kafka安装部署与使用
前言
1.kafka简介
Kafka是一个开源的分布式消息引擎/消息中间件,同时Kafka也是一个流处理平台。Kakfa支持以发布/订阅的方式在应用间传递消息,同时并基于消息功能添加了Kafka Connect、Kafka Streams以支持连接其他系统的数据(Elasticsearch、Hadoop等)
Kafka最核心的最成熟的还是他的消息引擎,所以Kafka大部分应用场景还是用来作为消息队列削峰平谷。另外,Kafka也是目前性能最好的消息中间件。
2.kafka架构
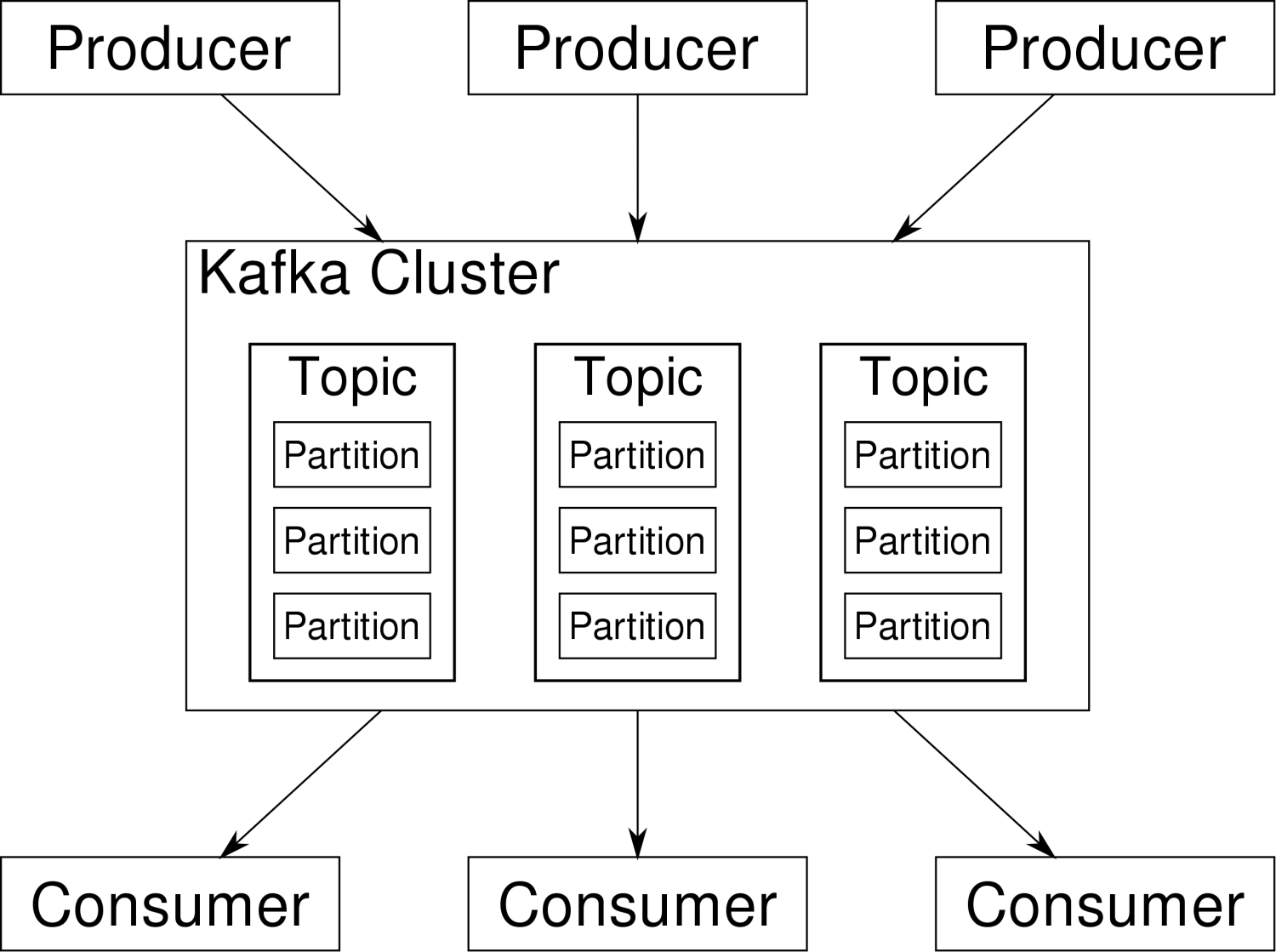
在Kafka集群(Cluster)中,一个Kafka节点就是一个Broker,消息由Topic来承载,可以存储在1个或多个Partition中。发布消息的应用为Producer、消费消息的应用为Consumer,多个Consumer可以促成Consumer Group共同消费一个Topic中的消息。
| 对象 | 简单说明 |
|---|---|
| Broker | Kafka节点 |
| Topic | 主题,用来承载消息 |
| Partition | 分区,用于主题分片存储 |
| Producer | 生产者,向主题发布消息的应用 |
| Consumer | 消费者,从主题订阅消息的应用 |
| Consumer Group | 消费者组,由多个消费者组成 |
1.环境准备
节点信息
| kafka节点1 | 192.168.11.128 |
|---|---|
| kafka节点2 | 192.168.11.129 |
| kafka节点3 | 192.168.11.130 |
zookeeper部署
https://www.cnblogs.com/whiteY/p/14898503.html
2.下载安装包
下载地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.4.1/

3.安装部署(所有节点都需要配置注意区分不同的broker.id)
3.1.创建kafka相关目录
应用路径
mkdir -p /usr/local/kafka
数据目录
mkdir -p /usr/local/kafka/kafka_log
3.2.解压压缩包到应用路径
tar -zxf kafka_2.13-3.4.1.tgz -C /usr/local/kafka/
3.3kafka节点配置
cd /usr/local/kafka/kafka_2.13-3.4.1/config
vi server.properties
通用配置
配置日志目录、指定ZooKeeper服务器
# A comma separated list of directories under which to store log files
log.dirs=/kafka/logs
# root directory for all kafka znodes.
zookeeper.connect=192.168.11.128:12181,192.168.11.129:12181,192.168.11.130:12181
分节点配置
#kafka节点1
broker.id=0
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://192.168.11.128:9092
#kafka节点2
broker.id=1
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://192.168.11.129:9092
#kafka节点3
broker.id=2
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://192.168.11.130:9092
4.启动kafka(三个节点都启动)
./bin/kafka-server-start.sh config/server.properties &
启动成功日志
[2023-08-30 22:58:40,558] INFO Kafka commitId: 8a516edc2755df89 (org.apache.kafka.common.utils.AppInfoParser)
[2023-08-30 22:58:40,558] INFO Kafka startTimeMs: 1693450720191 (org.apache.kafka.common.utils.AppInfoParser)
[2023-08-30 22:58:40,642] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
查看进程
[root@hadoop01 kafka_2.13-3.4.1]# jps
1926 QuorumPeerMain
11991 Jps
1640 SupportToolServer
11497 Kafka
You have new mail in /var/spool/mail/root
[root@hadoop01 kafka_2.13-3.4.1]#
5.kafka测试
5.1创建topic
#在kafka节点1(Broker)上创建测试Tpoic:test-ken-io,这里我们指定了3个副本、1个分区
bin/kafka-topics.sh --create --bootstrap-server 192.168.11.128:9092 --replication-factor 3 --partitions 1 --topic test-ken-io
##报错Exception in thread "main" joptsimple.UnrecognizedOptionException: bootstrap-server is not a recognized option 则需要替换参数
bin/kafka-topics.sh --create --zookeeper 192.168.11.128:2181 --replication-factor 3 --partitions 1 --topic test-ken-io
#Topic在kafka节点1上创建后也会同步到集群中另外两个Broker:kafka节点2、kafka节点3
5.2查看topic
[root@hadoop01 kafka_2.13-3.4.1]# ./bin/kafka-topics.sh --list --bootstrap-server 192.168.11.128:9092
test-ken-io
5.3发送消息
#这里我们向Broker(id=0)的Topic=test-ken-io发送消息
bin/kafka-console-producer.sh --broker-list 192.168.11.128:9092 --topic test-ken-io
#消息内容
> nihao
5.4消费消息
#在Kafka节点2上消费Broker03的消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.11.130:9092 --topic test-ken-io --from-beginning
#在Kafka节点3上消费Broker02的消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.11.129:9092 --topic test-ken-io --from-beginning
#然后均能收到消息
nihao
#这是因为这两个消费消息的命令是建立了两个不同的Consumer
#如果我们启动Consumer指定Consumer Group Id就可以作为一个消费组协同工,1个消息同时只会被一个Consumer消费到
bin/kafka-console-consumer.sh --bootstrap-server 192.168.11.130:9092 --topic test-ken-io --from-beginning --group testgroup_ken
bin/kafka-console-consumer.sh --bootstrap-server 192.168.11.129:9092 --topic test-ken-io --from-beginning --group testgroup_ken
#现在发现在kafka节点1上生产数据只有一个消费者可以拿到数据
6.备注
Kafka常用配置项说明
| 配置项 | 默认值/示例值 | 说明 |
|---|---|---|
| broker.id | 0 | Broker唯一标识 |
| listeners | PLAINTEXT://192.168.11.128:9092 | 监听信息,PLAINTEXT表示明文传输 |
| log.dirs | /usr/local/kafka/kafka_log | kafka数据存放地址,可以填写多个。用","间隔 |
| message.max.bytes | message.max.bytes | 单个消息长度限制,单位是字节 |
| num.partitions | 1 | 默认分区数 |
| log.flush.interval.messages | Long.MaxValue | 在数据被写入到硬盘和消费者可用前最大累积的消息的数量 |
| log.flush.interval.ms | Long.MaxValue | 在数据被写入到硬盘前的最大时间 |
| log.flush.scheduler.interval.ms | Long.MaxValue | 检查数据是否要写入到硬盘的时间间隔 |
| log.retention.hours | 24 | 控制一个log保留时间,单位:小时 |
| zookeeper.connect | 192.168.11.128:12181,192.168.11.129:12181,192.168.11.130:12181 | ZooKeeper服务器地址,多台用","间隔 |
7.kafka 管控平台推荐
Know Streaming
Know Streaming 是一套云原生的 Kafka 管控平台,脱胎于众多互联网内部多年的 Kafka 运营实践经验,专注于 Kafka 运维管控、监控告警、资源治理、多活容灾等核心场景,在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供
一系列特色的功能,极大地方便了用户和运维人员的日常使用,让普通运维人员都能成为 Kafka 专家。
本文来自博客园,作者:whiteY,转载请注明原文链接:https://www.cnblogs.com/whiteY/p/17669222.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号