
python题目
https://www.daxuesoutijiang.com/pc/download-plugin
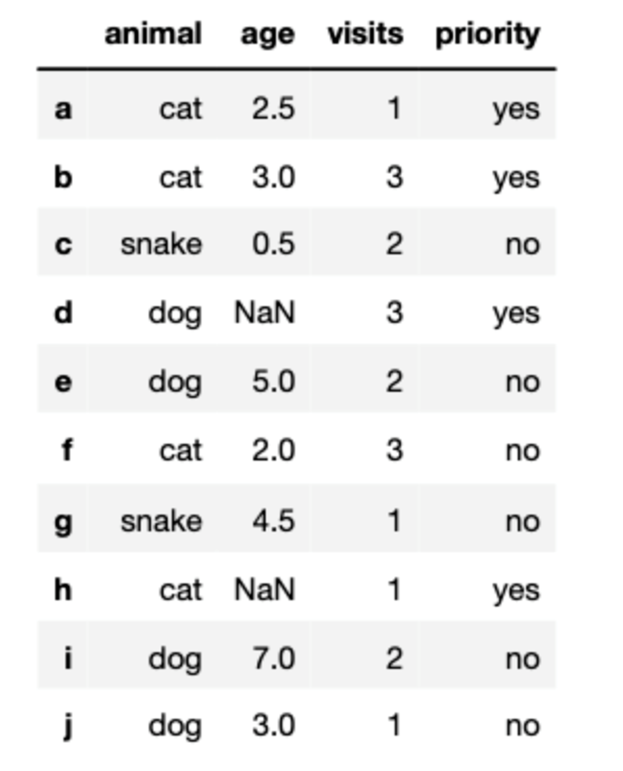
(1)选择df中列标签为animal和age的数据
df[['animal','age']]
df.loc[:,['animal','age']]
df.iloc[:,:2]
(2)选择行为[3, 4, 8],且列为['animal', 'age']中的数据
df.iloc[[3,4,8],:2]
(3)选择visits大于3的行
df[df.visits>=3]
(4)选择animal为cat,且age小于3的行
df[(df.animal=='cat') & (df.age<3)]
(5)将f行的age改为1.5
df.loc['f','age'] = 1.5
(6)计算visits列的数据总和
df.visits.sum()
(7)计算每种animal的个数(cat有几个,dog几个...)
df.animal.value_counts()
(8)先根据age降序排列,再根据visits升序排列
df.sort_values(by = ['age','visits'],ascending = [False,True])
第一题
array_2d=np.arange(1,10).reshape(3,3)请问array_2d[0,2][1,2]的结果是多少?
array_2d 的定义:
import numpy as np
array_2d = np.arange(1, 10).reshape(3, 3)
这段代码会生成以下二维数组:
array_2d =
[[1 2 3]
[4 5 6]
[7 8 9]]
要访问第一行第三列的元素,可以使用 array_2d[0, 2]:
element = array_2d[0, 2]
print(element) # 3
要访问第二行第三列的元素,用类似的方法:
python
element = array_2d[1, 2]
print(element) # 6
第二题
import pandas as pd
# 创建示例数据
data = {
'name': ['Jack', 'Sarah', 'Mike', 'David'],
'age': [24, 30, 21, 29],
'height': [175, 165, 180, 170]
}
# 创建 DataFrame
df = pd.DataFrame(data)
输出 df[1:4][0:1]['age'] 结果?
在代码 df[1:4][0:1]['age'] 中,如果要按照你的意图进行操作,可以按照以下方式来执行:
df[1:4] 选择 DataFrame 中的第 2 行到第 4 行(不包括第 4 行)。
[0:1] 接着选择选定的 DataFrame 的第 1 行。
最后,['age'] 选择结果中的 'age' 列。
因此,输出结果为:
2 30
Name: age, dtype: int64
这表示从第 2 行选取 'age' 列,即值为 30。
第三题
import pandas as pd
# 创建 DataFrame
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [5, None, 7, 8],
'C': [9, 10, 11, None]
})
# 删除 DataFrame 中的缺失数据
df = df.dropna()
# 打印删除缺失数据后的 DataFrame
print(df)
第四题:利用python内置的pip工具安装scikit-learn库的命名为?
要使用Python内置的pip工具安装scikit-learn库,你可以使用以下命令:
pip install scikit-learn
执行这个命令将会从Python包索引(PyPI)中下载并安装scikit-learn库。
第五题

补全下面代码,求解方程的值?
B=np.array([c1],[10],[4])
X=np.linaly.Solve(A,B)
import numpy as np
# 定义方程组的系数矩阵 A
A = np.array([[1, 1, 0], [1, 0, 1], [3, -1, 1]])
# 定义等号右边的常数向量 B
B = np.array([[1], [2], [10]])
# 求解方程组
X = np.linalg.solve(A, B)
print(X)
简答题1:K_means算法用到的模块是什么?
K-means算法在Python中的实现通常使用的是scikit-learn库。scikit-learn是一个强大的机器学习库,它包含了许多常用的机器学习算法,包括K-means聚类算法。在 Python 中,K-Means 算法通常使用 sklearn(scikit-learn)模块中的 KMeans 类来实现。因此,需要从 sklearn.cluster 模块中导入 KMeans 类来使用 K-Means 算法。
我们使用了以下模块:
numpy:用于创建和操作数组。
sklearn.cluster.KMeans:scikit-learn中的K-means聚类算法实现。
matplotlib.pyplot:用于绘制图形,帮助可视化聚类结果。
简答题2:scikit-learn中k_mean算法用到的模块是什么,创建kmeans模型的语句通常是什么?
在 scikit-learn 中,K-Means 算法的模块是 sklearn.cluster,其中提供了 KMeans 类来执行 K-Means 聚类。要创建 KMeans 模型,需要导入 KMeans 类并使用适当的参数进行实例化。
from sklearn.cluster import KMeans
# 创建K均值聚类模型并指定聚类簇数k
kmeans = KMeans(n_clusters=k)
其中,n_clusters参数用于指定聚类的簇数。可以根据具体需求设置不同的聚类簇数。
Kmeans算法思想
首先需要确定常数k,常数k意味着最终的聚类类别数,在确定了k值后,随机选定k个初始点为质心,并通过计算每一个样本点与质心之间的相似度(这里为欧式距离),根据点到质心欧氏距离大小,可以确定每个样本点应该和哪一个质心归为同一类数据,接着,根据这一轮的聚类结果重新计算每个类别的质心(即类中心),再对每一个点重新归类,重复以上分类过程,直到质心不再改变,就最终确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上K-Means算法的收敛速度比较慢。
简答题3:什么是RFM分析模型?
RFM分析模型是一种客户分析方法,它通过对客户的最近一次购买时间(Recency)、购买频率(Frequency)和消费金额(Monetary)进行综合评估,将客户划分成不同的层级,以便更好地理解客户的价值和行为特征。这个模型可以帮助企业识别出哪些客户可能是高价值客户,从而有针对性地进行营销和服务。
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过客户活跃程度和交易金额的贡献,进行客户价值细分。RFM模型主要根据以下三个指标来分析客户价值:
R(Recency):最近一次交易时间间隔。基于最近一次交易日期计算的一个值,距离当前日期越近,价值越高。
F(Frequency):客户在最近一段时间内交易次数。基于交易频率计算的一个值,交易频率越高,价值越高。
M(Monetary):客户最近一段时间内交易金额。基于交易金额计算的一个值,交易金额越高,价值越高。
简答题4:为什么要清洗数据?
在大数据领域,数据清洗是一个至关重要的步骤,具有以下重要原因:
①数据质量: 清洗数据可帮助提高数据质量,消除数据中的错误、缺失值和不一致性,确保数据准确性和完整性。
②准确分析: 清洗数据有助于提高数据分析的准确性。有效的数据清洗可以消除重复项、异常值和噪音数据,从而确保分析结果不受到影响。
③提高效率: 清洗数据可以提高数据处理和分析的效率。使用清洗后的数据集可以减少处理时间,并确保在处理大规模数据时不会出现错误。
④保护隐私: 在清洗数据的过程中,可以剔除包含敏感信息的数据,以保护个人隐私和数据安全。
⑤提升决策质量: 基于经过清洗的高质量数据进行决策能够提高决策的质量和准确性,从而帮助组织做出更明智的战略和业务决策。
⑥数据一致性: 数据清洗有助于确保数据的一致性,使得数据在不同系统之间、不同时间点之间能够保持一致性,从而提高数据的可靠性和可比性。
从各种渠道获得的源数据大多是“脏”数据,不符合人们的需求,如数据中含有唯一数据或重复数据、异常数据(包含错误或存在偏离期望的异常值,如age=”-10”,明显是错误数据),以及数据不完整(如缺少属性值)等。而我们在使用数据的过程中对数据的要求是具有一致性、准确性、完整性、时效性、可信性、可解释性。
本文来自博客园,作者:Cloudservice,转载请注明原文链接:https://www.cnblogs.com/whwh/p/18253169,只要学不死,就往死里学!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号