Code of Transformer 学习
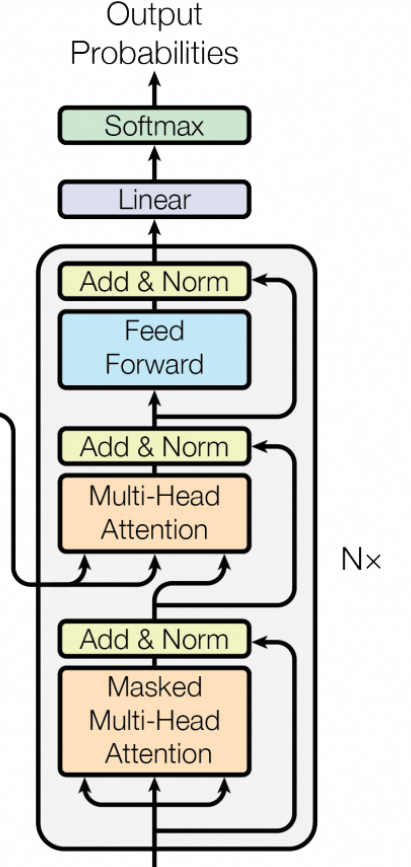
Transformer整体架构图
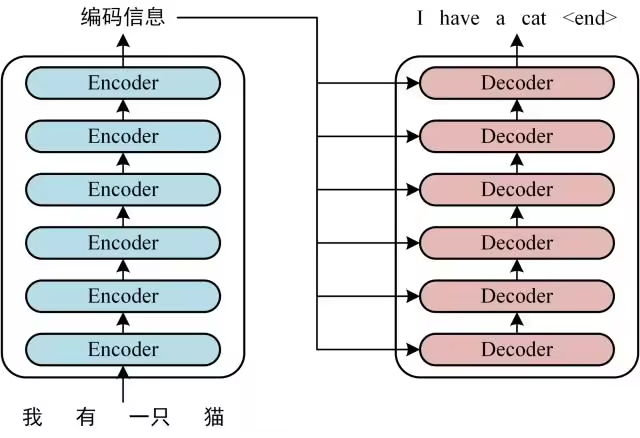
从上图可发现,该Transformer主要由Encoder和Decoder组成,Encoder和Decoder各6层,代码实现如下:
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
其中会涉及
- src_vocab: 源语言词汇表大小
- tgt_vocab: 目标语言词汇表大小
- N: 编码器/解码器堆叠层数(默认6层)
- d_model:模型维度(默认512)
- d_ff: 前馈网络内部维度(默认2048)
- h: 多头注意力头数(默认8)
- dropout: Dropout概率(默认0.1)
Encoder 结构
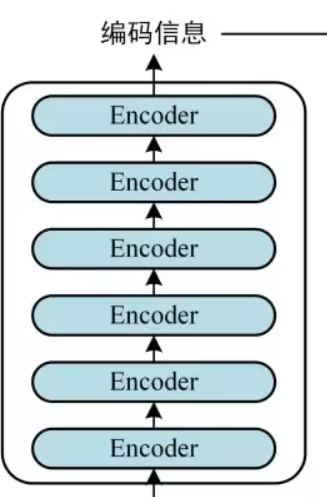
Encoder的实现
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
- N 层 Encoder 的实现
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
在每个子层使用残差连接,然后是层归一化
归一化实现:
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
单个Encoder的实现:
外部调用情况如下:
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N)
Encoder和Decoder的结构如下:
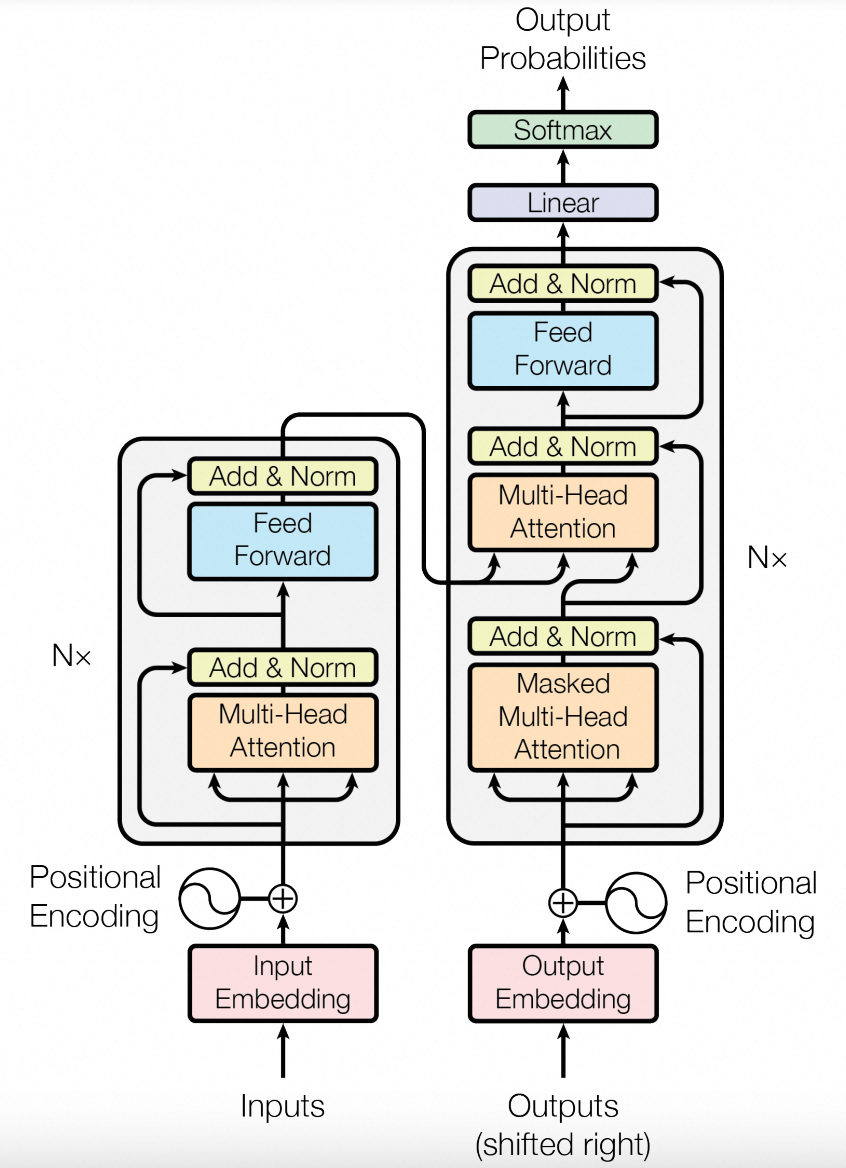
EncoderLayer的实现(上图左边部分):
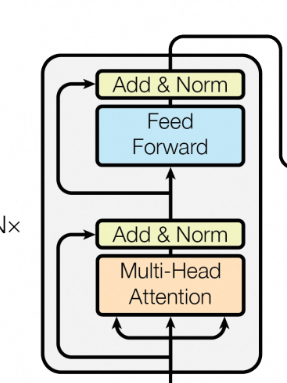
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
其中,包含 残差连接+正则化(SublayerConnection)、多头注意力、前馈神经网络
- 残差连接+正则化
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
- 多头注意力层
注意力机制
输入由维度为\(d_k\)的"询问"和“键”以及维度为\(d_v\)的”值“组成。计算"询问"与"键"的点积,将每个点积除以\(\sqrt{(d_k)}\),并应用softmax函数以获得值的权重
![image]()
在实践中,同时对一组"询问"进行注意力计算,将它们打包成一个矩阵Q。"键"和"值"也被打包到矩阵K和V中。我们计算输出矩阵如下:
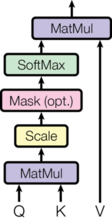
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
多头注意力

两个最常用的注意力函数是加性注意力和点积(乘性)注意力。
除了使用到了缩放因子\(\frac{1}{\sqrt{d_k}}\),算法与点积注意力相同。加性注意力使用具有一个隐藏层的前馈网络计算相关性函数。
在理论复杂度上,这两种注意力机制是相似的,但是在实践中,点积注意力更快,更节省空间,因为它可以使用高度优化的矩阵乘法代码实现。
当\(d_k\)的值较小时,这两种机制的表现相似,但是对于较大的\(d_k\)值,加性注意力在没有缩放的情况下优于点积注意力(参考资料)。
多头注意力允许模型同时关注不同位置的元素间的不同特征。使用单个注意力头,会抑制这种效果
其中,\(W_i^Q\in\mathbb{R}^{d_{model} \times d_k}\),\(W_i^K\in\mathbb{R}^{d_{model} \times d_k}\),\(W_i^V\in\mathbb{R}^{d_{model} \times d_v}\)and \(W^O\in\mathbb{R}^{hd_v \times d_{model}}\)
使用了\(h=8\)个并行的注意力头。对于每一个头,\(d_k = d_v = d_{model}/h = 64\)(其实就是把512维的词元分成8份,用8个不同的头计算,最后再把结果拼接在一起,很多代码和博客认为是复制8份)。由于每个头的维度减小,总的计算成本与完全维度的单头注意力相似。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)
Decoder结构
解码器也是一个由N = 6个相同层堆叠而成的模型。
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
除了每个编码器层中的两个子层外,解码器还插入了第三个子层(其实是图中夹在中间那层),该子层对编码器的输出执行多头注意力。 与编码器类似,我们在每个子层使用残差连接,然后进行层归一化。。
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
修改了解码器堆栈中的自注意力层,以防止后续位置的信息也参与运算(Transformer的解码器是自回归的,在训练过程中会将完整的目标输入解码器中进行训练,但是实际推理过程中我们无法提前获得目标序列,所以训练过程中使用掩码对还没推理出的元素的位置进行遮挡)。 除了使用掩码,输入的目标序列还会右偏一个位置,确保位置i的预测只能依赖于小于i的位置的已知输出
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0
位置相关的前馈神经网络
除了多头注意力层外,我们的每一个编码器和解码器还包含一个全连接的前馈网络,它对每个位置进行相同的操作。这个网络由两个线性变换和一个ReLU激活函数组成。
虽然线性变换在不同位置上是相同的(就算前馈网络其实是对一个一个词元作用的,与序列无关),但是它们在不同层之间使用不同的参数。另一种描述这个过程的方法是两个卷积核大小为1的卷积(就是改变维度的那种)。输入和输出的维度是
\(d_{model} = 512\),内层的维度是\(d_{ff}=2048\)
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))
词嵌入和softmax
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
位置编码
模型不包含卷积或循环结构,为了让模型利用序列的顺序消息,我们必须注入一些有关位置的信息到序列的每一个词元中。为了达到这个目的,我们向串联的编码器和解码器与嵌入层中间添加了位置编码层。位置编码的维度与词元的维度相同,都为\(d_{model}\),这样两者可以相加。
使用不同频率的正弦和余弦函数(就是固定的位置编码)
其中 \(pos\)是序列中位置的编号,\(i\)是词元中维度的编号。也就是说,位置编码让每个维度都对应了一个正弦波。波长从\(2\pi\) 到 \(10000 \cdot2\pi\)不等,形成一个几何级数。我们选择这个函数是因为我们假设它可以让模型很容易学习到位置的相对关系,因为对于任何固定的偏移 \(k\), \(PE_{pos+k}\)都可以由\(PE_{pos}\)线性变换而来。
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
至此,Transformer中的核心实现都已实现,下面来看下如何使用这个模型进行推理和训练
推理
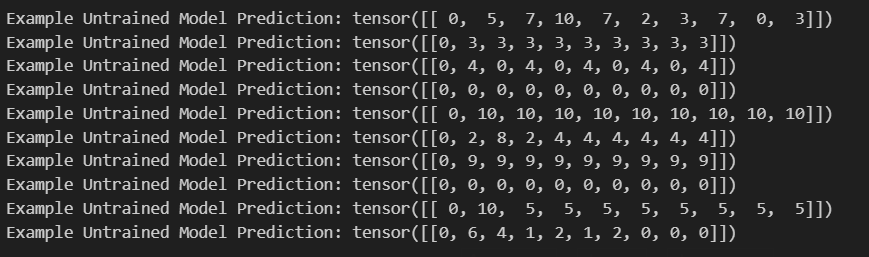
def inference_test():
test_model = make_model(11, 11, 2)
test_model.eval()
src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])
src_mask = torch.ones(1, 1, 10)
memory = test_model.encode(src, src_mask)
ys = torch.zeros(1, 1).type_as(src)
for i in range(9):
out = test_model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = test_model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
print("Example Untrained Model Prediction:", ys)
def run_tests():
for _ in range(10):
inference_test()
show_example(run_tests)
训练
class Batch:
"""用于在训练过程中生成带掩码的批数据的对象"""
def __init__(self, src, tgt=None, pad=2): # 2 = <blank>
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if tgt is not None:
self.tgt = tgt[:, :-1]
self.tgt_y = tgt[:, 1:]
self.tgt_mask = self.make_std_mask(self.tgt, pad)
self.ntokens = (self.tgt_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"构造一个掩码去挡住pad词元和尚未生成的词元。"
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
) # 这里利用到了广播机制
return tgt_mask
训练代码:
class TrainState:
"""记录计算过的步数,样例数和词元数"""
step: int = 0 # 当前轮的步数
accum_step: int = 0 # 优化器调整参数的次数
samples: int = 0 # 处理过的样例数
tokens: int = 0 # 处理过的词元数
def run_epoch(
data_iter,
model,
loss_compute,
optimizer,
scheduler,
mode="train",
accum_iter=1,
train_state=TrainState(),
):
"""训练单轮"""
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
n_accum = 0
for i, batch in enumerate(data_iter):
out = model.forward(
batch.src, batch.tgt, batch.src_mask, batch.tgt_mask
)
loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens)
# loss_node = loss_node / accum_iter
if mode == "train" or mode == "train+log":
loss_node.backward()
train_state.step += 1
train_state.samples += batch.src.shape[0]
train_state.tokens += batch.ntokens
if i % accum_iter == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
scheduler.step()
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 40 == 1 and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]
elapsed = time.time() - start
print(
(
"Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (i, n_accum, loss / batch.ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0
del loss
del loss_node
return total_loss / total_tokens, train_state
第一个例子
- 生成数据
def data_gen(V, batch_size, nbatches):
"Generate random data for a src-tgt copy task."
for i in range(nbatches):
data = torch.randint(1, V, size=(batch_size, 10))
data[:, 0] = 1
src = data.requires_grad_(False).clone().detach()
tgt = data.requires_grad_(False).clone().detach()
yield Batch(src, tgt, 0)
- 损失计算
class SimpleLossCompute:
"A simple loss compute and train function."
def __init__(self, generator, criterion):
self.generator = generator
self.criterion = criterion
def __call__(self, x, y, norm):
x = self.generator(x)
sloss = (
self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)
)
/ norm
)
return sloss.data * norm, sloss
- 贪心解码
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
out = model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ys
def example_simple_model():
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
)
batch_size = 80
for epoch in range(20):
model.train()
run_epoch(
data_gen(V, batch_size, 20),
model,
SimpleLossCompute(model.generator, criterion),
optimizer,
lr_scheduler,
mode="train",
)
model.eval()
run_epoch(
data_gen(V, batch_size, 5),
model,
SimpleLossCompute(model.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)[0]
model.eval()
src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len)
print(greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0))
真实的例子
# Load spacy tokenizer models, download them if they haven't been
# downloaded already
import spacy
import os
def load_tokenizers():
try:
spacy_de = spacy.load("de_core_news_sm")
except IOError:
os.system("python -m spacy download de_core_news_sm")
spacy_de = spacy.load("de_core_news_sm")
try:
spacy_en = spacy.load("en_core_web_sm")
except IOError:
os.system("python -m spacy download en_core_web_sm")
spacy_en = spacy.load("en_core_web_sm")
return spacy_de, spacy_en
from torchtext.vocab import build_vocab_from_iterator
import torchtext.datasets as datasets
from os.path import exists
from torchtext.datasets import Multi30k, multi30k
def is_interactive_notebook():
return __name__ == "__main__"
def build_vocabulary(spacy_de, spacy_en):
def tokenize_de(text):
return tokenize(text, spacy_de)
def tokenize_en(text):
return tokenize(text, spacy_en)
from torchtext.datasets import multi30k, Multi30k
multi30k.URL["train"] = "https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/training.tar.gz"
multi30k.URL["valid"] = "https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/validation.tar.gz"
multi30k.URL["test"] = "https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/mmt16_task1_test.tar.gz"
multi30k.MD5 = {
"train": "20140d013d05dd9a72dfde46478663ba05737ce983f478f960c1123c6671be5e",
"valid": "a7aa20e9ebd5ba5adce7909498b94410996040857154dab029851af3a866da8c",
"test": "6d1ca1dba99e2c5dd54cae1226ff11c2551e6ce63527ebb072a1f70f72a5cd36",
}
train = datasets.Multi30k(split='train', language_pair=('de', 'en'))
val = datasets.Multi30k(split='valid', language_pair=('de', 'en'))
test = datasets.Multi30k(split='test', language_pair=('de', 'en'))
print("Building German Vocabulary ...")
train, val, test = datasets.Multi30k(language_pair=("de", "en"))
vocab_src = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_de, index=0),
min_freq=2,
specials=["<s>", "</s>", "<blank>", "<unk>"],
)
print("Building English Vocabulary ...")
train, val, test = datasets.Multi30k(language_pair=("de", "en"))
vocab_tgt = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_en, index=1),
min_freq=2,
specials=["<s>", "</s>", "<blank>", "<unk>"],
)
vocab_src.set_default_index(vocab_src["<unk>"])
vocab_tgt.set_default_index(vocab_tgt["<unk>"])
return vocab_src, vocab_tgt
def load_vocab(spacy_de, spacy_en):
if not exists("vocab.pt"):
vocab_src, vocab_tgt = build_vocabulary(spacy_de, spacy_en)
torch.save((vocab_src, vocab_tgt), "vocab.pt")
else:
vocab_src, vocab_tgt = torch.load("vocab.pt")
print("Finished.\nVocabulary sizes:")
print(len(vocab_src))
print(len(vocab_tgt))
return vocab_src, vocab_tgt
if is_interactive_notebook():
# global variables used later in the script
spacy_de, spacy_en = show_example(load_tokenizers)
vocab_src, vocab_tgt = show_example(load_vocab, args=[spacy_de, spacy_en])
def collate_batch(
batch,
src_pipeline,
tgt_pipeline,
src_vocab,
tgt_vocab,
device,
max_padding=128,
pad_id=2,
):
bs_id = torch.tensor([0], device=device) # <s> token id
eos_id = torch.tensor([1], device=device) # </s> token id
src_list, tgt_list = [], []
for (_src, _tgt) in batch:
processed_src = torch.cat(
[
bs_id,
torch.tensor(
src_vocab(src_pipeline(_src)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
processed_tgt = torch.cat(
[
bs_id,
torch.tensor(
tgt_vocab(tgt_pipeline(_tgt)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
src_list.append(
# warning - overwrites values for negative values of padding - len
pad(
processed_src,
(
0,
max_padding - len(processed_src),
),
value=pad_id,
)
)
tgt_list.append(
pad(
processed_tgt,
(0, max_padding - len(processed_tgt)),
value=pad_id,
)
)
src = torch.stack(src_list)
tgt = torch.stack(tgt_list)
return (src, tgt)
from torchtext.data.functional import to_map_style_dataset
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
def create_dataloaders(
device,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=12000,
max_padding=128,
is_distributed=True,
):
# def create_dataloaders(batch_size=12000):
def tokenize_de(text):
return tokenize(text, spacy_de)
def tokenize_en(text):
return tokenize(text, spacy_en)
def collate_fn(batch):
return collate_batch(
batch,
tokenize_de,
tokenize_en,
vocab_src,
vocab_tgt,
device,
max_padding=max_padding,
pad_id=vocab_src.get_stoi()["<blank>"],
)
train_iter, valid_iter, test_iter = datasets.Multi30k(
language_pair=("de", "en")
)
train_iter_map = to_map_style_dataset(
train_iter
) # DistributedSampler needs a dataset len()
train_sampler = (
DistributedSampler(train_iter_map) if is_distributed else None
)
valid_iter_map = to_map_style_dataset(valid_iter)
valid_sampler = (
DistributedSampler(valid_iter_map) if is_distributed else None
)
train_dataloader = DataLoader(
train_iter_map,
batch_size=batch_size,
shuffle=(train_sampler is None),
sampler=train_sampler,
collate_fn=collate_fn,
)
valid_dataloader = DataLoader(
valid_iter_map,
batch_size=batch_size,
shuffle=(valid_sampler is None),
sampler=valid_sampler,
collate_fn=collate_fn,
)
return train_dataloader, valid_dataloader
def train_worker(
gpu,
ngpus_per_node,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
config,
is_distributed=False,
):
print(f"Train worker process using GPU: {gpu} for training", flush=True)
torch.cuda.set_device(gpu)
pad_idx = vocab_tgt["<blank>"]
d_model = 512
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
model.cuda(gpu)
module = model
is_main_process = True
if is_distributed:
dist.init_process_group(
"nccl", init_method="env://", rank=gpu, world_size=ngpus_per_node
)
model = DDP(model, device_ids=[gpu])
module = model.module
is_main_process = gpu == 0
criterion = LabelSmoothing(
size=len(vocab_tgt), padding_idx=pad_idx, smoothing=0.1
)
criterion.cuda(gpu)
train_dataloader, valid_dataloader = create_dataloaders(
gpu,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=config["batch_size"] // ngpus_per_node,
max_padding=config["max_padding"],
is_distributed=is_distributed,
)
optimizer = torch.optim.Adam(
model.parameters(), lr=config["base_lr"], betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, d_model, factor=1, warmup=config["warmup"]
),
)
train_state = TrainState()
for epoch in range(config["num_epochs"]):
if is_distributed:
train_dataloader.sampler.set_epoch(epoch)
valid_dataloader.sampler.set_epoch(epoch)
model.train()
print(f"[GPU{gpu}] Epoch {epoch} Training ====", flush=True)
_, train_state = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in train_dataloader),
model,
SimpleLossCompute(module.generator, criterion),
optimizer,
lr_scheduler,
mode="train+log",
accum_iter=config["accum_iter"],
train_state=train_state,
)
GPUtil.showUtilization()
if is_main_process:
file_path = "%s%.2d.pt" % (config["file_prefix"], epoch)
torch.save(module.state_dict(), file_path)
torch.cuda.empty_cache()
print(f"[GPU{gpu}] Epoch {epoch} Validation ====", flush=True)
model.eval()
sloss = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in valid_dataloader),
model,
SimpleLossCompute(module.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)
print(sloss)
torch.cuda.empty_cache()
if is_main_process:
file_path = "%sfinal.pt" % config["file_prefix"]
torch.save(module.state_dict(), file_path)
from torchtext.data.functional import to_map_style_dataset
import torch.multiprocessing as mp
import time
def train_distributed_model(vocab_src, vocab_tgt, spacy_de, spacy_en, config):
import train_worker
ngpus = torch.cuda.device_count()
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12356"
print(f"Number of GPUs detected: {ngpus}")
print("Spawning training processes ...")
mp.spawn(
train_worker,
nprocs=ngpus,
args=(ngpus, vocab_src, vocab_tgt, spacy_de, spacy_en, config, True),
)
def train_model(vocab_src, vocab_tgt, spacy_de, spacy_en, config):
if config["distributed"]:
train_distributed_model(
vocab_src, vocab_tgt, spacy_de, spacy_en, config
)
else:
train_worker(
0, 1, vocab_src, vocab_tgt, spacy_de, spacy_en, config, False
)
def load_trained_model():
config = {
"batch_size": 16,
"distributed": False,
"num_epochs": 8,
"accum_iter": 10,
"base_lr": 1.0,
"max_padding": 72,
"warmup": 3000,
"file_prefix": "multi30k_model_",
}
model_path = "multi30k_model_final.pt"
if not exists(model_path):
train_model(vocab_src, vocab_tgt, spacy_de, spacy_en, config)
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
model.load_state_dict(torch.load("multi30k_model_final.pt"))
return model
if is_interactive_notebook():
model = load_trained_model()

参考:https://www.cnblogs.com/Icys/p/18119309/annotated-transformer-chinese

 浙公网安备 33010602011771号
浙公网安备 33010602011771号