

抓包分析、多线程爬虫及xpath学习
1、抓包分析
1.1 Fiddler安装及基本操作
由于很多网站采用的是HTTPS协议,而fiddler默认不支持HTTPS,先通过设置使fiddler能抓取HTTPS网站,过程可参考(https://www.cnblogs.com/liulinghua90/p/9109282.html)。使用clear可以将当前fiddler清屏。
1.2 通过抓包爬取腾讯视频评论
unicode转码:在Python中转码可以直接输入u'需要转码的内容'
由于每个视频后面的评论需要自动加载,在源代码中未发现有关评论的相关链接,此时就需要使用fiddler进行抓包分析,打开视频网站后,可以先使用clear清屏,找到JS包,可以复制它的url,打开后发现评论都是使用的Unicode编码,此时就需要解码。由于需要自动加载后面的评论,此时需要分析网页的构成。再使用一次clear,在网页上点击加载更多评论,在fiddler中找到JS包,复制url,将之与之前的url进行对比,重复几次该操作,构造评论url。
下面给出爬取腾讯视频中权力的游戏第八季评论:

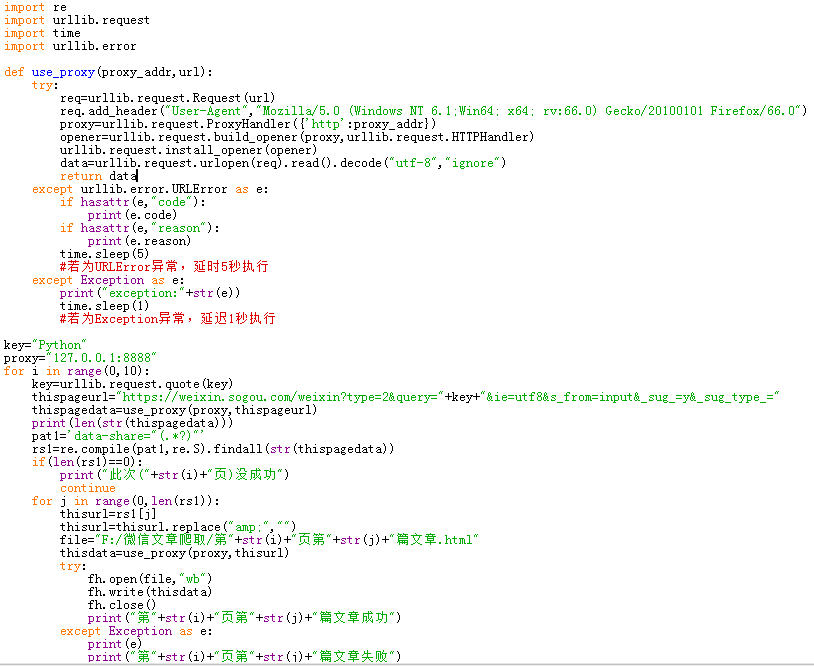
1.3 微信文章爬取
进入weixin.sougou.com,搜索关键词为“Python”,也采取抓包分析,不过增加了代理,其余操作步骤与1.2类似。
2、多线程爬虫
多线程,即程序中的某些程序段并行执行,合理地设置多线程,可以让爬虫的效率更高。

运行之后的结果为:

可以看出两个线程是同时开始工作的,那么如果用多线程爬取多个网页的话,就可以更加高效。下面将用多线程爬取糗事百科的文字内容:

首先需要分析网页的构造,通过翻页将规律找出来,实现在程序中实现自动翻页加载文本,其次需要将内容解码输出,最后需要加上异常处理。
3、scrapy xpath
/标签名:从顶端开始,如/html从顶端开始寻找html这个标签,找到的是这个标签内的内容
//标签名:寻找所有该标签
text():提取文本信息
@属性:提取属性信息
命令行输入:scrapy startproject 爬虫名,表示新建一个爬虫;如果新建一个自动爬虫,则先输入:scrapy startproject 爬虫名,再输入:scrapy genspider -t crawl 爬虫名 网址
items.py主要用来设置爬取的目标
pipelines.py设置后续的处理
settings.py主要用于配置信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号