爬虫入门之反反爬虫机制cookie UA与中间件(十三)
1. 通常防止爬虫被反主要有以下几个策略
(1)动态设置User-Agent(随机切换User-Agent,模拟不同的浏览器)
方法1: 修改setting.py中的User-Agent
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Hello World' #User-Agent
方法2: 修改setting中的 DEFAULT_REQUEST_HEADERS
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Hello World'
}
方法3 : 在代码中修改
class HeadervalidationSpider(scrapy.Spider):
name = 'headervalidation'
allowed_domains = ['helloacm.com']
def start_requests(self):
header={'User-Agent':'Hello World'}
yield scrapy.Request(url='http://helloacm.com/api/user-agent/',headers=header,callback=self.parse)
def parse(self, response):
print ('*'*20)
print response.body
(2)禁用Cookies
就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为
-
可以通过settings.py中的
COOKIES_ENABLED, 控制 CookiesMiddleware 开启或关闭 -
设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
DOWNLOAD_DELAY -
Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
-
使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban的
-
使用Crawlera(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。在settings中打开下载中间件
DOWNLOADER_MIDDLEWARES = { 'scrapy_crawlera.CrawleraMiddleware': 600 } CRAWLERA_ENABLED = True CRAWLERA_USER = '注册/购买的UserKey' CRAWLERA_PASS = '注册/购买的Password'
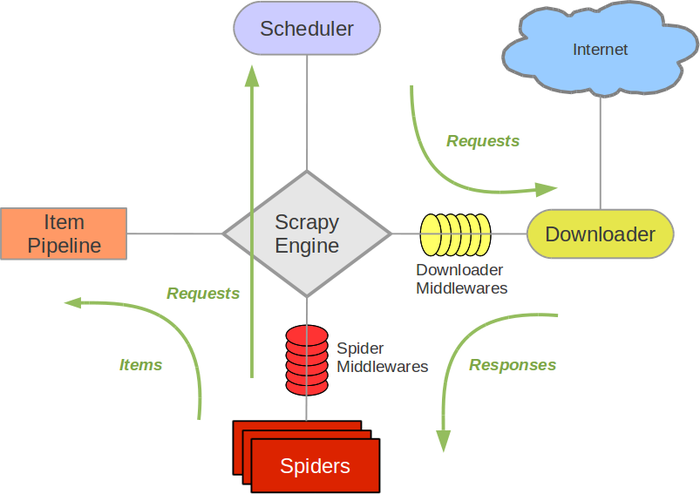
2.设置下载中间件(Downloader Middlewares)
下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。
- 当引擎传递请求给下载器过程中,下载中间件可以对请求进行处理 (增加http header信息 proxy信息等);
- 在下载器完成http请求,传递响应给引擎过程中,下载中间件可以对响应进行处理(例如进行gzip的解压等)
要激活下载器中间件组件,将其加入到 DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
#开放下载中间件
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyDownloaderMiddleware': 543,
}
一般下载中间件可以定义一下一个或多个方法:
process_request(self, request, spider)
- 当每个request通过下载中间件时,该方法被调用。
- process_request() 返回其中之一:None 、 Response 对象、 Request 对象或 raise IgnoreRequest:
- 如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
- 如果返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
- 如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
- 如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
- 参数:
request (Request 对象)– 处理的requestspider (Spider 对象)– 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
- process_response() 必须返回以下其中之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。
- 如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
- 如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
- 如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
- 参数:
request (Request 对象)– response所对应的requestresponse (Response 对象)– 被处理的responsespider (Spider 对象)– response所对应的spider
3 案例
-
创建
middlewares.py文件Scrapy代理IP、Uesr-Agent的切换都是通过
DOWNLOADER_MIDDLEWARES进行控制,我们在settings.py同级目录下创建middlewares.py文件,包装所有请求。
# middlewares.py
import random
from settings import USER_AGENTS
from settings import PROXIES
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
# 随机代理IP
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
request.meta['proxy'] = "http://" + proxy['ip_port']
- 修改settings.py配置USER_AGENTS和PROXIES
添加USER_AGENTS
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)"]
添加代理IP设置PROXIES:
PROXIES = [
{'ip_port': '111.8.60.9:8123'},
{'ip_port': '101.71.27.120:80'},
{'ip_port': '122.96.59.104:80'},
{'ip_port': '122.224.249.122:8088'},
]
除非特殊需要,禁用cookies,防止某些网站根据Cookie来封锁爬虫。
COOKIES_ENABLED = False
设置延迟
DOWNLOAD_DELAY = 3
最后设置setting.py里的DOWNLOADER_MIDDLEWARES,添加自己编写的下载中间件类
DOWNLOADER_MIDDLEWARES = {
#'mySpider.middlewares.MyCustomDownloaderMiddleware': 543,
'mySpider.middlewares.RandomUserAgent': 81,
'mySpider.middlewares.ProxyMiddleware': 100
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号