
HashMap源码解析
HashMap是基于哈希表的Map接口的非同步实现
此实现提供所有可选的映射操作,并允许使用null值和null键
Hashtable跟HashMap很像,唯一的区别是Hashtalbe中的方法是线程安全的,也就是同步的
1 HashMap的数据结构:
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),
所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。
HashMap实际上是一个“链表的数组”的数据结构,每个元素存放链表头结点的数组,即数组和链表的结合体
如图:
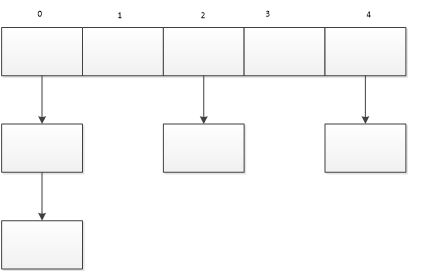
从上图中可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表
当新建一个HashMap的时候,就会初始化一个数组。
在代码中这个数组的名字叫table,是一个Entry类型的数组
Entry是HashMap的内部类,里面有key和value属性,还有一个Entry类的引用next,用来指向下一个节点
源码如下:
1 transient Entry[] table;
2
3
4 static class Entry<K,V> implements Map.Entry<K,V> {
5 final K key;
6 V value;
7 Entry<K,V> next;
8 final int hash;
9 ……
10 }
2 向HashMap中put一个元素
1 public V put(K key, V value) {
2 // HashMap允许存放null键和null值。
3 // 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
4 if (key == null)
5 return putForNullKey(value);
6
7 // 根据key的hashCode重新计算hash值。
8 int hash = hash(key.hashCode());
9 // 搜索指定hash值所对应table中的索引。
10 int i = indexFor(hash, table.length);
11
12 // 如果 i 索引处的 Entry 不为 null,通过循环不断遍历这个链表
13 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
14 Object k;
15 // ==比较key是否为一个对象
16 //通过 key的equal来比较内容是否相同
17 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
18 // 替换并返回旧的值
19 V oldValue = e.value;
20 e.value = value;
21 e.recordAccess(this);
22 return oldValue;
23 }
24 }
25
26 // 如果i索引处的Entry为null,表明此处还没有Entry。
27 // modCount记录HashMap中修改结构的次数
28 modCount++;
29 // 将key、value添加到i索引处。
30 addEntry(hash, key, value, i);
31 return null;
32 }
1 /**
2 key为null时是放在table的index=0的位置 然后遍历那个链表
3 */
4 private V putForNullKey(V value) {
5 for (Entry<K,V> e = table[0]; e != null; e = e.next) {//null对应的值已经存在 发生替换
6 if (e.key == null) {
7 V oldValue = e.value;
8 e.value = value;
9 e.recordAccess(this);
10 return oldValue;
11 }
12 }
13
14 // 第一次插入null和及其对应的值
15 // 对应的存储位置是table[0]
16 modCount++;
17 addEntry(0, null, value, 0);
18 return null;
19 }
从上面的源代码中可以看出:当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
addEntry(hash, key, value, i)方法根据计算出的hash值,将key-value对放在数组table的 i 索引处。addEntry 是HashMap 提供的一个包访问权限的方法(就是没有public,protected,private这三个访问权限修饰词修饰,为默认的访问权限,用default表示,但在代码中没有这个default),代码如下:
1 void addEntry(int hash, K key, V value, int bucketIndex) {
2 // 获取指定 bucketIndex 索引处的 Entry
3 Entry<K,V> e = table[bucketIndex];
4 // 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
5 table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
6 // 如果 Map 中的 key-value 对的数量超过了极限
7 if (size++ >= threshold)
8 // 把 table 对象的长度扩充到原来的2倍。
9 resize(2 * table.length);
10 }
当系统决定存储HashMap中的key-value对时,完全没有考虑Entry中的value,仅仅只是根据key来计算并决定每个Entry的存储位置。
我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可。
hash(int h)方法根据key的hashCode重新计算一次散列。此算法加入了高位计算,防止低位不变,高位变化时,造成的hash冲突。
1 static int hash(int h) {
2 h ^= (h >>> 20) ^ (h >>> 12);
3 return h ^ (h >>> 7) ^ (h >>> 4);
4 }
我们可以看到在HashMap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的 元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表,这样就大大优化了查询的效率。
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在HashMap中是这样做的:调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
static int indexFor(int h, int length) {
return h & (length-1);
}
这段代码保证初始化时HashMap的容量总是2的n次方,即底层数组的长度总是为2的n次方。
当length总是 2 的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
这种是否保证只有相同的hash值的两个值才会被放到数组中的同一个位置上形成链表。
而且当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
小结:
根据上面 put 方法的源代码可以看出,当程序试图将一个key-value对放入HashMap中时,程序首先根据该 key的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有Entry 的 value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。
3从HashMap中get
1 public V get(Object key) {
2 //key是null
3 if (key == null)
4 return getForNullKey();
5
6 //计算下标并遍历链表
7 int hash = hash(key.hashCode());
8 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null;e = e.next) {
9 Object k; //比较key的内容
10 if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
11 return e.value;
12 }
13 return null;
14 }
有了上面存储时的hash算法作为基础,理解起来这段代码就很容易了。
从上面的源代码中可以看出:
从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,
然后通过key的equals方法在对应位置的链表中找到需要的元素。
4归纳
HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。
HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,
当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;
当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry

 浙公网安备 33010602011771号
浙公网安备 33010602011771号