Q查询优化,ORM查询 常用字段参数类型,AJax携带文件数据
Q查询进阶操作
from django.db.models import Q
q_obj = Q() # 1.产生q对象
q_obj.connector = 'or' # 默认多个条件的连接是and可以修改为or
q_obj.children.append(('pk', 1)) # 2.添加查询条件
q_obj.children.append(('price__gt', 2000)) # 支持添加多个
res = models.Book.objects.filter(q_obj) # 查询支持直接填写q对象
print(res)
ORM查询优化
1.ORM的查询默认都是惰性查询
2.ORM的查询自带分页处理
3.only与defer
'''
only:可以将括号里面所列举的字段封装成数据对象,当你在点击括号里面的字段的时候是不会走SQL查询的,如果点没有的字段获取数据,那就会走SQL查询
defer:将括号里面的字段封装成数据对象,点括号里面的字段走SQL查询,没有的不走SQL查询
'''
only:
'''数据对象+含有指定字段对应的数据'''
# res = models.Book.objects.only('title', 'price')
# print(res) # queryset [数据对象、数据对象]
# for obj in res:
# print(obj.title) # 点击括号内填写的字段 不走SQL查询
# print(obj.price)
# print(obj.publish_time) # 可以点击括号内没有的字段获取数据 但是会走SQL查询
defer:
res = models.Book.objects.defer('title', 'price')
# print(res) # queryset [数据对象、数据对象]
for obj in res:
# print(obj.title) # 点击括号内填写的字段 走SQL查询
# print(obj.price)
print(obj.publish_time) # 点击括号内没有的字段获取数据 不走SQL查询
4.select_related与prefetch_related
select_related:
是连表操作,先把表 inner join 拼起来再整体封装成对象
prefethc_related:
相当于子查询,先查一张表,再查另一张表,然后将两张表的结果封装起来
在用的时候是感觉不出来的
res = models.Book.objects.all()
for obj in res:
print(obj.publish.name) # 每次查询都需要走SQL
res = models.Book.objects.select_related('authors') # 先连表后查询封装
res1=models.Author.objects.select_related('author_detail') # 括号内不支持多对多字段 其他两个都可以
print(res1)
for obj in res:
print(obj.publish.name) # 不再走SQL查询
res = models.Book.objects.prefetch_related('publish') # 子查询
for obj in res:
print(obj.publish.name)
ORM事务操作
"""
1.事务的四大特性(ACID)
原子性、一致性、隔离性、持久性
2.相关SQL关键字
start transaction;
rollback;
commit;
savepoint;
3.相关重要概念
脏读、幻读、不可重复读、MVCC多版本控制...
"""
django orm提供了至少三种开启事务的方式
方式1:配置文件数据库相关添加键值对 全局有效
"ATOMIC_REQUESTS": True每次请求所涉及到的orm操作同属于一个事务
方式2:装饰器 局部有效
from django.db import transaction
@transaction.atomic
def index():pass
方式3:with上下文管理 局部有效
from django.db import transaction
def reg():
with transaction.atomic():
pass
ORM常用字段类型
AutoField
primary_key=True
CharField
max_length
IntegerField
BigIntergerField
DecimalField
max_digits decimal_places
DateField
auto_now auto_now_add
DateTimeField
auto_now auto_now_add
BooleanField
传布尔值自动存0或1
TextField
存储大段文本
EmailField
存储邮箱格式数据
FileField
传文件对象 自动保存到提前配置好的路径下并存储该路径信息
ORM还支持用户自定义字段类型
class MyCharField(models.Field):
def __init__(self, max_length, *args, **kwargs):
self.max_length = max_length
super().__init__(max_length=max_length, *args, **kwargs)
def db_type(self, connection):
return 'char(%s)' % self.max_length
class User(models.Model):
name = models.CharField(max_length=32) name(Charfield)
info = MyCharField(max_length=64) info(char)
ORM常用字段参数
primary_key 主键
verbose_name 注释
max_length 字段长度
max_digits 小数总共多少位
decimal_places 小数点后面的位数
auto_now 每次操作数据自动更新事件
auto_now_add 首次创建自动更新事件后续不自动更新
null 允许字段为空
default 字段默认值
unique 唯一值
db_index 给字段添加索引
choices 当某个字段的可能性能够被列举完全的情况下使用
性别、学历、工作状态、...
class User(models.Model):
name = models.CharField(max_length=32)
info = MyCharField(max_length=64)
# 提前列举好对应关系
gender_choice = (
(1, '男性'),
(2, '女性'),
(3, '其他'),
)
gender = models.IntegerField(choices=gender_choice,null=True)
user_obj = User.objects.filter(pk=1).first()
user_obj.gender #得到的是数字
user_obj.get_gender_display() #得到的是数字对应的值,如果超出范围的话则返回数字
to 关联表
to_field 关联字段(不写默认关联数据主键)
on_delete 当删除关联表中的数据时,当前表与其关联的行的行为。
1、models.CASCADE
'''
级联操作,当主表中被连接的一条数据删除时,从表中所有与之关联的数据同时被删除
'''
2、models.SET_NULL
'''
当主表中的一行数据删除时,从表中所有与之关联的数据的相关字段设置为null,此时注意定义外键时,这个字段必须可以允许为空
'''
3、models.PROTECT
'''
当主表中的一行数据删除时,由于从表中相关字段是受保护的外键,所以都不允许删除
'''
4、models.SET_DEFAULT
'''
当主表中的一行数据删除时,从表中所有相关的数据的关联字段设置为默认值,此时注意定义外键时,这个外键字段应该有一个默认值
'''
5、models.SET()
'''
当主表中的一条数据删除时,从表中所有的关联数据字段设置为SET()中设置的值,与models.SET_DEFAULT相似,只不过此时从表中的相关字段不需要设置default参数
'''
6、models.DO_NOTHING
'''
什么都不做,一切都看数据库级别的约束,注数据库级别的默认约束为RESTRICT,这个约束与django中的models.PROTECT相似
'''
Ajax
'''
异步提交 局部刷新
ajax不是一门新的技术并且有很多版本 我们目前学习的是jQuery版本(版本无所谓 本质一样就可以)
'''
基本语法
$.ajax({
url:'', // 后端地址 三种填写方式 与form标签的action一致
type:'post', // 请求方式 默认也是get
data:{'v1':v1Val, 'v2':v2Val}, // 发送的数据
success:function (args) { // 后端返回结果之后自动触发 args接收后端返回的数据
$('#d3').val(args)
}
})
Content-Type三种格式
1.urlencoded
'''
ajax默认的编码格式、form表单默认也是
数据格式 xxx=yyy&uuu=ooo&aaa=kkk
django后端会自动处理到request.POST中
'''
2.formdata
'''
django后端针对普通的键值对还是处理到request.POST中 但是针对文件会处理到request.FILES中
'''
3.application/json
form表单不支持 ajax可以
<script>
$('#d1').click(function () {
$.ajax({
url:'',
type:'post',
data:JSON.stringify({'name':'jason','age':18}), // 千万不要骗人家
contentType:'application/json',
success:function (args) {
alert(args)
}
})
})
</script>
# django后端如何接收ajax提交的json数据
django针对json格式的数据不会给你做任何的处理,需要我们自己从request.body中处理,接收过来的数据是二进制类型的,需要处理成python的字段类型
# 如何处理?
1. 解码 --------> decode('utf-8')
2. 反序列化---------> json.loads()
'''针对二进制类型的数据json.loads可以直接进行解码和反序列化'''
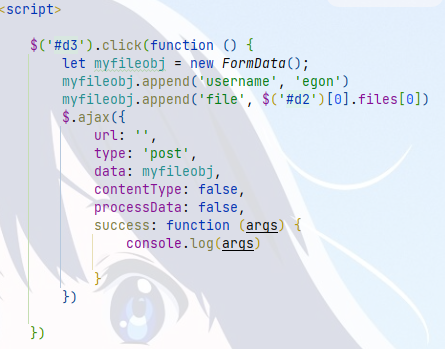
ajax携带文件数据
<script>
$('#d3').click(function () {
// 1.先产生一个FormData对象
let myFormDataObj = new FormData(); #js内置的对象,专门用来携带含有文件的数据
// 2.往该对象中添加普通数据
myFormDataObj.append('name', 'jason');
myFormDataObj.append('age', 18);
// 3.往该对象中添加文件数据
myFormDataObj.append('file', $('#d2')[0].files[0]) #$('#d2')[0]获取标签然后通过索引0获取标签对象,标签对象.files[0]获取文件对象
// 4.发送ajax请求
$.ajax({
url:'',
type:'post',
data:myFormDataObj,#直接填写内置对象就可以了(提前把数据添加好)
// ajax发送文件固定的两个配置
contentType:false,#不要任何编码,发送文件对象
processData:false,#不要让前端做任何处理打包
success:function (args){
alert(args)
}
})
})
</script>
ajax文件创建
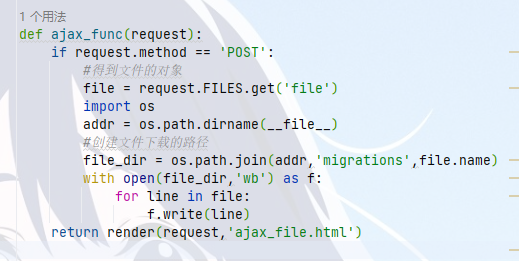
django内置序列化组件(drf前身)
'''前后端分离的项目 视图函数只需要返回json格式的数据即可'''
from app01 import models
from django.http import JsonResponse
def ab_ser_func(request):
# 1.查询所有的书籍对象
book_queryset = models.Book.objects.all() # queryset [对象、对象]
# 2.封装成大字典返回
data_dict = {}
for book_obj in book_queryset:
temp_dict = {}
temp_dict['pk'] = book_obj.pk
temp_dict['title'] = book_obj.title
temp_dict['price'] = book_obj.price
temp_dict['info'] = book_obj.info
data_dict[book_obj.pk] = temp_dict # {1:{},2:{},3:{},4:{}}
return JsonResponse(data_dict)
序列化组件(django自带 后续学更厉害的drf)
# 导入内置序列化模块
from django.core import serializers
# 调用该模块下的方法,第一个参数是你想以什么样的方式序列化你的数据
res = serializers.serialize('json', book_queryset)
return HttpResponse(res)
批量插入数据
# 插入10000条数据
for i in range(10000):
models.Book.objects.create() # ----》 insert()
lst = []
for i in range(10000):
book_obj = models.Book(title='')
lst.append(book_obj) # 把10000条数据给你拼成一条sql语句,一次性操作数据库,实际执行了一次
# 1.真正的操作数据库
models.Book.objects.bulk_create(lst)
# 2.查询出所有的表中并展示到前端页面
book_queryset = models.Books01.objects.all()
return render(request, 'BkPage.html', locals())
'''需要大家明白原理:'''
limit 1,500
limit 1000000, 10000500
# 面试题:你对MySQL查询性能优化有什么好的间接?----------->面试之前去查一查,记一记,给你们整理的有面试题,到时候你们只需要去看这个面试题,python的面试题,Redis的MySQL的...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号