论文速览
Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion
基于深度敏感注意和自动多模态融合的深RGB-D显著性检测(DSA2F)
我们建议将原始深度图分解为多个区域,每个区域包含一组来自相同深度间隔的像素。
然后,我们提出了一种深度敏感注意模块(DSAM)在不同区域进行RGB特征提取,从而实现了基于深度几何先验的RGB特征增强。
RGB和深度通道上的多源信息非常异构,这使得特征融合设计非常困难和具有启发性。基于这一观察,我们利用神经架构搜索(NAS)[3,13,37]自动探索有效的特征融合模块。
我们构建了一个新的搜索空间,用于RGB-D SOD的多尺度多模态特征融合。
- 我们提出了一个深度敏感注意模块(DSAM),以明确消除背景干扰,并通过深度先验知识增强RGB特征。
- 我们为RGB-D SOD中的异构特征融合设计了一个新的搜索空间,并首次尝试在RGB-D SOD中引入NAS(解决多模态多尺度特征融合问题)。
DSAM:
- 多模态融合(MM)、
- 多尺度融合(MS)、
- 全局上下文聚合(GA)、
- 空间信息恢复(SR)单元。
细胞结构:
上述每个单元都可以由一个统一结构表示,该结构是一个有向无环图(DAG),由N={x(1),…,x(N)}表示的N节点的有序序列组成。每个nodex(i)是潜在表示(即特征映射),每个有向边(i,j)与一些候选操作o(i,j)∈o(例如conv,pooling)相关联,表示从x(i)到x(j)的所有可能变换。每个中间节点x(j)基于其所有前导节点计算:
为了使搜索空间连续,我们将特定操作的分类选择放宽到softmax,而不是所有可能的操作[37]:
其中o(·)是操作集o中的操作,α(i,j)o是边(i,j)的操作选择的可学习架构参数。因此,每个单元架构由{α(i,j)}表示。整个可搜索融合模块可以表示为α={αmm,αms,αga,αsr}。相同类型的单元共享相同的体系结构参数,但权重不同。在搜索阶段之后,可以通过用最可能的操作(即argmax o∈oα(i,j)o)替换每个混合操作o(i,j)来确定最佳操作。
在RGB-D SOD文献[21,31,32,47,59,60,63]中,有三个一致的原则是值得注意的:
- 来自同一尺度的不同形态的特征总是被融合MM,而不同尺度的特征被选择性地融合MS。
- 在最终预测之前,低层特征总是与高层特征相结合GA,因为低层特征具有丰富的空间细节,但缺乏语义信息,反之亦然。
- 在进行不同模态的特征融合时,注意机制是必要的。
(未完待续)
Residual Learning for Salient Object Detection
显著目标检测的残差学习算法
现有问题
- 很难直接学习判别特征和滤波器来回归每个尺度的高分辨率显著性掩模;
- 重新缩放多尺度特征可能会引入许多冗余和不准确的值,这削弱了网络的表现能力。
最后一个卷积层的特征的空间分辨率通常由于CNN中的多个跨步而降低32倍。这会导致丢失更精细的图像细节,这不利于像素级的标记任务。
在这种限制下,早期基于深度学习的显著目标检测方法通常转向预测图像片段的显著值,如目标建议[14]或超像素[13]。作者利用CNN的高级特征来决定每个图像片段是否显著,并结合结果生成最终显著性图。然而,这种策略使得推理比实时慢得多。
通过在像素级标记任务中引入完全卷积神经网络(FCN)[12]来解决此限制。在传统的基于FCN的深度网络中,反褶积滤波器广泛应用于VGG-16网络顶部的上采样操作[15],以重建更高分辨率的深度特征或直接产生推断。然而,通过反褶积操作很难恢复物体边界等精细细节(低级视觉特征)。这导致最近的显著性检测方法探索多尺度结构以增强空间细节。
现有特征
- 早期层中的特征保留更高的空间分辨率以精确重建详细边界;
- 后期层中的特征捕获更多的语义信息以识别图像区域。
作者工作
-
提出了一种基于残差学习的显著目标检测策略。不同于以往的基于多尺度的预测模型,我们采用残差学习学习过程来逐步调整预测。这种校准过程是从粗小尺度到细大尺度进行的,直到预测与最细的地面真相相匹配。
-
我们使用扩展卷积金字塔池(DCPP)模块来生成基于全局上下文知识的粗略预测(旨在大致定位突出目标)。然后我们引入了几种新的注意剩余模块(ARMs),通过残差学习来调整粗预测。手臂引导细化过程聚焦于空间细节,尤其是对象边界,使显著性贴图更具辨别力。
R2Net
为了获得适合显著性检测的高分辨率特征,作者做了两个修改:
- 我们简单地丢弃VGG-16顶部的两个完全连接的层,因为它们主要用于分类问题
- 我们用膨胀卷积替换VGG中的第五层卷积层,并忽略最后两个向下缩放操作。
DCPP
(未完待续)
通道注意力,空间注意力,像素注意力
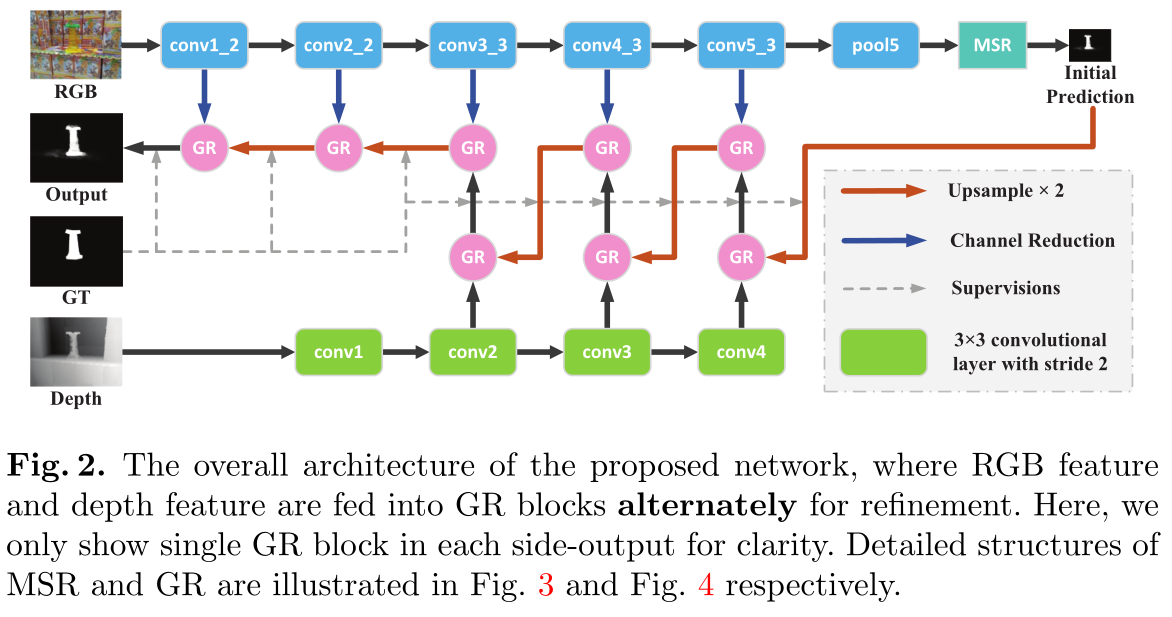
Progressively Guided Alternate Refinement Network for RGB-D Salient Object Detection
用于RGB-D显著目标检测的渐进引导交替细化网络
论文:https://arxiv.org/pdf/2008.07064.pdf
代码:https://github.com/ShuhanChen/PGAR_ECCV20
出处:ECCV2020
现有问题
- 当前的中期融合,通常使用从ImageNet预训练的独立主干网络来提取深度特征,RGB和深度图像之间固有的模态差异会导致模型不兼容。双流结构使模型参数和计算量增加了一倍,效率低下,存在大量冗余。
- 低质量的深度图,会对预测造成干扰。
作者贡献
没有直接融合RGB特征和深度特征(例如,串联或求和),在输入Deps有噪声的情况下,会降低可靠的RGB特征。
作者提出了一种细化策略来分别合并它们。
- 构造了一个轻量级的深度流来提取互补的深度特征,在不存在不兼容问题的情况下,比使用预先训练好的主干网络更紧凑、更高效。
- 提出了一种替代的细化策略,将RGB特征和深度特征交替输入GR块,以避免在深度质量较低时破坏可靠RGB特征的良好特性。
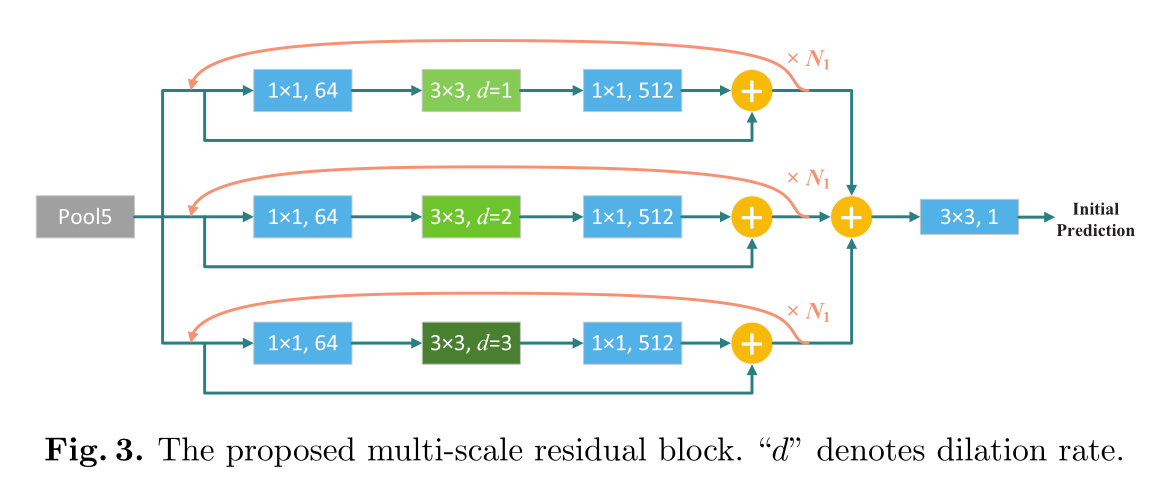
- 进一步设计了一个引导残差块 Multi-Scale Residual (MSR) block,以解决信息稀释问题,其中输入预测用作生成细化特征和细化预测的指导。通过将它们与渐进式制导叠加,可以很好地弥补缺失部分和错误预测。
多尺度残差块(MSR)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号