mongo学习使用记录1
1 mongo的安装
1.添加MongoDB安装源
1.添加MongoDB安装源
vim /etc/yum.repos.d/mongodb-enterprise.repo
将下列配置项写入文件
[mongodb-enterprise]
name=MongoDB Enterprise Repository
baseurl=https://repo.mongodb.com/yum/redhat/$releasever/mongodb-enterprise/stable/$basearch/
gpgcheck=0
enabled=1
2.用yum安装MongoDB
yum install mongodb-enterprise
3.设置MongoDB进程开机启动
chkconfig mongod on #不建议使用这种方式
或者
echo "mongod -f /etc/mongod.conf --rest" >>/etc/rc.local #建议使用这种开机启动方式
详细信息介绍:
1.安装mongodb-enterprise,会安装以下几个包
mongodb-enterprise-server,包括Mongod进程,配置文件和初始化脚本;
mongodb-enterprise-mongos,包括mongos进程;
mongodb-enterprise-shell,包括mongo shell进程;
mongodb-enterprise-tools,包括mongoimport bsondump, mongodump,mongoexport, mongofiles, mongoimport, mongooplog, mongoperf, mongorestore, mongostat, 和mongotop工具;
2.yun MongoDB后配置文件为/etc/mongodb,初始化脚本为/etc/rc.d/init.d/mongod;
3.安装其他版本的MongoDB,例如安装2.6.1版本
yum install mongodb-enterprise-2.6.1
2、 windows安装
安装Mongo数据库:
第一步:下载安装包:如果是win系统,注意是64位还是32位版本的,请选择正确的版本。http://www.mongodb.org/downloads
第二步:新建目录“D:\MongoDB”,解压下载到的安装包,找到bin目录下面全部.exe文件,拷贝到刚创建的目录下。
第三步:在“D:\MongoDB”目录下新建“data”文件夹,它将会作为数据存放的根文件夹。
配置Mongo服务端:
打开CMD窗口,按照如下方式输入命令:
> cd D:\MongoDB
> mongod --dbpath D:\MongoDB\data
配置成功后会看到如下画面:
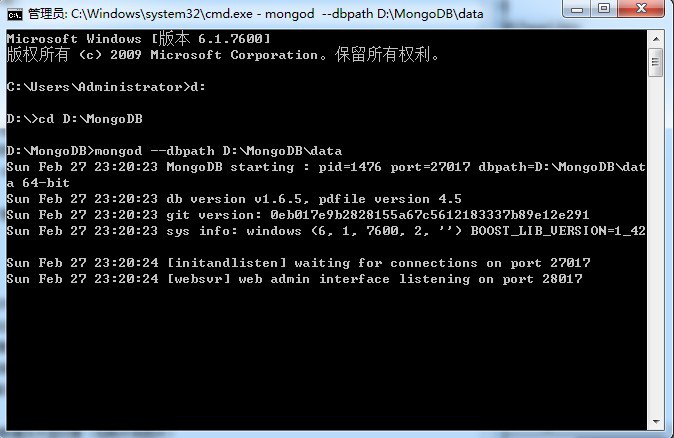
在浏览器输入:http://localhost:27017/,可以看到如下提示:
You are trying to access MongoDB on the native driver port. For http diagnostic access, add 1000 to the port number
如此,MongoDB数据库服务已经成功启动了。
下表为mongodb启动的参数说明:
|
参数 |
描述 |
|
--bind_ip |
绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP |
|
--logpath |
定MongoDB日志文件,注意是指定文件不是目录 |
|
--logappend |
使用追加的方式写日志 |
|
--dbpath |
指定数据库路径 |
|
--port |
指定服务端口号,默认端口27017 |
|
--serviceName |
指定服务名称 |
|
--serviceDisplayNam |
指定服务名称,有多个mongodb服务时执行。 |
|
--install |
指定作为一个Windows服务安装。 |
启动:
mongod -dbpath=/usr/local/mongodb/data --fork --port 27017 --logpath=/usr/local/mongodb/log/work.log --logappend --auth
mongod --dbpathD:\workspace\mongodb\data
注册为windows系统服务:
mongod --logpath "D:\workspace\mongodb\log\mongodb.log" --logappend --dbpath "D:\workspace\mongodb\data" --directoryperdb --port 27017 --serviceName "mongodbService" --serviceDisplayName "mongodbService" --install
MongoDB基本知识
1.MongoDB的数据基本称为文档,类似关系数据库的中的行;
2.类似,集合(Collection)是动态模式(dynamic schame)的表;
3.MongoDB的实例可以有多个相互独立的数据库,没有数据库中包含多个集合;
4.每个文档都有一个键,这个键在所在的集合中是唯一的;
5.MongoDB自带一个JavaScript Shell,用来管理MongoDB实例和数据操作;
(1).文档和键
文档数据表达类似哈希或者字典,例如:
{”geeting”:”hello world!”,”foo”:3}
或者
{”geeting”:”hello world!”}
{”foo”:3}
geeting和foo是键,”hello world”和3是值;
MongoDB区分大小,类型和顺序,例如
{”foo”:3}
{“FOO”:3}
{”foo”:”3“}
{”foo”:3}
{”geeting”:”hello world!”,”foo”:3}
{”foo”:3,“geeting”:”hello world!”}
这是个文档是不同的;
集合中的键不能重复,例如
{”foo”:”hello world!”,”foo”:3}
这个文档是非法的;
(2).动态模式(dynamic schame)
集合是动态模式的,意思是集合中的文档可以是各类各样的,例如
{”geeting”:”hello world!”}
{”foo”:3}
当然也可以将同一类格式的文档放进同一个集合,易创建索引和加快搜索,但是不强制这样做;
(3).集合
集合中可以有子集合,用点号来分隔,例如
集合blog有子集合posts和子集合authors,其分别表示为
blog.posts
blog.authors
(4).MongoDB数据库
MongoDB数据库是有多个集合组成,每个数据库都是一个单独的文件;MongoDB有保留的数据库名,例如
admin, 这是身份验证数据库,将用户添加到admin数据库,这个用户将自动获得所有的数据库的权限;另外,一些特殊的命令也只能从admin数据库运行,如列出数据库和关闭服务器;
local,所有的本地集合都可以在存储在这个数据库中。
config,MongoDB数据库用于分片设置,分片信息会存储在config数据库中;
mongo的简单使用
|
SQL术语/概念 |
MongoDB术语/概念 |
解释/说明 |
|
database |
database |
数据库 |
|
table |
collection |
数据库表/集合 |
|
row |
document |
数据记录行/文档 |
|
column |
field |
数据字段/域 |
|
index |
index |
索引 |
|
primary key |
primary key |
主键,MongoDB自动将_id字段设置为主键 |
use DATABASE_NAME 如果数据库不存在,则创建数据库,否则切换到指定数据库。
show dbs
db.dropDatabase()
db.cl.drop()
db.cl.insert({})
db.cl.save({})若指定_id更新 否则保存
db.cl.find().pretty()
db.cl.findOne()
db.getCollection('ideas').find({"_id":ObjectId("562dbecc87b15026cadb60d6")}) 按照id查询
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别
db.COLLECTION_NAME.update({},{},true|false,true|false);
第一个参数是查询选择器,与findOne的参数一样,相当于sql的where子句
第二个参数是更新操作文件,由各种更新操作符和更新值构成,
第三个参数是upsert。如果是true,表示如果没有符合查询选择器的文档,mongo将会综合第一第二个参数向集合插入一个新的文档。
第四个参数是multi。true:更新匹配到的所有文档,false:更新匹配到的第一个文档,默认值
第三第四个参数也可以合并成一个:
db.COLLECTION_NAME.update({},{},{multi:true|false,upsert:true|false});
db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
只更新第一条记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
全部更新:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
全部添加加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
全部更新:
db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
只更新第一条记录:
db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
db.getCollection('ideas').update({"user_id":"290536", "status" : { "$in" : [ "originality"]}},{$set:{'view_at':NumberLong(0)}},{multi:true})
db.getCollection('cycle_pending_idea_reminder').find({"user_id":"290536"},{$set:{"isFinished":false}},{multi:true})
db.getCollection('idea_selection_reminder').update({"user_id":"290536"},{$set:{"isFinished":false}},{multi:true})
db.getCollection('ideas').update({"user_id":"290536", "status" : { "$in" : [ "originality"]}},{$set:{'view_at':NumberLong(0)}},{multi:true})
db.getCollection('idea_selection_reminder').update({"user_id":"290536"},{$set:{"isFinished":false}},{multi:true})
db.getCollection('cycle_pending_idea_reminder').update({"user_id":"290536"},{$set:{"is_finished":false}},{multi:true})
简单介绍一下$addToSet
以这篇博文为例,如果我要增加一个标签可以执行以下命令
use iteye
db.blog.update({title:'mongo简介——$addToSet,update', author:'runfriends'},{$addToSet:{tags:'mongodb'}});
要增加多个就执行:
db.blog.update({title:'mongo简介——$addToSet,update'},{$addToSet:{tags:{$each:['Mongo','MongoDB','MONGODB']}}});
拥有类似事务特性的更新与查询操作——findAndModify.
它是原子性的,会返回符合查询条件的更新后的文档。
一次最多只更新一个文档,也就是条件query条件,且执行sort后的第一个文档。
db.COLLECTION_NAME.findAndModify({query:{},
update:{},
remove:true|false,
new:true|false,
sort:{},
fields:{},
upsert:true|false});
query是查询选择器,与findOne的查询选择器相同
update是要更新的值,不能与remove同时出现
remove表示删除符合query条件的文档,不能与update同时出现
new为true:返回个性后的文档,false:返回个性前的,默认是false
sort:排序条件,与sort函数的参数一致。
fields:投影操作,与find*的第二个参数一致。
upsert:与update的upsert参数一样。
不论是update的第二个参数,还是findAndModify的update,在不指定更新操作符的情况下,将会用指定的新值替换旧值。
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档。
writeConcern :(可选)抛出异常的级别。
db.cl.find().pretty()
操作 格式 范例 RDBMS中的类似语句
等于 {<key>:<value>} db.col.find({"by":"菜鸟教程"}).pretty() where by = '菜鸟教程'
小于 {<key>:{$lt:<value>}} db.col.find({"likes":{$lt:50}}).pretty() where likes < 50
小于或等于 {<key>:{$lte:<value>}} db.col.find({"likes":{$lte:50}}).pretty() where likes <= 50
大于 {<key>:{$gt:<value>}} db.col.find({"likes":{$gt:50}}).pretty() where likes > 50
大于或等于 {<key>:{$gte:<value>}} db.col.find({"likes":{$gte:50}}).pretty() where likes >= 50
不等于 {<key>:{$ne:<value>}} db.col.find({"likes":{$ne:50}}).pretty() where likes != 50
{'$and':[{'tenant':?2}, {'reportTime':{'$gte':?0}}, {'reportTime':{'$lte':?1}}]}
{'tenant':?2,'reportTime':{'$gte':?0,'$lte':?1}}
$regex 模式匹配 (可认为模糊查询) 对于正则表达式中的元字符需要转义 例如 \ . * | + $ [ ( {等。
$in
$inc
AND:
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件。
>db.col.find({key1:value1, key2:value2}).pretty()
db.col.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()
OR:
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
db.col.find({"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
'where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')'
形如 a>1 and b>2 or c>3 and d>4 的逻辑查询,如果使用mongodb查询,应该写为:
db.example.find({
'$or':[
{'$and':[{'example.a':{'$gt':1}},{'example.b':{'$gt':2}}]},
{'$and':[{'example.c':{'$gt':3}},{'example.d':{'$gt':4}}]}
]
})
类型 $type
如果想获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令:
db.col.find({"title" : {$type : 2}})
类型 数字 备注
Double 1
String 2
Object 3
Array 4
Binary data 5
Undefined 6 已废弃。
Object id 7
Boolean 8
Date 9
Null 10
Regular Expression 11
JavaScript 13
Symbol 14
JavaScript (with scope) 15
32-bit integer 16
Timestamp 17
64-bit integer 18
Min key 255 Query with -1.
Max key 127
limit:
db.col.find({},{"title":1,_id:0}).limit(2)显示前2条
skip:
db.col.find({},{"title":1,_id:0}).limit(1).skip(1) 显示第2条
sort:
sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
db.COLLECTION_NAME.find().sort({KEY:1})
创建索引
db.col.ensureIndex({"title":1})
db.getCollection('zjy_t_user_records').ensureIndex({
"username":1,
"deleted":-1
},{
"name":"_idx_un_d_",
"unique":true
});
Parameter Type Description
background Boolean 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。
unique Boolean 建立的索引是否唯一。指定为true创建唯一索引。默认值为false.
name string 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。
dropDups Boolean 在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false.
sparse Boolean 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false.
expireAfterSeconds integer 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。
v index version 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。
weights document 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。
default_language string 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语
language_override string 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为
聚合:
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
select by_user, count(*) from mycol group by by_user
表达式 描述 实例
$sum 计算总和。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
$avg 计算平均值 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
$min 获取集合中所有文档对应值得最小值。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
$max 获取集合中所有文档对应值得最大值。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])
$push 在结果文档中插入值到一个数组中。 db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}])
$addToSet在结果文档中插入值到一个数组中,但不创建副本。 db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])
$first 根据资源文档的排序获取第一个文档数据。 db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])
$last 根据资源文档的排序获取最后一个文档数据 db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
管道:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
$match实例
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
$skip实例
db.article.aggregate({ $skip : 5 });
经过$skip管道操作符处理后,前五个文档被"过滤"掉
--------------------------------------------- --------------------------------------------- --------------------------------------------- --------------------------------------------- ---------------------------------------------
Mongodb基础用法及查询操作
插入多条测试数据
> for(i=1;i<=1000;i++){
... db.blog.insert({"title":i,"content":"mongodb测试文章。","name":"刘"+i});
... }
db.blog.list.find().limit(10).forEach(function(data){print("title:"+data.title);}) 循环forEach 用法
db.blog.findOne(); 取一条数据
db.blog.find();取多条数据
db.blog.remove(); 删除数据集
db.blog.drop();删除表
删除一个数据库:
1.use dbname
2.db.dropDatabase()
======================================查询操作=============================
db.blog.find() 相当于select * from blog
db.blog.find({"age":27}) 相当于select * from blog where age='27'
db.blog.find({"age":27,"name":"xing"}) 相当于select * from blog where age='27' and name="xing"
db.blog.find({},{"name":1}) select name from blog ,如果name:0则是不显示name字段
db.blog.find().limit(1) 相当于select * from blog limit 1
db.blog.find().sort({_id:-1}).limit(1)相当于select * from blog order by _id desc limit 1
db.blog.find().skip(10).limit(20) 相当于select * from blog limit 10,20
skip用的时候,一定要注意要是数量多的话skip就会变的很慢,所有的数据库都存在此问题,可以不用skip进行分页,用最后一条记录做为条件
db.blog.find({"age":{"$gte":18,"$lte":30}}) select * from blog where age>=27 and age<=50
$gt >
$gte >=
$lt <
$lte <=
$ne !=
$in : in
$nin: not in
$all: all
$not: 反匹配
查询 creation_date > '2010-01-01' and creation_date <= '2010-12-31' 的数据
db.users.find({creation_date:{$gt:new Date(2010,0,1), $lte:new Date(2010,11,31)});
db.blog.find().sort({_id:-1}) 相当于select * from blog order by _id desc 按_id倒序取数据 1为正序,多个条件用,号分开如{name:1,age:-1}
db.blog.find({"_id":{"$in",[12,3,100]}}) 相当于select * from blog where _id in (12,3,100)
db.blog.find({"_id":{"$nin",[12,3,100]}}) 相当于select * from blog where _id not in (12,3,100)
db.blog.find({"$or":[{"age":16},{"name":"xing"}]}) 相当于select * from blog where age = 16 or name = 'xing'
db.blog.find({"id_num":{"$mod":[5,1]}}) 取的是id_num mod 5 = 1 的字段,如id_num=1,6,11,16
db.blog.find({"id_num":{"$not":{"$mod":[5,1]}}}) 取的是id_num mod 5 != 1 的字段,如除了id_num=1,6,11,16等所有字段,多于正则一起用
$exists判断字段是否存在
db.blog.find({ a : { $exists : true }}); // 如果存在元素a,就返回
db.blog.find({ a : { $exists : false }}); // 如果不存在元素a,就返回
$type判断字段类型
查询所有name字段是字符类型的
db.users.find({name: {$type: 2}});
查询所有age字段是整型的
db.users.find({age: {$type: 16}});
db.blog.find({"z":null}) 返回没有z字段的所有记录
db.blog.find({"name":/^joe/i}) 查找name=joe的所有记录,不区分大小写
db.blog.distinct('content') 查指定的列,并去重
查询数组
db.blog.find({"fruit":{"$all":["苹果","桃子","梨"]}}) fruit中必需有数组中的每一个才符合结果
db.blog.find({"fruit":{"$size":3}}) fruit数组长度为3的符合结果
db.blog.find({"$push":{"fruit":"桔子"}})相当于db.blog.find({"$push":{"fruit":"桔子"},"$inc":{"size":1}})
$slice 可以按偏移量返回记录,针对数组。如{"$slice":10}返回前10条,{"$slice":{[23,10]}}从24条取10条
如果对象有一个元素是数组,那么$elemMatch可以匹配内数组内的元素
db.people.find({"name.first":"joe","name.last":"schmoe"}) 子查询如:{"id":34,"name":{"first":"joe","last":"schmoe"}}
db.blog.find({"comments":{"$elemMatch":{"author":"joe","score":{"$gte":5}}}}) 查joe发表的5分以上的评论,注意comments为二维数组
$where 在走投无路的时候可以用,但它的效率是很低的。
游标用法
cursor.hasNext()检查是否有后续结果存在,然后用cursor.next()将其获得。
>while(cursor.hasNext()){
var obj = cursor.next();
//do same
}
http://www.mongodb.org/display/DOCS/Advanced+Queries#AdvancedQueries-ConditionalOperators%3A%3C%2C%3C%3D%2C%3E%2C%3E%3D 手册
> use blog
> db.blog.insert({"title":"华夏之星的博客","content":"mongodb测试文章。"});
> db.blog.find();
{ "_id" : ObjectId("4e29fd262ed6910732fa61df"), "title" : "华夏之星的博客", "content" : "mongodb测试文章。" }
> db.blog.update({title:"华夏之星的博客"},{"author":"星星","content":"测试更新"});
> db.blog.find();
{ "_id" : ObjectId("4e29fd262ed6910732fa61df"), "author" : "星星", "content" : "测试更新" }
db.blog.insert不带括号则显示源码
db.blog.insert();插入
db.blog.update();更新
> db.blog.update({title:"华夏之星的博客"},{"author":"星星","content":"测试更新"});
update默认情况下只能对符合条件的第一个文档执行操作,要使所有的匹配的文档都得到更新,可以设置第四个参数为 true
> db.blog.update({title:"华夏之星的博客"},{"author":"星星","content":"测试更新"},false,true);
> db.runCommand({getLastError:1}) 可以查看更新了几条信息,n就是条数
备份blog数据库到/soft目录
/usr/local/webserver/mongodb/bin/mongodump -d blog -o /soft
还原数据库
/usr/local/webserver/mongodb/bin/mongorestore -d blog -c blog /soft/blog/blog.bson
导出数据库(备份出来的数据是二进制的,已经经过压缩。)
/usr/local/webserver/mongodb/bin/mongodump -h 127.0.0.1 -port 27017 -d demo -o /tmp/demo
导入数据
/usr/local/webserver/mongodb/bin/mongorestore -h 127.0.0.1 -port 27017 --directoryperdb /tmp/demo
5) $all
$all和$in类似,但是他需要匹配条件内所有的值:
如有一个对象:
下面这个条件是可以匹配的:
但是下面这个条件就不行了:
6) $size
$size是匹配数组内的元素数量的,如有一个对象:{a:["foo"]},他只有一个元素:
下面的语句就可以匹配:
官网上说不能用来匹配一个范围内的元素,如果想找$size<5之类的,他们建议创建一个字段来保存元素的数量。
8) $type
$type 基于 bson type来匹配一个元素的类型,像是按照类型ID来匹配,不过我没找到bson类型和id对照表。
db.things.find( { a : { $type : 16 } } ); // matches if a is an int
9)正则表达式
mongo支持正则表达式,如:
10) 查询数据内的值
下面的查询是查询colors内red的记录,如果colors元素是一个数据,数据库将遍历这个数组的元素来查询。
11) $elemMatch
如果对象有一个元素是数组,那么$elemMatch可以匹配内数组内的元素:
{ "_id" : ObjectId("4b5783300334000000000aa9"),
"x" : [ { "a" : 1, "b" : 3 }, 7, { "b" : 99 }, { "a" : 11 } ]
}
$elemMatch : { a : 1, b : { $gt : 1 } } 所有的条件都要匹配上才行。
注意,上面的语句和下面是不一样的。
$elemMatch是匹配{ "a" : 1, "b" : 3 },而后面一句是匹配{ "b" : 99 }, { "a" : 11 }
12) 查询嵌入对象的值
注意用法是author.name,用一个点就行了。更详细的可以看这个链接: dot notation
举个例子:
如果我们要查询 authors name 是Jane的, 我们可以这样:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号