
第三步:逐层搭建网络结构:
model =
tf.keras.models.Sequential([tf.keras.layers.Dense(3,
activation='softmax',
kernel_regularizer=tf.keras.regularizers.l2())
])
如上所示,本例使用了单层全连接网络,第一个参数表示神经元个数,第二个参数表示网络所使用的激活函数,第三个参数表示选用的正则化方法。
使用 Sequential 可以快速搭建网络结构,但是如果网络包含跳连等其他复杂网络结构,Sequential 就无法表示了。这就需要使用 class 来声明网络结构。
class MyModel(Model):
def init (self):
super(MyModel, self). init ()
//初始化网络结构
def call(self, x):
y = self.d1(x)
return y
使用 class 类封装网络结构,如上所示是一个 class 模板,MyModel 表示声明的神经网络的名字,括号中的 Model 表示创建的类需要继承 tensorflow 库中的 Model 类。类中需要定义两个函数, init ()函数为类的构造函数用于初始化类的参数,spuer(MyModel,self). init ()这行表示初始化父类的参数。之后便可初始化网络结构,搭建出神经网络所需的各种网络结构块。call() 函数中调用 init ()函数中完成初始化的网络块,实现前向传播并返回推理值。使用 class 方式搭建鸢尾花网络结构的代码如下所示。
class IrisModel(Model):
def init (self):
super(IrisModel, self). init ()
self.d1 = Dense(3, activation='sigmoid', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, x):
y = self.d1(x)
return y
搭建好网络结构后只需要使用 Model=MyModel()构建类的对象,就可以使用该模型了。
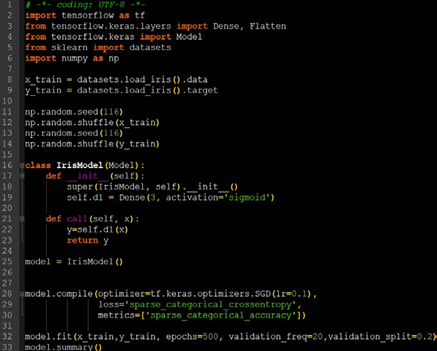
对比使用 Sequential()方法和 class 方法,有两点区别:
①import 中添加了 Model 模块和 Dense 层、Flatten 层。
②使用 class 声明网络结构,model = IrisModel()初始化模型对象。
第 四 步 : 在 model.compile() 中 配 置 训 练 方 法 :
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False,
metrics=['sparse_categorical_accuracy'])
如上所示,本例使用 SGD 优化器, 并将学习率设置为 0.1 ,选择SparseCategoricalCrossentrop 作为损失函数。由于神经网络输出使用了softmax 激活函数, 使得输出是概率分布,而不是原始输出, 所以需要将from_logits 参数设置为 False。鸢尾花数据集给的标签是 0,1,2 这样的数值, 而网络前向传播的输出为 概率分布,所以 metrics 需要设置为sparse_categorical_accuracy。
第五步:在 model.fit()中执行训练过程:
model.fit(x_train,y_train,batch_size=32,epochs=500, validation_split = 0.2,validation_freq=20)
在 fit 中执行训练过程,x_train,y_train 分别表示网络的输入特征和标签, batch_size 表示一次喂入神经网络的数据量,epochs 表示数据集的迭代次数validation_split 表示数据集中测试集的划分比例,validation_freq 表示每迭代 20 次在测试集上测试一次准确率。
第六步:使用 model.summary()打印网络结构,统计参数数目:
model.summary()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号