prerender-SPA程序的SEO优化策略
2013-12-09 01:22 破狼 阅读(12154) 评论(3) 收藏 举报随着web2.0的兴起,ajax的时代已经成为了事实,更如今Knockout,backbone, angular,ember前端MDV(model driver view)框架强势而来,Single Page Application已经为大家所熟悉了。如今常见的SPA程序,restfull和前端MDV之类的框架能够实实在在的减少我们的代码开发量,让我更多的注意力关注在真正的业务逻辑上。在众多前端MDV框架从博客中可以看出来笔者还是钟爱于angular,然而服务端平台的选择的话:在.net平台笔者会首选webapi+oData,jvm平台spring restfull。
但是相应带来的是搜索引擎优化(SEO)是个难题,因为爬虫不会去执行JavaScript。现在很幸运的是在Google推出angular之后,也给出了一些解决方案:Google's ajax crawling protocol.此协议现在已被Google和bing所实现。
在协议中规定,搜索引擎会把带有#!someurl的链接转换为escaped_fragment=someurl访问解析,例如:
www.example.com/ajax.html#!key=value
将会变为
www.example.com/ajax.html?_escaped_fragment_=key=value
所以如果我们需要更好的SEO的支持的话,我们可以从现在开始把我们程序中的#变为#!,特别angular程序,因为框架原声支持对#!的解析。
基于这个协议和phantomjs(headless的浏览器内核)我们的SPA SEO工具 prerender(http://prerender.io/)应运而生,在官方和社区的支持下,现在已经有node.js express,ruby on rails,java,asp.net,php,python主流框架和nginx之类的支持。
prerender架构流程图如下:
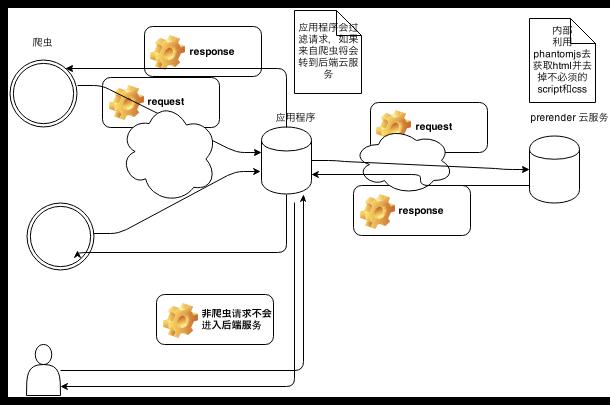
prerender分为两个部分一部分为后端云服务和应用程序客户端,客户端主要拦截来自爬虫的请求在转发到后端云服务处理返回处理后并且去掉多余script/css的html在返回给爬虫。
后端云服务(nodejs项目),利用phantomjs这个无ui headless的浏览器内核加载页面地址,并等到页面解析后获取document html,并处理去掉无用的部分返回到前段客户端程序。
而前段程序则为不同语言框架而实现的不同拦截器,如java的filter,asp.net mvc的HttpModule,主要任务为拦截请求并转发给后端云服务处理。其拦截规则为:
- 检查url中是否带有escaped_fragment或者请求user-agent是已知或者配置的爬虫user-agent
- 确认拦截的不是js,css之类的资源文件
- 在确认url是在白名单中(可选如果配置的白名单的话)
- 确认不应该在黑名单中(可选如果配置了黑名单的话)
注:最好值配置黑名单或者白名单中的一种方式。
有了prerender,因为SEO而放弃SPA不再是理由了,关于prerender的任何issue大家可以及时提出,让它更加完善。具体关于如何使用和测试请转向主页和各个client程序页面,http://prerender.io/
作者:破 狼
出处:http://www.cnblogs.com/whitewolf/
本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。该文章也同时发布在我的独立博客中-个人独立博客、博客园--破狼和51CTO--破狼。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号