数据类型之内置方法
今日内容概要
-
-
列表的内置方法
-
字典的内置方法
-
队列与队栈
..............
今日内容详细
字符串的其他内置方法
![]()
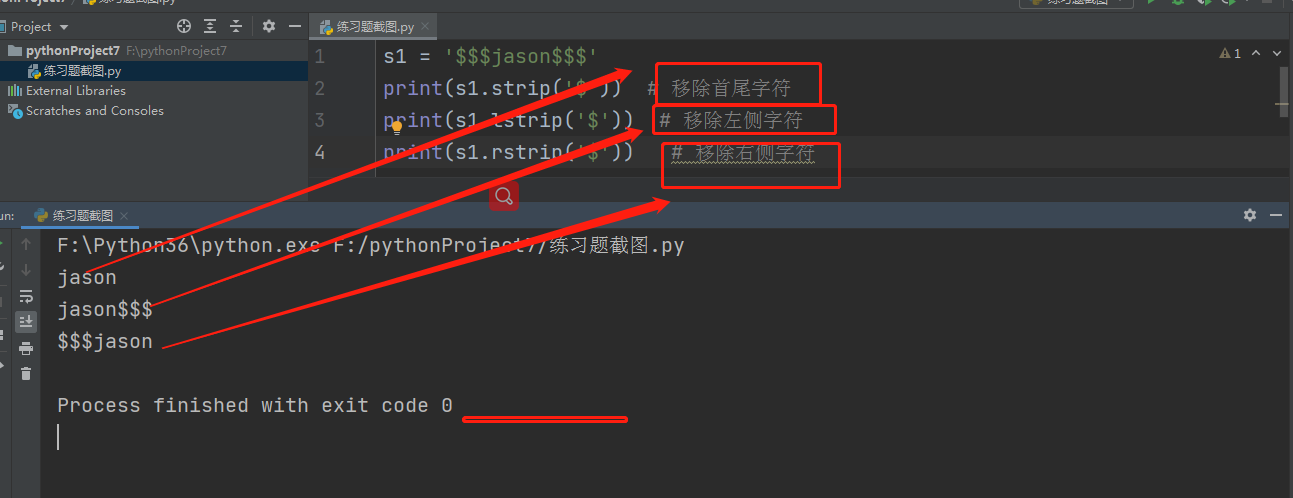
# 1.移除字符串首尾的指定字符 可以选择方向
# s1 = '$$$jason$$$'
print(s1.strip('$')) # 输出 jason
print(s1.lstrip('$')) # 将左边$符号移除
print(s1.rstrip('$')) # 将右边$符号移除
# 2.大小写相关操作
# s2 = 'tomNB'
# print(s2.lower()) # 将所有的英文字母变为小写 tomnb
# print(s2.upper()) # 将所有的英文字母变为大写TOMNB
# print(s2.islower()) # 判断字符串找那个所有的英文字母是否是纯小写 结果是布尔值 True or False
# print(s2.isupper()) # 判断字符串找那个所有的英文字母是否是纯大写 结果是布尔值 True or False
学习大小写操作的目的是为了图形验证码:一串有数字 大写字母 小写字母组成
为什么以前的认证码需要一模一样 大小写不能忽略 现在的验证码却可以 如何实现
# code = 'toNY6'
# print('这是返回给用户的图片验证码:%s' % code)
# user_code = input('请输入验证码>>>:').strip()
# if code.lower() == user.lower(): # 验证码忽略大小写 只需要统一转大小写即可
# print('验证码正确')
# 3.判断字符串的开头或者结尾是否是指定的字符
# s3 = 'jason kevin jason tony 888'
# print(s3.startswith('j')) # True
# print(s3.startswith('jason')) # True
# print(s3.startswith('tony')) # False
# print(s3.startswith('8')) # True
# print(s3.startswith('888')) # True
# print(s3.startswith('jason')) # False
# 4.格式化输出
# 方式1 占位符:%s %d
# 方式2 利用format方法》》》:四种用法
# 用法1:跟占位符一样的用法 使用{}占位
# print('my name is {} my age is {}'.format('jason',18))
# 用法2:根据索引取值 可以反复使用 可以随意几个到语句中
# print('my name mis {0}{0}{1} my age is {1}{1}'.format('jason',18))
# 用法3:根据指名道姓的方式取值
# print('my name is {name}{name} my age is {age}{passwoed}'.format(name='tony',age=17,password=123))
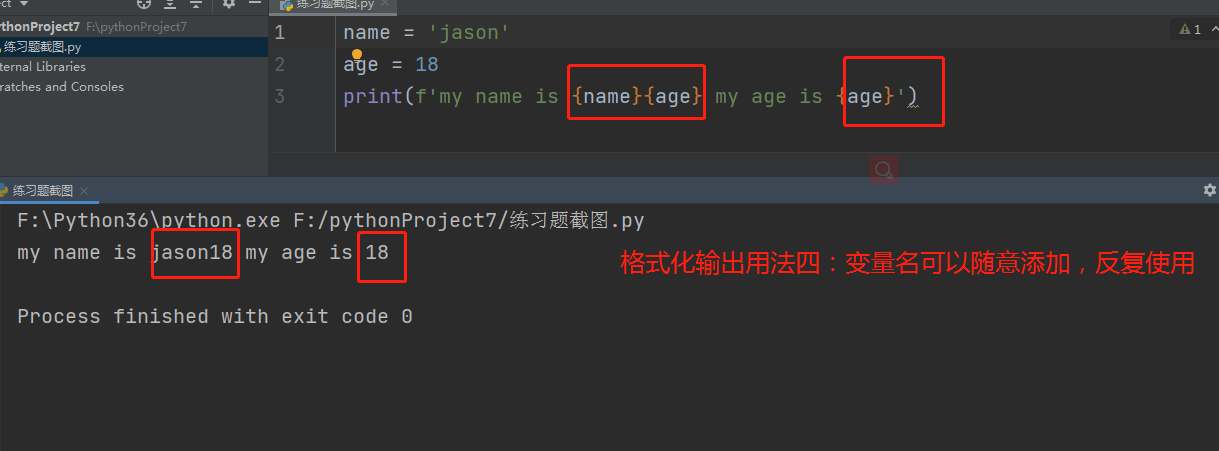
# 用法4:直接使用已经出现过的变量
# name = 'jason'
# age = 19
# print(f'my name is {name} my age is {age}{name}{name}')
在python官网以前推荐使用format格式化输出 甚至说要把%s要直接删除
# 5.拼接字符串join
# s1 = '举头望明月 低头思故乡'
# s2 = '世上无难事 只怕有心人'
# print(s1+s2) # 举头望明月 低头思故乡世无难事 只怕有心人(如果是字符串很大,加好会加大CPU工作效率,降低电脑的效率 )
# print(s1*10) # 会重复s1十次
# print('|'.join(s1)) # 举|头|望|明|月| |低|头|思|故|乡
# print('$'.join['jason','kevin','jason','tony'])
# jason$kevin$jsaon$tony
join方法相当于是将括号内的元素进行for循环,从左往右,一个一个取出来
# l1 = [11,'jason','kevin']
# print('|'.join(l1)) # join的元素必须都是字符串才可以,否则系统就会报错
# 6.替换字符串中指定的字符
# s6 = 'jason is DSB DSB DSB jason jason jason'
# 将jason替换成tony
# print(s6.replace('jason','tony')) # 默认一次性替代所有
# 指定替换的个数
# print(s6.replace('jason','tony',2)) # 还可以通过控制替换的个数 从左往右
很多文本编辑器里面的替换功能 就可以使用replace完成
# 7.判断字符串中是否是纯数字
# s7 ='jason123'
# print(s7.isdigit()) # False
# print('123'.isdigit()) # True
# print('123.21'.isdigit()) # False
前面我们在学评分系统时学过一个 score = int(score)在输入时系统会报错,为了解决这个问题,,我们可以:
score = input('score>>>:')
if score.isdigit():
score = int(score)
else:
print('能不能好好写')
![]()
字符串需要了解的内置方法
1.查找指定字符对应的索引值
s1 = 'jason justin kevin tony'
print(s1.find('s')) # 从左往右查找 查找到一个就会结束
print(s1.find('k',1,9)) # -1 y意思是没有 找不到
print(s1.index('s'))
print(s1.index('k',1,9)) # 找不到会直接报错 我们在编写代码时最怕的就是报错,所以不推荐使用会报错的结果
2.文本位置改变
name = 'tony'
print(name.center(30,'-')) # 总宽度是30,字符串居中显示,不够用短横线填充
print(name.ljust(30,'*')) # 总宽度是30,字符串左对齐显示,不够用*填充
print(name.rjust(30,'$')) # 总宽度是30,字符串右对齐显示,不够用$填充
print(name.zfill(50)) # 总宽度为50,字符串右对齐显示,不够用0填充
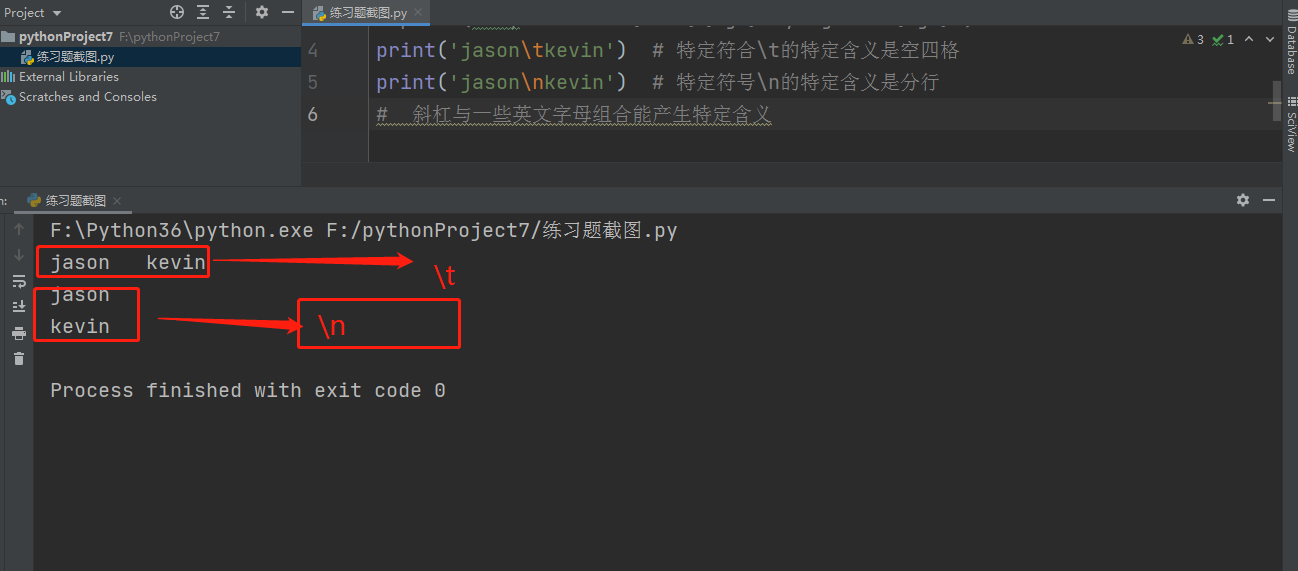
3.特殊符号:斜杆与一些英文字母的组合会产生特定的含义
print('ja\tson\nke\avin')
\t:表示的是空四格 ja ton
\n:表示的是换行
如果想取消它们的特定含义 可以在字符串的前面加上一个字母r
print('ja\tson\nke\avin')
4.captalize(首字母大写),swapcase(大小写翻转),title(每个单词首字母大写)
![]()
列表内置方法
1.类型转换
print(11) # 不能转换
print(lise(11.11)) # 不能转换
print(list('jason')) # ['j','a','s','o','n']
print(list({'name':'jason','pwd':123})) # ['name','pwd']
print(list((11,22,33,44,55))) # [11,22,33,44,55]
print(list({1,2,3,4,5})) # [1,2,3,4,5]
print(list(True))
因此可以找出规律list可以转换支持for循环的数据类型
可以被for循环的数据类型:字符串 列表 字典 元组 集合
常见操作
name_list = ['jason','kevin','tony','tom','jerry']
1.索引取值
print(name_list[0])
print(name_list[-1])
2.切片操作
print(name_list[1:4]) # ['kevin','tony','tom']
print(name_list[-4:-1]) # ['kevin','tony',tom]
print(name_list[-1:-4:-1]) # ['jerry','tom','tony']
3.间隔
print(name_list[0:4:1]) # ['jason','kevin','tony','tom']
print(name_list[0:4:2]) # ['jason','tony']
print(name_list[-1:-4:-1]) #
['jerry','tom','tony']
4.统计列表中元素的个数
print(len(name_list)) # 5
5.成员运算 最小判断单位是元素而不是元素内的单个字符
print('j' in name_list) # False
print('jason' in name_list) # True
6.列表添加元素的方式
6.1.尾部追加单个元素
name_list.append('小李')
print(name_list) # ['jason','kevin','tony','tom','小李']
name_list.append([11,22,33,44])
print(name_list) # ['jason','kevin','tony','tom',[11,22,33,44]]
6.2.指定位置插入单个元素
name_list.insert(0,123) # 是指在索引零位置处插入一个123元素
name_list.insert(2,'可以插个队') # 是指在索引2位置处插入一个'可以插个队'的元素
name_list.insert(1,[11,22,33]) # 是指在索引1位置处插入一个元素[11,22,33]
6.3.合并列表
name_list.extend([11,22,33,44,55])
print(name_list)
extend其实可以看成是for循环+append
for i in [11,22,33,44,55]:
name_list.append(i)