python基础快速入门之----------字符编码具体原理
1.内存和硬盘都是用来存储的。
CPU:速度快
硬盘:永久保存

2.文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就可以启动一个进程,是在内存中的,所以在编辑器编写的内容也都是存放在内存中的,断电后数据就丢失了。因而需要保存在硬盘上,点击保存按钮或快捷键,就把内存中的数据保存到了硬盘上。在这一点上,我们编写的py文件(没有执行时),跟编写的其他文件没有什么区别,都只是编写一堆字符而已。
3.python解释器执行py文件的原理,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器执行刚刚加载到内存中的test.py的代码(在该阶段,即执行时,才会识别python的语法,执行到字符串时,会开辟内存空间存放字符串)
总结:python解释器与文本编辑器的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(识别python的语法)
4.什么是编码?
计算机想要工作必须通电,高低电平(高电平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字。那么让计算机如何读懂人类的字符呢?
这就必须经过一个过程:
字符---------(翻译过程)-------------数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
5.以下两个场景涉及到字符编码的问题:
1.一个python文件中的内容是由一堆字符组成的(python文件未执行时)
2.python中的数据类型字符串是由一串字符组成的(python文件执行时)
6.字符编码的发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符,为了满足其他国家,各个国家纷纷定制了自己的编码,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
需要强调的是:
unicode:简单粗暴,多有的字符都是2Bytes,优点是字符--数字的转换速度快;缺点是占用空间大。
utf-8:精准,可变长,优点是节省空间;缺点是转换速度慢,因为每次转换都需要计算出需要多长Bytes才能够准确表示。
1.内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是越快越好)
2.硬盘中或网络传输用utf-8,保证数据传输的稳定性。
1 所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode, 2 这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码 3 ,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8, 4 因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
1 所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode, 2 这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码 3 ,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8, 4 因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
七、字符编码转换
unicode------>encode(编码)-------->utf-8
utf-8---------->decode--------->unicode
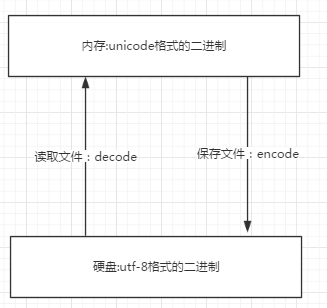
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
乱码:存文件时就已经乱码 或者 存文件时不乱码而读文件时乱码
总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
接下来介绍一下ASCII编码,Unicode编码及utf-8编码。
ASCII编码
全世界第一台计算机是在美国诞生,诞生之初计算机只能支持英语,也就是说只能支持 符号、字母、数字,不支持:汉语、日语、汉语、泰语等,由于计算机本质上全部都是二进制操作,所以当时做了一张 字符 和 二进制的对照表(ascii编码)。

通过上图可以发现:
- ascii码表中的256个对应关系,足以支持所有的英文操作了
ascii码规定用8位来表示一个字符。因为每一位有0/1两种可能,8位就可以支持256种可能,即:从 0000000、00000001、00000010 ~ 11111111 有256个,ascii就是这些二进制和字符来做的对应关系。
-
表中没有展示出二进制,按顺序仅分别显示了 十、十六、八进制,如果包含二进制关系的话,分别应该有:
二进制 十进制00000000 000000001 2...11111111 255
注意:ascii码中的
0 ~ 9指的不是数字而是字符串"1"、"2"..."9"与 二进制的对应关系。例如:
- 获取整数9对应的二进制时,直接通过 十进制和二进制的关系转换,即:1001
- 获取字符串”9”对应的二进制时,直接通过ascii码去找,即:00111001。
unicode字符集
由于ascii码只能表示256中字符对照关系,无法表示其他国家的文字,所有为了能让计算机支持全世界任意的文字就搞出来了一个unicode(字符集),他为全世界已知语言的所有字符都分配了一个码位(相当于是一个身份证ID),码位本质上也是个二进制。
读到这里,你可能会感觉unicode字符集 和 ascii编码一样,但其实字符集和编码还是有区别,如下:
- ascii编码,直接是字符和二进制的对照表,此二进制可在计算机中用于
内存计算、硬盘存储、网络传输等。字符 二进制a 01100001(十进制97;十六进制61)b 01100010(十进制98;十六进制62)
- unicode字符集,是字符和码位的对应关系,码位本质上也是二进制,此二进制可在计算机中用于
内存计算,但一般不会做硬盘存储和网络传输(为什么呢?下面有讲解)。字符 码位(ID)a 00000000 01100001(十进制97;十六进制61)b 00000000 01100010(十进制98;十六进制62)武 01101011 01100110(十进制27494;十六进制6B66)갵 10101100 00110101(十进制44085;十六进制AC35)
-
utf-8编码,是对unicode字符集的码位进行转换处理得到的二进制,此二进制可用于
内存计算、硬盘存储、网络传输等。字符 码位(ID) utf-8编码(可以对码位进行加工处理)a 00000000 01100001(十进制97;十六进制61) 01100001b 00000000 01100010(十进制98;十六进制62) 01100010武 01101011 01100110(十进制27494;十六进制6B66) 11100110 10101101 10100110갵 10101100 00110101(十进制44085;十六进制AC35) 11101010 10110000 10110101注意:这样一来utf-8编码的二级制和字符就生成了一个间接的对照表。
初步了解ascii编码、unicode字符集、utf-8编码关系之后,接下来对每个小点在进行解释。
接下来重点说unicode字符集,我们知道unicode字符集中包含了全世界所有的字符和码位的对应关系,这其中码位至关重要,因为码位必须足以支持全世界的字符。
-
起初unicode字符集固定使用2个字节来表示码位,即:ucs2。
ucs2用2个字节表示码位,所以码位能表示从 0000000000000000 至 1111111111111111 共 2**16=65525种可能,同时意味着ucs2能表示65535个字符。用十六进制表示这个范围的话就是:0000 ~ FFFF。ucs2中字符和码位的对应关系参见:http://www.columbia.edu/kermit/ucs2.html
-
后来unicode使用4个字节表示所有字符,即:ucs4。
因为随着时间的推移,发现的字符越来越多,这65535不够用了。所以就有了ucs4,他使用固定4个字节表示码位,码位就可以表示 2**32 = 4294967296 种可能,范围如下:二进制表示 00000000 00000000 00000000 00000000 ~ 11111111 11111111 11111111 11111111十六进制表示 00000000 ~ ffffffffucs4中字符和码位的具体对应关系参见:https://unicode-table.com/en/#00A5https://www.unicode.org/charts/
截止2019年5月unicode已收集137929个字符,也就说ucs4还没被占满,如果发现其他的文字还可以继续扩增。
注意:ucs4其实是对ucs2的一个扩展,ucs4默认使用4个字节表示码位而ucs2用2个字节表示码位。 对于ucs2的65535个码位,ucs4会在ucs2表示的码位前加 0,即:ucs2:01101011 01100110 变为 ucs4:00000000 00000000 01101011 01100110; 对于第65535后面的码位,则ucs4在ucs2基础上在进行扩增(图2和图3)。
图1:
图2:
图3:
写在最后,一般情况下用ucs2可以满足常见的文字,但如果想要表示更全/更多的话,肯定选择ucs4,并且现在越来越多的人都开始选择使用ucs4,例如:想要在系统中支持emoji图标,肯定要支持ucs4。
ucs4的优缺点:
- 缺点:因为都使用4个字节表示码位,同样的字符的码位会更占空间。所以,计算机中再
网络传输、硬盘存储时都不会用unicode字符集的码位存储,而是把码位转换(压缩)成utf-8等编码的二进制再进行传输和硬盘存储。 - 优点:可以表示所有字符并且长度固定4字节,方便内存中进行数据计算(不必担心太占用内存空间,因为内存占用的计算的数据一般不会太大)。
注:网络传输指的是通过网络发送一段文字等消息; 硬盘存储指的是把一些文档等信息保存到硬盘上。
utf-8编码
在上面讲unicode字符集时,有简单提到过:utf-8编码其实就是对unicode字符集的码位进行压缩加工处理得到的,把二进制码位中不必要位去掉。这样一来,utf-8既可以表示所有的字符,又可以进行 内存计算、网络传输、硬盘存储了,所以,这也是为什么utf-8编码可以在全球的广泛的应用。
总感觉utf-8是站在巨人unicode肩膀上功成名就的!!!
utf-8,是一套以 8 位为一个编码单位的可变长编码。会将一个码位编码为 1 到 4 个字节,对于码位进行编码时分为两步:
-
第一步:根据码位选择转换模板
码位范围(十六进制) 转换模板0000 ~ 007F 0XXXXXXX0080 ~ 07FF 110XXXXX 10XXXXXX0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX例如:"B" 对应的unicode码位为 0042,那么他应该选择的一个模板。"ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。"武" 对应的unicode码位为 6B66,则应该选择第三个模板。"沛" 对应的unicode码位为 6C9B,则应该选择第三个模板。"齐" 对应的unicode码位为 9F50,则应该选择第三个模板。注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。
- 第二步:码位以二进制展示,再根据模板进行转换
码位拆分: "武"的码位为6B66,则二进制为 0110101101100110根据模板转换:6 B 6 60110 1011 0110 0110----------------------------1110XXXX 10XXXXXX 10XXXXXX 使用第三个模板11100110 10XXXXXX 10XXXXXX 第一步:取二进制前四位0110填充到模板的第一个字节的xxxx位置11100110 10101101 10XXXXXX 第二步:挨着向后取6位101101填充到模板的第二个字节的xxxxxx位置11100110 10101101 10100110 第二步:再挨着向后取6位100110填充到模板的第三个字节的xxxxxx位置最终,"武"对应的utf-8编码为 11100110 10101101 10100110
除了utf-8之外,其实还有一些其他的 utf-7/utf-16/utf-32 等编码,他们跟utf-8类似,但没有utf-8应用广泛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号