
模块2-2 模块基础
模块介绍
什么是模块
在Python中,一个.py文件就可以称之为一个模块(Module)
模块的好处
- 最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
- 使用模块还可以避免函数名和变量名冲突。每个模块有独立的命名空间,因此相同名字的函数和变量完全可以分别存在不同的模块中,所以,我们自己在编写模块时,不必考虑名字会与其他模块冲突
模块的分类
导入方式
from asyncio.events import get_event_loop_policy
from asyncio.events import get_event_loop_policy as get_event
自定义模块
第三方模块
指定安装源(—trusted-host 得加上,是通过网站https安全验证用的)
pip install -i http://pypi.douban.com/simple/ alex_sayhi --trusted-host pypi.douban.com
常用第三方模块
OS&sys
时间处理模块
- 我们写程序时对时间的处理可以归为以下3种:
- 时间的显示,在屏幕显示、记录日志等
- 时间的转换,比如把字符串格式的日期转成Python中的日期类型
- 在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp), 表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。例子:1554864776.161901
- 格式化的时间字符串,比如"2020-10-03 17:54"
- 元组(struct_time)共九个元素。

time模块一般用于时间关系转换(时间戳、时间元组struct_time、格式字符串)
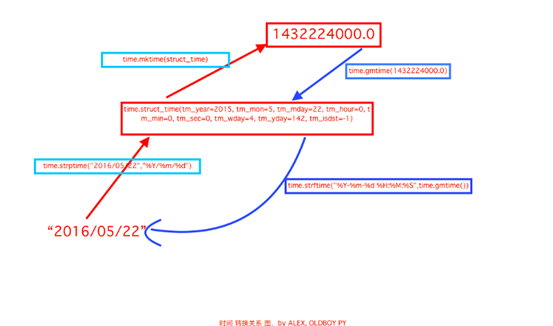
datatime模块一般用于时间的运算
- datatime模块主要的类:
- datetime.date:表示日期的类。常用的属性有year, month, day;
- datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond;
- datetime.datetime:表示日期时间。
- datetime.timedelta:表示时间间隔,即两个时间点之间的长度。
- datetime.tzinfo:与时区有关的相关信息。(这里不详细充分讨论该类,感兴趣的童鞋可以参考python手册)
random随机数
pickle和json序列化
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes。
dumps:将数据通过特殊的形式转换位只有python语言认识的字符串
dump:将数据通过特殊的形式转换位只有python语言认识的字符串,并写入文件
dumps:将数据通过特殊的形式转换位只有python语言认识的字符串
dump:将数据通过特殊的形式转换位只有python语言认识的字符串,并写入文件
只支持常规数据类型,str,int.dict,set,list,touple
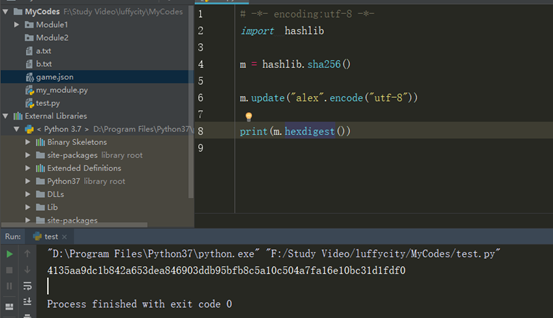
hashlib加密
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,他把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值.也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系
输入任意长度的信息,经过处理,输出为128位的信息(数字指纹);
抗修改性:对原数据进行任何改动,修改一个字节生成的MD5值区别也会很大
强抗碰撞:已知原数据和MD5,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
MD5不可逆的原因是其是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
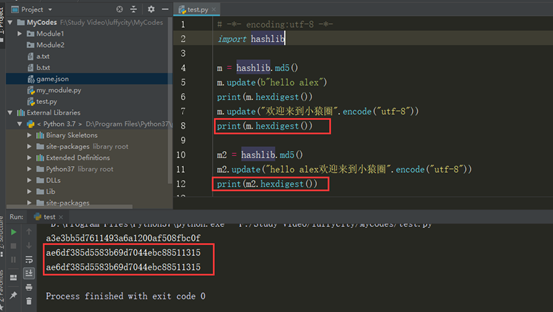
说明,多次update后,计算得到的hash值,是一个累加的值
文件copy shutil 模块
正则表达式re模块
- 常用re的匹配语法
- re.match 从头开始匹配
- re.search 匹配包含
- re.findall 把所有匹配到的字符放到以列表中的元素返回
- re.split 以匹配到的字符当做列表分隔符
- re.sub 匹配字符并替换
- re.fullmatch 全部匹配
- re.compile 生成表达式
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) '$' 匹配字符结尾, 若指定flags MULTILINE ,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到foo1 '*' 匹配*号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa' '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] '?' 匹配前一个字符1次或0次 ,re.search('b?','alex').group() 匹配b 0次 '{m}' 匹配前一个字符m次 ,re.search('b{3}','alexbbbs').group() 匹配到'bbb' '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' '(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45' '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,相当于re.match('abc',"alexabc") 或^ '\Z' 匹配字符结尾,同$ '\d' 匹配数字0-9 '\D' 匹配非数字 '\w' 匹配[A-Za-z0-9] '\W' 匹配非[A-Za-z0-9] '\s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P...)' 分组匹配 re.search("(?P[0-9]{4})(?P[0-9]{2})(?P[0-9]{4}
- Flags标志符
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M(MULTILINE): 多行模式,改变'^'和'$'的行为
- re.S(DOTALL): 改变'.'的行为,make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline.
- re.X(re.VERBOSE) 可以给你的表达式写注释,使其更可读,下面这2个意思一样

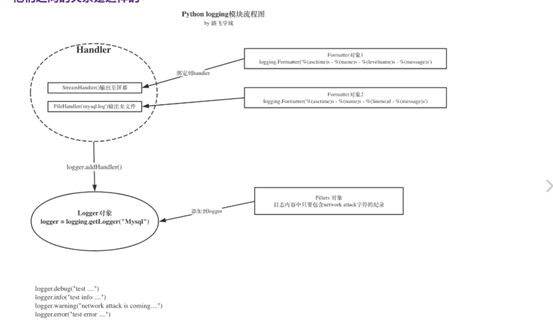
logging模块
日志级别

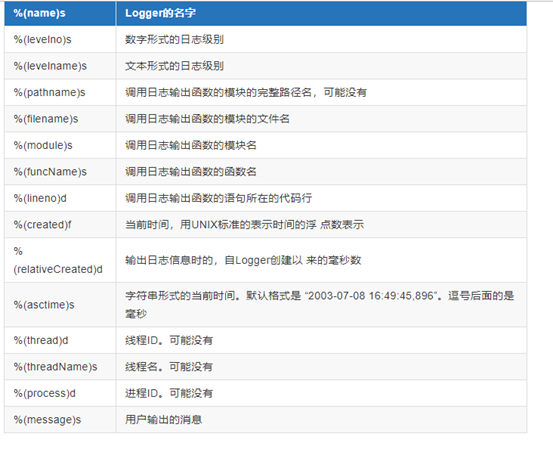
日志格式
日志模块的组件
- logger提供了应用程序可以直接使用的接口;
- handler将(logger创建的)日志记录发送到合适的目的输出;
- filter提供了细度设备来决定输出哪条日志记录;
- formatter决定日志记录的最终输出格式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号