DS博客作业04--图
| 这个作业属于哪个班级 |
| ---- | ---- | ---- |
| 这个作业的地址 |
| 这个作业的目标 | 学习图结构设计及相关算法 |
| 姓名 | 吴慧敏 |
🔅0.PTA得分截图

🔅1.本周学习总结(6分)
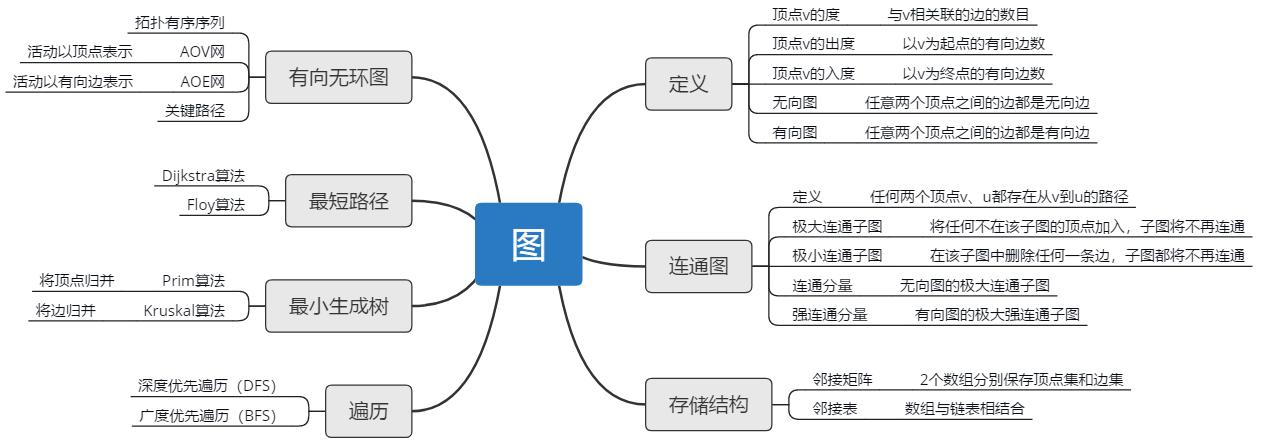
1.1 图的存储结构
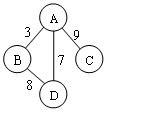
1.1.1 邻接矩阵
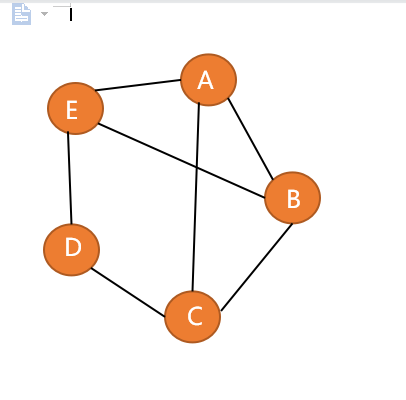
邻接矩阵的图
- 无向图的邻接矩阵
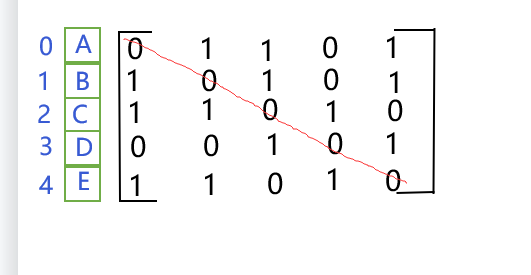
- 有向图的邻接矩阵

邻接矩阵的结构体定义
/*声明顶点的类型*/
#define MAXV<最大顶点个数>
typedef struct
{ int no; //顶点编号
InfoType info; //顶点其他信息
}VertexType;
/*声明的邻接矩阵类型*/
typedef struct //图的定义
{ int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,边数
VertexType vexs[MAXV]; //存放顶点信息
}MatGraph;
邻接矩阵建图函数

void CreateMGraph(MGraph &g,int n,int e)
{ //n顶点个数,e边个数
int i,j,a,b;
for(i=0;i<n;i++)//从0开始
for(j=0;j<n;j++)
g.edges[i][j]=0;
for(i=1;i<=e;i++)
{
cin>>a>>b;
g.edges[a-1][b-1]=1;//因为二维数组从0开始,所以a,b需要减1
g.edges[b-1][a-1]=1;
}
g.n=n;
g.e=e;
}
时间复杂度为:O(n²)。
1.1.2 邻接表
🔺注:
邻接表表示不唯一,特别适合于稀疏图的存储(邻接表的存储空间为O(n+e))。
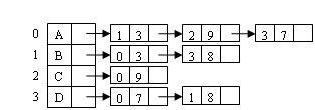
- 邻接表的结构体定义
//声明边结点类型
typedef struct ANode
{
int adjvex; //该边的终点编号
struct ANode* nextarc; //指向下一条边的指针
int info; //该边的相关信息,如权重
} ArcNode; //边表节点类型
typedef int Vertex;
//声明邻接表头节点类型
typedef struct Vnode
{
Vertex data; //顶点信息
ArcNode* firstarc; //指向第一条边
} VNode; //邻接表头节点类型
typedef VNode AdjList[MAXV];
//声明图邻接表类型
typedef struct
{
AdjList adjlist; //邻接表
int n, e; //图中顶点数n和边数e
} AdjGraph; ////完整的图邻接表类型
- 建图函数
void CreateAdj(AdjGraph*& G, int n, int e)//创建图邻接表
{
int i;
int a, b;
ArcNode* p;
G = new AdjGraph;
//G->adjlist = new VNode[n];//申请空间
for (i = 0; i < n; i++)
G->adjlist[i].firstarc = NULL;
for (i = 0; i < e; i++)
{
cin >> a >> b;
//用头插法创建邻接表
p = new ArcNode;
p->adjvex = b;
p->nextarc = G->adjlist[a].firstarc;
G->adjlist[a].firstarc = p;
//无向图,另一个节点也存在相同的关系
p = new ArcNode;
p->adjvex = a;
p->nextarc = G->adjlist[b].firstarc;
G->adjlist[b].firstarc = p;
}
G->e = e;
G->n = n;
}
1.1.3 邻接矩阵和邻接表表示图的区别
※邻接矩阵:适用数据量较大的图(类似稠密图),用一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息。时间复杂度为O(n²)。
※邻接表:适用数据量较少的图(稀疏图),因为更节省空间。是一种数组与链表相结合的存储方法;时间复杂度为O(n+e)。
对于一个具有n个顶点e条边的无向图,它的邻接表表示有n个顶点表结点2e个边表结点,它的邻接表表示有n个顶点表结点e个边表结点
1.2 图遍历
1.2.1 深度优先遍历
-
无向图的深度优先遍历
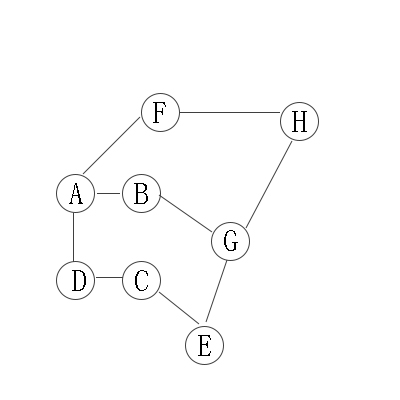
从A开始遍历
遍历结果:A -> B -> G -> E -> C -> D -> H -> F
第1步:访问A。
第2步:访问B(A的邻接点)。 在第1步访问A之后,接下来应该访问的是A的邻接点,即"B,D,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"D和F"的前面,因此,先访问B。
第3步:访问G(B的邻接点)。 和B相连只有"G"(A已经访问过了)
第4步:访问E(G的邻接点)。 在第3步访问了B的邻接点G之后,接下来应该访问G的邻接点,即"E和H"中一个(B已经被访问过,就不算在内)。而由于E在H之前,先访问E。
第5步:访问C(E的邻接点)。 和E相连只有"C"(G已经访问过了)。
第6步:访问D(C的邻接点)。
第7步:访问H。因为D没有未被访问的邻接点;因此,一直回溯到访问G的另一个邻接点H。
第8步:访问(H的邻接点)F。 -
有向图的深度优先遍历
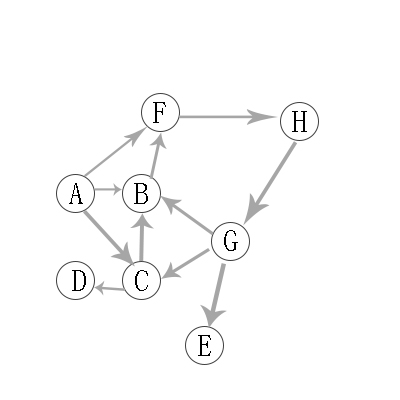
从A开始遍历
遍历结果:A -> B -> F -> H -> G -> C -> D -> E
第1步:访问A。
第2步:访问(A的出度对应的字母)B。 在第1步访问A之后,接下来应该访问的是A的出度对应字母,即"B,C,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"C和F"的前面,因此,先访问B。
第3步:访问(B的出度对应的字母)F。 B的出度对应字母只有F。
第4步:访问H(F的出度对应的字母)。 F的出度对应字母只有H。
第5步:访问(H的出度对应的字母)G。
第6步:访问(G的出度对应字母)E。 在第5步访问G之后,接下来应该访问的是G的出度对应字母,即"B,C,E"中的一个。但在本文的实现中,顶点B已经访问了,由于C在E前面,所以先访问C。
第7步:访问(C的出度对应的字母)D。
第8步:访问(C的出度对应字母)D。 在第7步访问C之后,接下来应该访问的是C的出度对应字母,即"B,D"中的一个。但在本文的实现中,顶点B已经访问了,所以访问D。
第9步:访问E。D无出度,所以一直回溯到G对应的另一个出度E。
深度遍历代码
- 邻接矩阵
void DFS(MGraph g, int v)//邻接矩阵深度遍历
{
if (flag == 0)
{
cout << v;
flag = 1;
}
else
cout << " " << v; //输出顶点
visited[v] = 1;//标记已访问该节点
for (int i = 1; i <= g.n; i++)
{
if(g.edges[v][i] == 1 && visited[i] == 0)
{
DFS(g, i); //当前顶点与 i 顶点邻接且未被访问,递归搜索
}
}
}
- 邻接表
void DFS(AdjGraph* G, int v)//v节点开始深度遍历
{
ArcNode* p;
p = G->adjlist[v].firstarc;
if (flag == 0)
{
cout << v;
flag = 1;
}
else
cout << " " << v;
visited[v] = 1; //标记已访问
while (p)
{
if (!visited[p->adjvex])//未被访问过
DFS(G, p->adjvex);
p = p->nextarc;
}
}
深度遍历适用哪些问题的求解。
深度遍历适用于解决访问初始点v后再访问与定点v相邻的顶点w,再以w为初始点去访问w的相邻点。可以找到两点之间的全部路径。例如迷宫、六度空间、全排列问题等。
eg.全排列问题:也就是深度遍历的思想,首先我们去第一个,然后访问下一个,然后再接下来一个。图解
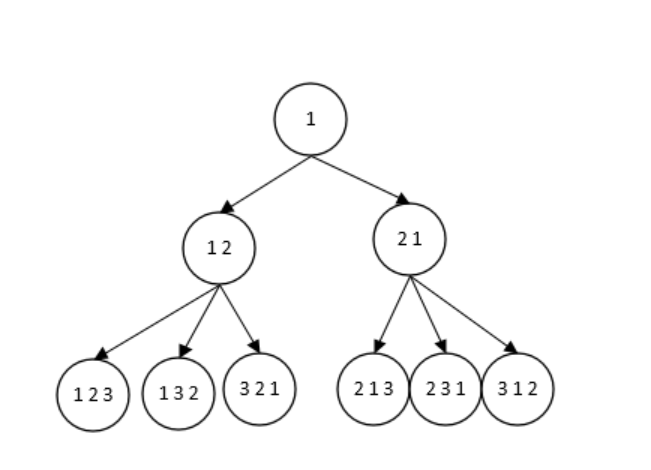
1.2.2 广度优先遍历
注:其主要思想类似于树的层序遍历。
无向图的广度优先遍历
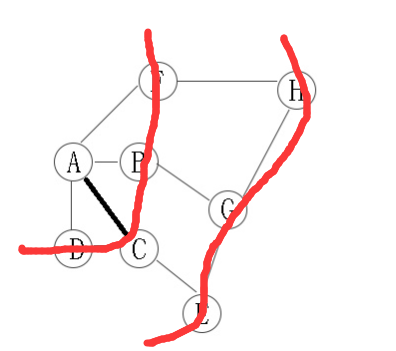
遍历顺序是:A -> B -> C -> D -> F -> G -> E -> H
从A开始,有4个邻接点,“B,C,D,F”,这是第二层;
在分别从B,C,D,F开始找他们的邻接点,为第三层。以此类推。

有向图的广度优先遍历
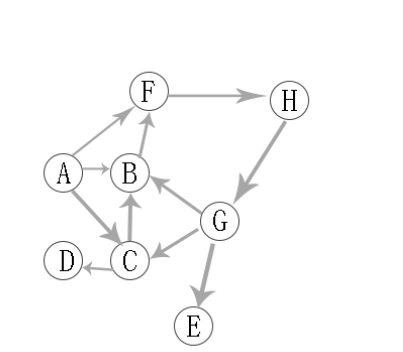
从A开始
遍历序列是:A -> B -> C -> F -> D -> H -> G-> E
广度遍历代码
- 邻接表
void BFS(AdjGraph* G, int v) //v节点开始广度遍历
{
queue<int>q;
ArcNode* node;
int n;//边的序号
int j;
visited[v] = 1;//表示已访问
cout << v ;
q.push(v);//入队
while (!q.empty())//队不空
{
j = q.front();
q.pop();
node = G->adjlist[j].firstarc;
while (node)//按邻接表输出头结点后的所有节点
{
if (!visited[node->adjvex])
{
visited[node->adjvex] = 1;
cout << " " << node->adjvex;
q.push(node->adjvex);
}
node = node->nextarc;
}
}
}
- 邻接矩阵
void BFS(MGraph g, int v)//邻接矩阵广度遍历
{
int t;
queue<int>q;
if (visited[v] == 0)
{
cout << v;
visited[v] = 1;
q.push(v);
}
while (!q.empty())
{
t = q.front();
q.pop();
for (int j = 1; j <= g.n; j++)
{
if (g.edges[t][j] == 1 && visited[j] == 0)
{
cout << " " << j;
visited[j] = 1;
q.push(j);
}
}
}
}
广度遍历适用哪些问题的求解。
广度遍历适用于先访问初始点v,接着访问顶点v的所有未被访问过的邻接点v1,v2...vt,然后再按v1,v2...vt的次序访问每一个顶点的所有未被访问过的邻接点。
可用于求解迷宫问题的最短路径。也可用于求不带权无向连通图中的两个顶点的最短路径、求不带权无向连通图中距离一个顶点v的最远顶点等等。
1.3 最小生成树
- 什么是最小生成树?
首先要知道,对于带权连通图G(每条边上的权均为大于零的实数),可能有多棵不同生成树。每棵生成树的所有边的权值之和可能不同,其中权值之和最小的生成树称为图的最小生成树。
最小生成树的顶点个数和其原来的图的顶点个数相等,边数为(n-1)。
最小生成树可以用于解决公路村村通的问题,使得在各村均连通的情况下所用的费用最少。
1.3.1 Prim算法求最小生成树
- Prim算法思想:
逐渐长成一棵最小生成树。假设G=(V,E)是连通无向网,T=(V,TE)是求得的G的最小生成树中边的集合,U是求得的G的最小生成树所含的顶点集。初态时,任取一个顶点u加入U,使得U={u},TE=Ø。重复下述操作:找出U和V-U之间的一条最小权的边(u,v),将v并入U,即U=U∪{v},边(u,v)并入集合TE,即TE=TE∪{(u,v)}。直到V=U为止。最后得到的T=(V,TE)就是G的一棵最小生成树。也就是说,用Prim求最小生成树是从一个顶点开始,每次加入一条最小权的边和对应的顶点,逐渐扩张生成的。
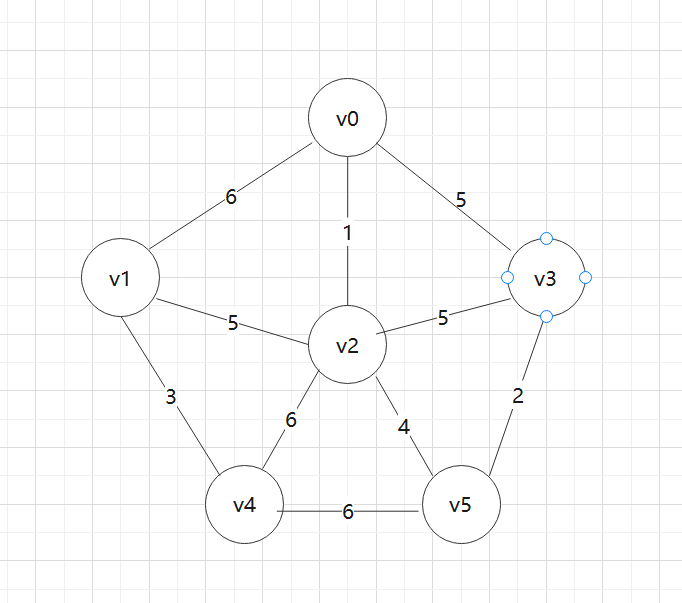
对应生成的最小生成树的边序列为:
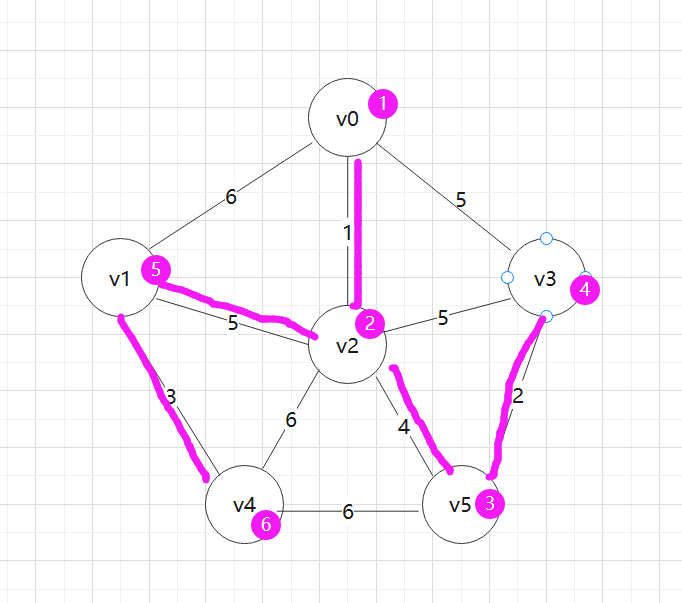
实现Prim算法的2个辅助数组
①closest[i]:最小生成树的边依附在U中顶点编号。
②lowcost[i]:表示顶点i(∈V-U)到U中顶点的边权重,取最小权重的顶点k加入U。并规定lowcost[k]=0表示这个顶点在U中
(closest[k],k)构造最小生成树一条边。
- Prim算法代码
#define INF 32767//INF表示∞
void Prim(Graph G,int v)
{
int lowcost[MAXV];
int min;
int closest[MAXV], i, j, k;
for (i=0;i<G.n;i++)//给lowcost[]和closest[]置初值
{
lowcost[i]=G.edges[v][i];
closest[i]=v;
}
for (i=1;i<G.n;i++)//输出(n-1)条边
{
min=INF;
for (j=0;j<G.n;j++) //在(V-U)中找出离U最近的顶点k
if (lowcost[j]!=0 && lowcost[j]<min)
{
min=lowcost[j];
k=j;//k记录最近顶点编号
}
lowcost[k]=0;//标记k已经加入U
for (j=0;j<G.n;j++)//修改数组lowcost和closest
if (lowcost[j]!=0 && G.edges[k][j]<lowcost[j])
{
lowcost[j]=G.edges[k][j];
closest[j]=k;
}
}
}
分析Prim算法时间复杂度,适用什么图结构,为什么?
- Prim算法时间复杂度为O(n²);
- Prim算法适用于邻接矩阵,因为要调用到权值,找到特定顶点间的权值。适用于边数较多的稠密图,其是通过比较边来找顶点,每次遍历找到一个顶点,与顶点个数无关。
1.3.2 Kruskal算法求解最小生成树
- 基本思想:
将所有顶点之间路径权值,从小到大有序排列,并在程序中优先遍历路径小的顶点,记录不存在环的路径,直至全部循环完毕。 - 关键:
1、将输入的边的顺序按边的权值从小到大排序。
2、在遍历的过程中判断是否生成环(难点)。
最小生成树的边序列如图:
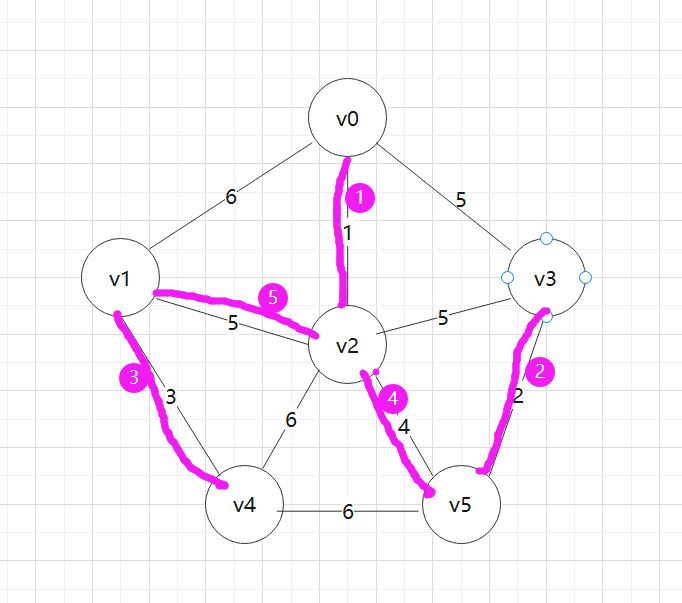
Q:实现Kruskal算法的辅助数据结构是什么?其作用是什么?
数组vest[MAXV],为集合辅助数组,用于记录起始点和终止点的下标,通过改变数组的值来改变顶点的所属集合。
- Kruskal算法代码。
typedef struct
{ int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
} Edge;
Edge E[MAXV];
void Kruskal(Graph G)
{
int i,j,u1,v1,sn1,sn2,k;
int vset[MAXV];
Edge E[MaxSize]; //存放所有边
k=0; //E数组的下标从0开始计
for (i=0;i<G.n;i++) //由G产生的边集E
for (j=0;j<G.n;j++)
if (G.edges[i][j]!=0 && G.edges[i][j]!=INF)
{
E[k].u=i; E[k].v=j; E[k].w=G.edges[i][j];
k++;
}
InsertSort(E,G.e); //用直接插入排序对E数组按权值递增排序
for (i=0;i<g.n;i++) //初始化辅助数组
vset[i]=i;
k=1; //k表示当前构造生成树的第几条边,初值为1
j=0; //E中边的下标,初值为0
while (k<G.n) //生成的边数小于n时循环
{
u1=E[j].u;v1=E[j].v; //取一条边的头尾顶点
sn1=vset[u1];
sn2=vset[v1]; //分别得到两个顶点所属的集合编号
if (sn1!=sn2) //两顶点属于不同的集合
{
k++; //生成边数增1
for (i=0;i<g.n;i++) //两个集合统一编号
if (vset[i]==sn2) //集合编号为sn2的改为sn1
vset[i]=sn1;
}
j++; //扫描下一条边
}
}
- 并查集改良Kruskal算法(时间复杂度是O(elog2e)):
typedef struct
{ int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
} Edge;
Edge E[MAXV];
void Kruskal(AdjGraph *g)
{ int i,j,u1,v1,sn1,sn2,k;
int vset[MAXV]; //集合辅助数组
Edge E[MaxSize]; //存放所有边
k=0; //E数组的下标从0开始计
for (i=0;i<g.n;i++) //由g产生的边集E,邻接表
{ p=g->adjlist[i].firstarc;
while(p!=NULL)
{ E[k].u=i;E[k].v=p->adjvex;
E[k].w=p->weight;
k++; p=p->nextarc;
}
}
Sort(E,g.e); //用快排对E数组按权值递增排序
for (i=0;i<g.n;i++) //初始化集合
vset[i]=i;
k=1; //k表示当前构造生成树的第几条边,初值为1
j=0; //E中边的下标,初值为0
while (k<g.n) //生成的顶点数小于n时循环
{
u1=E[j].u;v1=E[j].v; //取一条边的头尾顶点
sn1=vset[u1];
sn2=vset[v1]; //分别得到两个顶点所属的集合编号
if (sn1!=sn2) //两顶点属于不同的集合
{ printf(" (%d,%d):%d\n",u1,v1,E[j].w);
k++; //生成边数增1
for (i=0;i<g.n;i++) //两个集合统一编号
if (vset[i]==sn2) //集合编号为sn2的改为sn1
vset[i]=sn1;
}
j++; //扫描下一条边
}
}
分析Kruskal算法时间复杂度,适用什么图结构,为什么?
- Kruskal算法时间复杂度:O(elog₂e)。
- 适用于邻接表,因为其与n无关,只与e有关,适用于稀疏图。用邻接表的遍历方便找到两点之间的权值,也更加方便找到某点与其连通图的关系并比较权值。
1.4 最短路径
1.4.1 Dijkstra算法求解最短路径
- Dijkstra算法伪代码
初始化dist数组,path数组,s数组;
遍历图中所有结点
{
遍历dist数组,找为被s收入的距离源点最小的顶点w;
s[w]=1;//将w加入集合s;
for i=0 to g.n //修正未加入s集合的顶点的dist和path
若dist[i]>dist[w]+g.edges[w][i];
dist[i]=dist[w]+g.edges[w][i];
path[i]=w;
end for
}
- Dijkstra算法代码:
void Dijkstra(MatGraph g, int v)
{
int dist[MAXV],path[MAXV];
int s[MAXV];//s[i]=1表示顶点i在s中,s[i]=0表示顶点i在U中,即判断是否访问
int mindis, i, j, u;
for (i = 0; i < g.n; i++)
{
dist[i] = g.edges[v][i];//距离初始化
s[i] = 0;//s[]置空
if (g.edges[v]]i] < INF)//路径初始化
path[i] = v;//顶点v到顶点i有边时,置顶点i的前一个顶点为v
else
path[i] = -1;//顶点v到顶点i没边时,置顶点i的前一个顶点为-1
}
s[v] = 1;path[v]=0;//源点编号v放入s中
for (i = 0; i < g.n-1; i++)//循环直到所有顶点的最短路径都求出
{
MINdis = INF;//MINdis置最大长度初值
for (j = 0; j < g.n; j++)//找到最小路径的长度
{
if (s[j] == 0 && dist[j] < MINdis)
{
u = j;
MINdis = dist[j];
}
}
s[u] = 1;//顶点u加入S中
for (j = 0; j < g.n; j++)//修改改变结点后的路径长度
{
if (s[j] == 0)
{
if (g.edges[u][j] < INF&&dist[u] + g.edges[u][j] < dist[j])//修改此处可得到各种多种解法
{
dist[j] = dist[u] + g.edges[u][j];
path[j] = u;
}
}
}
}
Dispath(g,dist,path,s,v);//输出最短路径
}
所画图为:
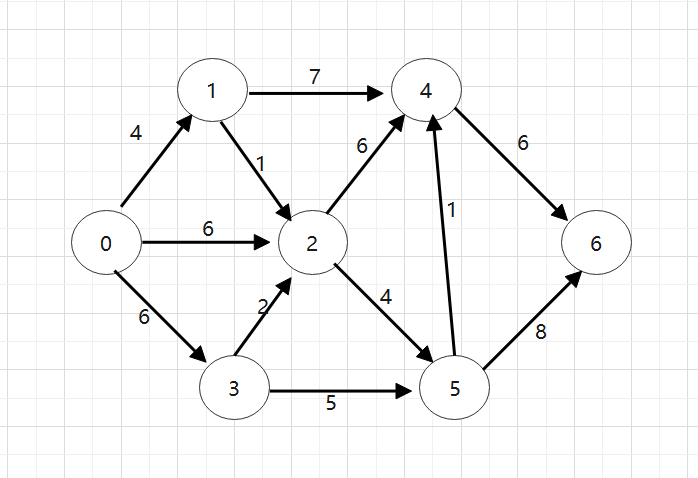
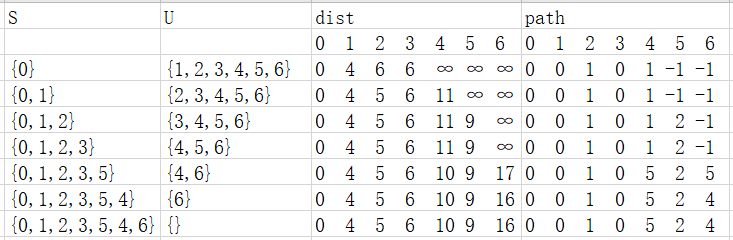
- 注:
①dist[]数组用于存放最短路径长度,通过改变path数组的值改变顶点的前继结点。例如dist[2]=12表示源点V0➡顶点2的最短路径长度为12。
②path[]数组用于存放最短路径。最短路径序列的前一个顶点的序号,初值或无路径用-1表示。例如从顶点0➡5的最短路径为0,2,3,5,表示为path[5]={0,2,3,5}。从源点到其他顶点的最短路径有n-1条,二维数组path[] []存储。
Dijkstra算法如何解决贪心算法无法求最优解问题?展示算法中解决的代码。
贪心算法无法求最优解问题,在该代码中dist[u]+g.edges[u][j]<dist[j]此处的小于号将该题的解法固定唯一,若改为<=号则会出现多种解法。
Dijkstra算法的时间复杂度,使用什么图结构,为什么。
1.时间复杂度为O(n²);
2.使用邻接矩阵存储。因为邻接矩阵方便通过下标找到顶点间权值并在数组中改变,若为邻接表则较难找到权值。
1.4.2 Floyd算法求解最短路径
- 伪代码
初始化二维数组A,二维数组path;
for k=0 to g.n
遍历二维数组A
将顶点k作为中间站,判断加入顶点k后的路径长度是否比原来小;
若 A[i][j]>A[i][k]+A[k][j]
修改A[i][j]=A[i][k]+A[k][j];
修改path[i][j]=k;
end for
- 具体算法代码:
void Floyd(MatGraph g)//Floyd算法
{
int A[MAXV][MAXV], path[MAXV][MAXV];
int i, j, k;
for (i = 0; i < g.n; i++)
for (j = 0; j < g.n; j++)
A[i][j] = g.edges[i][j];
if (i != j && g.edges[i][j] < INF)
path[i][i] = i;//顶点i到j有边时
else
path[i][i] = -1;//顶点i到j没有边时
{
for (k = 0; k < g.n; k++)//依次考查所有顶点
{
for (i = 0; i < g.n; i++)
for (j = 0; j < g.n; j++)
if (A[i][j] > A[j][k] + A[k][i])
{
A[D[] = A[i][K] + A[k][i]; //修改最短路径长度
path[i][j] = path[K][i]; //修改最短路径
}
}
}
Dispath(g,A,path);//输出最短路径
}
- Q1:Floyd算法解决什么问题?
求图的任两结点间的最短路径。 - Q2:Floyd算法需要哪些辅助数据结构?
Floyd需要A[][]和path[][]两个二维数组,其中A数组是用于存放两个顶点之间的最短路径,path数组用于存放其的前继结点。 - Q3:Floyd算法优势?
Floyd算法可以算出任意两个节点之间的最短距离,代码编写简单。Floyd算法适用于APSP(All Pairs Shortest Paths,多源最短路径),是一种动态规划算法,稠密图效果最佳,边权可正可负。此算法简单有效,由于三重循环结构紧凑,对于稠密图,效率要高于执行|V|次Dijkstra算法。
但是Floyd算法时间复杂度比较高,不适合计算大量数据。
1.5 拓扑排序
- 定义:在一个有向无环图中找一个拓扑序列的过程称为拓扑排序。
- 注意:有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序。
- 拓扑排序的应用:可以用来检测图中是否有回路。
- 序列必需满足的条件:
①每个顶点出现且只出现一次;
②若存在一条从顶点A到顶点B的路径,那么在序列中顶点A出现在顶点B的前面。
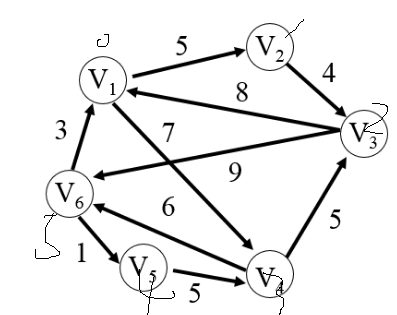
所画的有向图如下:
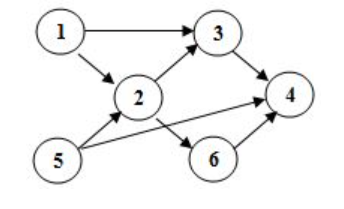
1.5.1上图对应的拓扑排序序列为:
序列1:1,5,2,3,6,4
序列2:5,1,2,6,3,4
序列3:5,1,2,3,6,4
易知:一个AOV-网的拓扑序列不是唯一的。
- 如何进行拓扑排序?
(拓扑排序每次找到入度为0为结点,每输出一个结点,其后续结点的入度减一,入度为0的结点进入栈或数组。)
⒈从有向图中选取一个没有前驱的顶点,并输出之;
⒉从有向图中删去此顶点以及所有以它为尾的弧;
⒊重复上述两步,直至图空,或者图不空但找不到无前驱的顶点为止。
1.5.2结构体设计(实现拓扑排序代码)
- 头结点结构体:
typedef struct //表头节点类型
{
vertex data; //顶点信息
int count; //存放顶点入度
ArcNode *firstarc; //指向第一条弧
}VNode;
1.5.3拓扑排序伪代码
遍历领接表
计算每个顶点的入度,存入头结点count成员
遍历图顶点
若发现入度为0的顶点,入栈st
while(栈不空)
{
出栈节点v,访问。
遍历v的所有领接点
{
所有领接点的入度为-1
若有领接点入度为0,则入栈st
}
}
注:
1.数组存放,插入删除操作比较复杂;
2.栈、队列保存,O(n+e)。
1.5.4如何用拓扑排序代码检查一个有向图是否有环路?
- 检测是否有环的办法:
使用邻接表;当某个顶点的入度为0时,输出顶点信息;设置栈来存放入度为0的顶点。
⑴对有向图构造其顶点的拓扑有序序列
⑵若网中所有顶点都在其拓扑有序序列中,则该AOV-网必定不存在环。 - 具体代码:
void TopSort(AdjGraph *G) //拓扑排序算法
{
int i,j;
int St[MAXV],top=-1; //栈St的指针为top
ArcNode *p;
for (i=0;i<G->n;i++) //入度置初值0
G->adjlist[i].count=0;
for (i=0;i<G->n;i++) //求所有顶点的入度
{
p=G->adjlist[i].firstarc;
while (p!=NULL)
{
G->adjlist[p->adjvex].count++;
p=p->nextarc;
}
}
for (i=0;i<G->n;i++) //将入度为0的顶点进栈
if (G->adjlist[i].count==0)
{
top++;
St[top]=i;
}
while (top>-1) //栈不空循环
{
i=St[top];top--; //出栈一个顶点i
printf("%d ",i); //输出该顶点
p=G->adjlist[i].firstarc; //找第一个邻接点
while (p!=NULL) //将顶点i的出边邻接点的入度减1
{
j=p->adjvex;
G->adjlist[j].count--;
if (G->adjlist[j].count==0) //将入度为0的邻接点进栈
{
top++;
St[top]=j;
}
p=p->nextarc; //找下一个邻接点
}
}
}
1.6 关键路径
关键路径是从有向图的源点(入度为0)到汇点(出度为0)的最长路径。
Q1:什么叫AOE-网?
AOE 网是在 AOV 网的基础上,其中每一个边都具有各自的权值,是一个有向无环网。其中权值表示活动持续的时间,用顶点表示事件,用有向边e表示活动,边的权c(e)表示活动持续时间。是带权的有向无环图。
⬜AOE-网图的意义:
- AOE-网-----带权的有向无环图;
- 顶点----事件或状态
- 弧(有向边)---活动及发生的先后关系
- 权----活动持续的时间
- 起点----入度为0的顶点(只有一个)
- 终点----初度为0的顶点(只有一个)
Q2:什么是关键路径概念?
关键路径是指有向图中从源点到汇点的最长路径。其中,关键路径中的边叫做关键活动。
求一个AOE的关键路径➡求AOE的中的关键活动。
求关键路径的步骤:
1.对有向图拓扑排序
2.根据拓扑序列计算事件(顶点)的ve(最早开始),vl(最迟开始)数组
ve(j)=Max{ve(i)+dut(<i,j>)}
vl(i)=Min{vl(j)-dut(<i,j>)}
3.计算关键活动的e[],l[]。即边的最早、最迟时间
e(i)=ve(j)
l(i)=vl(k)-dut(<j,k>)
4.找e=l边即为关键活动
5.关键活动连接起来就是关键路径。
Q3:什么是关键活动?
指的是关键路径中的边。
🔅2.PTA实验作业(4分)
2.1 六度空间(2分)
2.1.1 伪代码
#include<iostream>
#include<stdlib.h>
#include<stdio.h>
#include<queue>
#define maxv 10001
定义矩阵;
int main()
{
输入顶点数和边数
for(i=1;i<=e;i++)
{
输入数据对矩阵的元素进行修改;
}
for (i = 1; i <= n; i++)
{
初始化各点,将visited置0
node = BFS(i);
所占百分比node/n;
输出
}
}
int BFS(int i)//广度优先遍历
{
level//用于记录层数
count//用于记录每个结点的与该结点距离不超过6的结点数
last//用于标记每层最后一个结点,以便判断是否为该层最后一个
int tail,temp;
访问该结点并进队;
将访问过的结点的visited[]置为1
while (队不为空&&level小于6)
{
用temp保存队头元素
弹出队头元素;
for (遍历结点)
{
if (未访问过该结点且边存在)
{
count++;
访问进队;
置该结点的visited[]为1
tail记录此时结点;
}
}
if (last == temp)//为该层最后一个
{
层数加1
last = tail;//移动到下一层
}
}
return count;
}
2.1.2 提交列表

2.1.3 本题知识点
①需要借助队列来解决问题,类似于层次遍历
②需要借助数组visited[]来标记已经访问过的结点
③利用邻接矩阵进行广度遍历
④定义level,tail,last对层数进行判断,以及层数的改变
2.2 村村通或通信网络设计或旅游规划(2分)
村村通
2.2.1 伪代码
定义图的结构体;
void CreateMGraph(MatGraph*& g, int n, int e)//建图
{
for(i=0;i<=n;i++)
{
for(j=0;j<n;j++)
对矩阵初始化;(不能初始化为0,要初始化为最大值IFN)
}
for(i=1;i<=e;i++)
{
修改矩阵数据;
}
g->e = e;
g->n = n;
}
int Connect(MatGraph* g)
{
int lowcost[1005];//保存权值
int closet[];//保存顶点下标
int cost = 0,minn=IFN,k;
for(i=1;i<=g->n;i++)
{
给lowcost[i]置初值;
cosest[i] 置为1;
}
lowcost[1] = 0;
for(i=2;i<=q->n;i++)
{
minn = IFN;
for(j=1;j<=g->n;j++)
{
if(权值存在且权值小于minn)
{
让minn=此时权值;
k=j;//记录最近顶点的编号;
}
}
lowcost[k] = 0;//标记已经加入
for (int j = 1; j <= g->n; j++)
{
if (权值存在 && 权值 大于 此时指向的权值)
{
修正数组
}
}
}
for (int i = 1; i <= g->n; i++)
判断是否全部连接,若还有lowcost[i],则返回-1
if (lowcost[i])return -1;
返回 cost;
}
int main()
{
输入边数和顶点数;
CreateMGraph(g,n,e);//建图
if(数据不足以保证畅通)
输出-1;
else
输出Connect(g);
return 0;
}
2.2.2 提交列表

2.2.3 本题知识点
公路村村通实际上是求最小生成树的问题,即要求每个村庄之间必须可以连通但是长度要求最短。
①借助邻接矩阵进行存储数据
②借助Prim算法解决最小生成树的问题
③借助两个数组lowcost[]和closet[]分别保存权值和顶点下标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号