django生命周期和路由层,ORM创建表关系
django生命周期
CGL(通用网关接口):
一个标准,定义了客户端服务器之间如何传数据
WSGI:
为Python语言定义的Web服务器和Web应用程序或框架之间的一种简单而通用的接口
uWSGI:
一个Web Server,即一个实现了WSGI的服务器,大体和Apache是一个类型的东西,处理发来的请求。
uwsgi:
它是uWSGI服务器实现的独有的协议,用于定义传输信息的类型,是用于前端服务器与 uwsgi 的通信规范。
https://www.yuque.com/liyangqit/cbndkh/evyps8
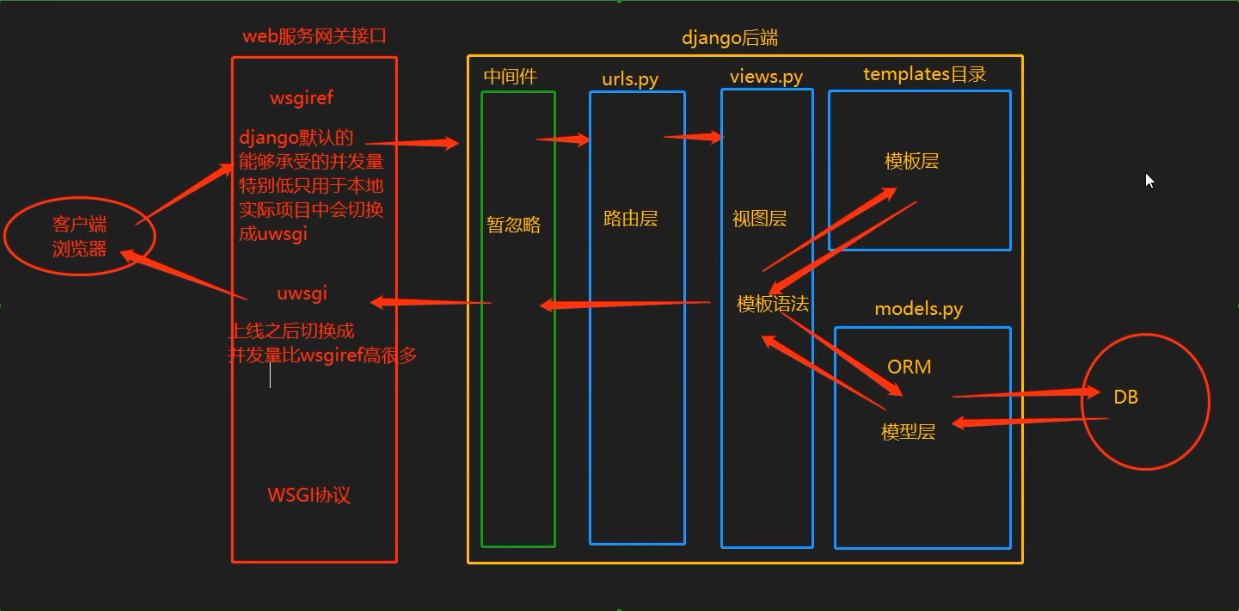
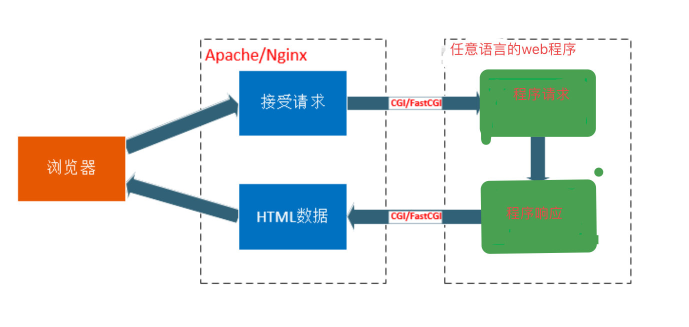
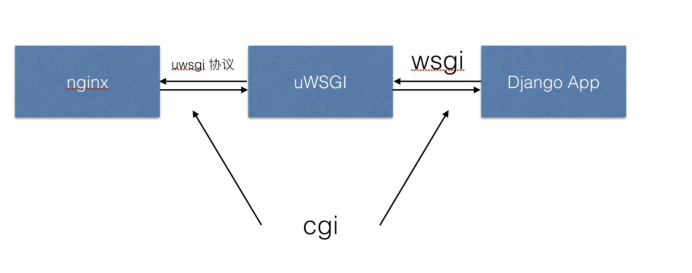
浏览器通过Nginx接受请求,然后通过wsgiref服务器处理发送过来的请求,然后通过WSGI协议将web服务器和web应用程序或者框架连接起来,处理完通过WSGI协议返回到uWSGI服务器,再通过uWSGI特有的uwsgi协议获取HTML数据返回到浏览器上面
django路由层
1.路由匹配
django2.X及以上 path第一个参数写什么就匹配什么
django1.X第一个参数是正则表达式
无论什么版本django都自带加斜杠后缀的功能 也可以取消
配置文件中 APPEND_SLASH = False #默认为true
2.转换器
正常情况下很多网站都会有很多相似的网址 如果我们每一个都单独开设路由不合理
django2.X及以上版本路由动态匹配有转换器(五种)
str:匹配除路径分隔符外的任何非空字符串。
int:匹配0或者任意正整数。
slug:匹配任意一个由字母或数字组成的字符串。
uuid:匹配格式化后的UUID。
path:能够匹配完整的URL路径
ps:还支持自定义转换器(自己写正则表达式匹配更加细化的内容)
# 转换器 将对应位置匹配到的数据转换成固定的数据类型
path('index/<str:info>/', views.index_func), # index_func(实参request对象,info='转换器匹配到的类型转换之后的内容')
path('index/<str:info>/<int:id>/', views.index_func) # index_func(实参request对象,info='转换器匹配到的类型转换之后的内容',id='转换器匹配到的类型转换之后的内容')
3.正则匹配
django2.X及以上版本有re_path 第一个参数是正则
匹配的本质是只要第一个正则表达式能够从用户输入的路由中匹配到数据就算匹配成功会立刻停止路由层其他的匹配直接执行对应的视图函数
re_path('^test/$', views.test) #加上^是以什么开头,$是结尾
'''django1.X路由匹配使用的是url() 功能与django2.X及以上的re_path()一致'''
4.正则匹配的无名有名分组
无名分组
re_path('^test/(\d{4})/', views.test)
会将括号内正则匹配到的内容当做位置参数传递给视图函数
有名分组
re_path('^test/(?P<year>\d{4})/', views.test)
'''?P<value>的意思就是命名一个名字为value的组,匹配规则符合后面的/d+'''
会将括号内正则匹配到的内容当做关键字参数传递给视图函数
注意上述的分组不能混合使用!!!
反向解析(模板语法)
通过一个名字可以反向解析出一个结果 该结果可以访问到某个对应的路由
基本使用
1.路由匹配关系起别名
path('login001/', views.login, name='login_view')
2.反向解析语法
html页面上模板语法 {% url 'login_view' %}
后端语法
之前是return redirect('/路由名/')
现在是reverse('login_view')得到路由名
通过这种方式达到解耦合的目的
动态路由的反向解析
path('func1/<str:others>/', views.func1_func, name='func1_view')
html页面上模板语法 {% url 'login_view' 'jason' %} #/login/jason/
#路由是动态的,不传值的话不知道该怎么找
后端语法 reverse('login_view', args=('egon',))#/login/egon/
通过args来传参数
有名无名分组反向解析
# 反向解析的本质:先给路由起一个别名,然后,通过一些方法去解析别名,可以得到这个别名对应的路由地址
无名分组反向解析
# 无名分组匹配到的内容以位置参数传给后面额视图函数
url(r'index/(\d+)/(\d+)/', view.index, name='index')
# 前端解析
{% url 'index' 123 234 %}
# 后端解析
reverse('index', args=(1, 2))
有名分组反向解析
# 有名分组匹配到的内容以关键字参数传给后面的视图函数
url(r'index/(?P<year>\d+)/(?P<month>\d+)/', view.index, name='index')
# 前端解析
{% url 'index' year=123 month=234 %}
# 后端解析
reverse('index', kwargs={'year':2023})
'''在django1中得url中使用,django2中用的是path,path不支持正则表达式,但是支持5种转换器,re_path就类似于url'''
ORM创建表关系
"""
一对一
一对多
多对多
"""
图书表(Book) 出版社表(publish) 作者表(author) 作者详情表(authordetail)
'''如果是外键字段的话,会自动帮你拼接_id,如果你自己写了,它也会给你拼上'''
1.作者与作者详情表是一对一的关系
'''外键字段建在任何一方都可以,一般建在查询频率较高的表'''
class Author(models.Model):
author_detail = models.OneToOneField(to='AuthorDetail')
'''以后都写在引号里面,防止找不到'''
2.图书和作者是多对多的关系
'''外键字段建在第三张表,使用虚拟字段建立第三张表,虚拟字段建在任何一张表中都是可以的,建在查询频率较高的一张表'''
class book(models,Model):
authors = models.ManyToManyField(to='Author')
'''
authors字段是一个虚拟字段,意思是不会在book表中创建出来authors字段,它就是用来告诉django给我创建出来第三张表
'''
3.图书和出版社是一对多的关系
'''外键字段建在多的一方,书是多,外键建在book表中'''
class book(models,Model):
# publish_id = models.ForeignKey(to='Publish', to_field='id')
# 默认是与Publish表的主键建立关系,如果不是主键,要用to_field建立字段名
publish = models.ForeignKey(to='Publish')
'''如果是外键字段的话,会自动帮你拼接_id,如果你自己写了,它也会给你拼上'''
'''用ORM创建以上三种关系'''
# 创建外键关系的时候,先创建一张表中得基础字段,在创建外键字段
'''在django1中,默认是级联删除级联更新'''
'''在django2中,现在的创建代码就不行了'''
这个时候就要在创建表关系是后面括号里面添加on_delete = models.CASCADE
达到级联更新删除的作用
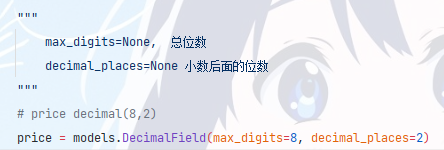
创建价格字段
on_delete参数
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE
删除关联数据,与之关联也删除
models.DO_NOTHING
删除关联数据,引发错误IntegrityError
models.PROTECT
删除关联数据,引发错误ProtectedError
models.SET_NULL
删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
models.SET_DEFAULT
删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
models.SET
删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号