

基于AutoDL 进行 Llama_Factory+LoRA大模型微调
其实这个环境的搭建比较容易,但是其中出现在AutoDL上访问WebUI界面是无法访问的,对该问题查阅了一些资料并记录.
1. 环境的配置及其校验
Step 1. 使用Conda 创建LLaMA-Factory的python虚拟环境
conda create -n llama_factory python==3.11
创建完成后,通过如下命令进入该虚拟环境,执行后续的操作
conda activate llama_factory
Step2. 根据CUDA版本要求安装Pytorch
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
Step 3. 验证GPU版本的Pytorch是否成功
python -c "import torch; print(torch.cuda.is_available())"
若输出是True,则表示GPU版本的Pytorch已经安装承购并且可以使用CUDA,如果输出是False,则表明没有安装GPU版本的Pytorch,或者CUDA环境没有正确配置。
Step 4. 下载LLaMA-Factory的项目文件
进入LLaMA-Factroy的官方Github,地址为:https://github.com/hiyouga/LLaMA-Factory,在Github上将项目文件下载下来:可以通过clone或者下载zip压缩包两种方式。
首先,安装git软件包:
sudo apt install git
然后clone命令,将LLaMA-Factroy github上的项目下载下来
git clone https://github.com/hiyouga/LLaMA-Factory.git
接下来,解压缩LLaMA-Factory-main.zip文件
unzip LLaMA-Factory-main.zip
重命名LLaMA-Factory-main为LLaMA-Factory
mv LLaMA-Factory-main LLaMA-Factory
Step 5. 升级pip版本
python -m pip install --upgrade pip
Step 6. 使用pip安装LLaMA-Facory项目代码运行的项目依赖
# 进入文件夹 cd LLaMA-Factory #找到requirements.txt文件 pip install -e '.[torch,metrics]' -i https://pypi.tuna.tsinghua.edu.cn/simple/
接下来对环境进行整体校验
整体校验1 import torch torch.cuda.current_device() torch.cuda.get_device_name(0) torch.__version__
'''
'torch.cuda.get_device_name(0)': 返回索引为 0 的 CUDA 设备名称。
'''
整体校验2
lamafactory-cli train -h
2. 使用LLaMA Board微调Qwen2.5模型
Step1. 下载模型(以Qwen2.5 1.5B为例):
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct
若出现以下问题:
-bash: modelscope: command not found
则执行以下命令安装modelscope库即可:
pip install modelscope
如果在当前目录下找不到,去指定默认路径寻找:/root/.cache/modelscope/hub/
然后将文件移动到指定目录下:
mv /root/.cache/modelscope/hub/Qwen /home/zx/zxmodel
Step2. 启动对话窗口验证模型是否完整
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat --model_name_or_path /home/zx/zxmodel/Qwen/Qwen2___5-1___5B-Instruct --template qwen
上述命令中,CUDA_VISIBLE_DEVICES指定当前程序使用的是第0张卡;model_name_path参数为huggingface或者modelscope上的标准定义,如“meta-llama/Meta-Llama-3-8B-Instruct”或者本地下载模型的绝对路径;template 模型问答时所使用的prompt模板,不同模型不同,参考 https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#supported-models 获取不同模型的模板定义,否则会回答结果会很奇怪或导致重复生成等现象的出现。
通过上述命令启动成功后访问指定端口

但是在autodl中,会出现以下情况:
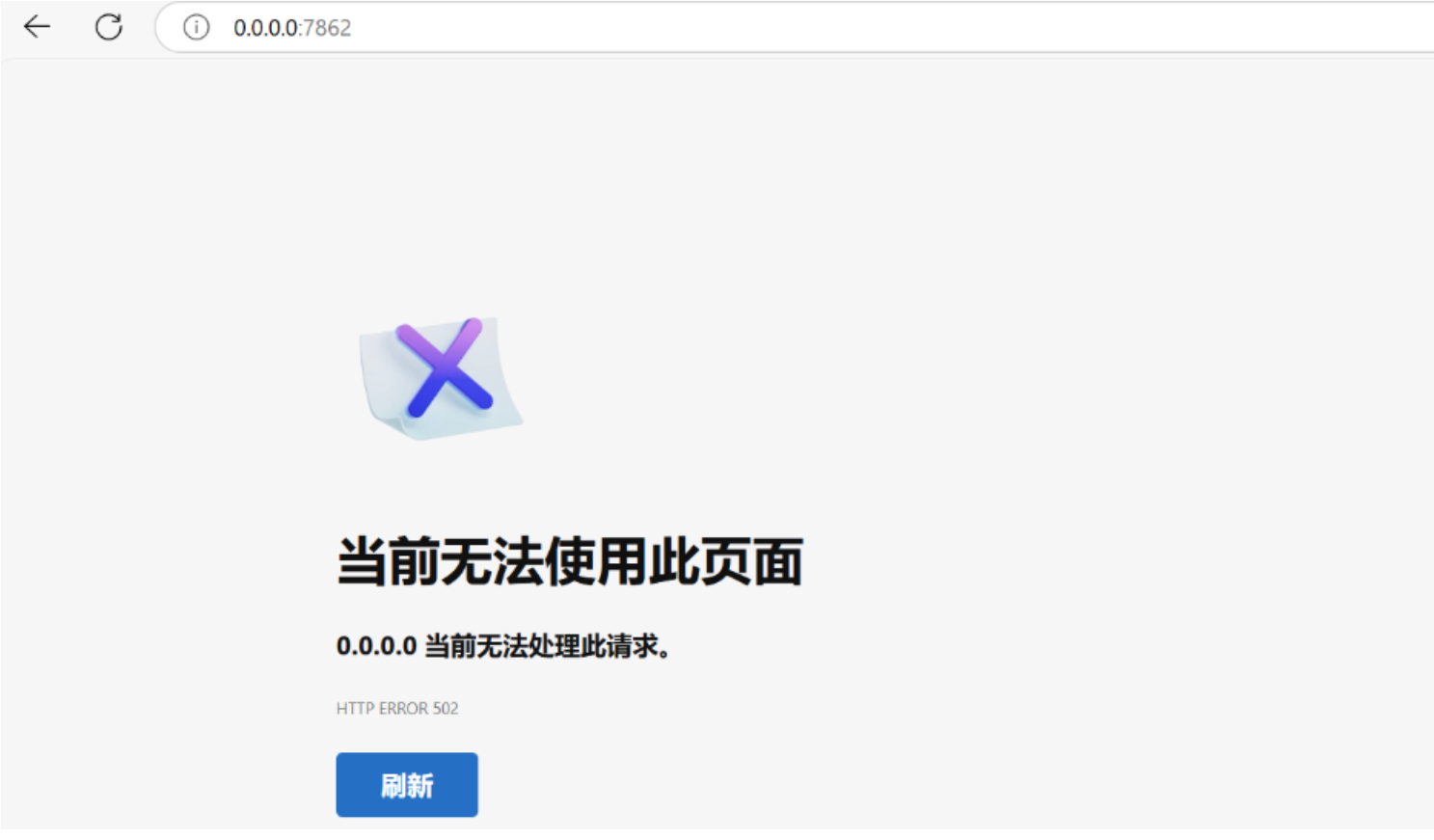
原因为:
AutoDL 不支持创建 share 链接,需要映射端口到 6006 并且在控制台开启外部访问
解决办法:
1.修改LLaMA-Factory/src/llamafactory/webui/interface.py文件中的run_web_ui函数为share=True
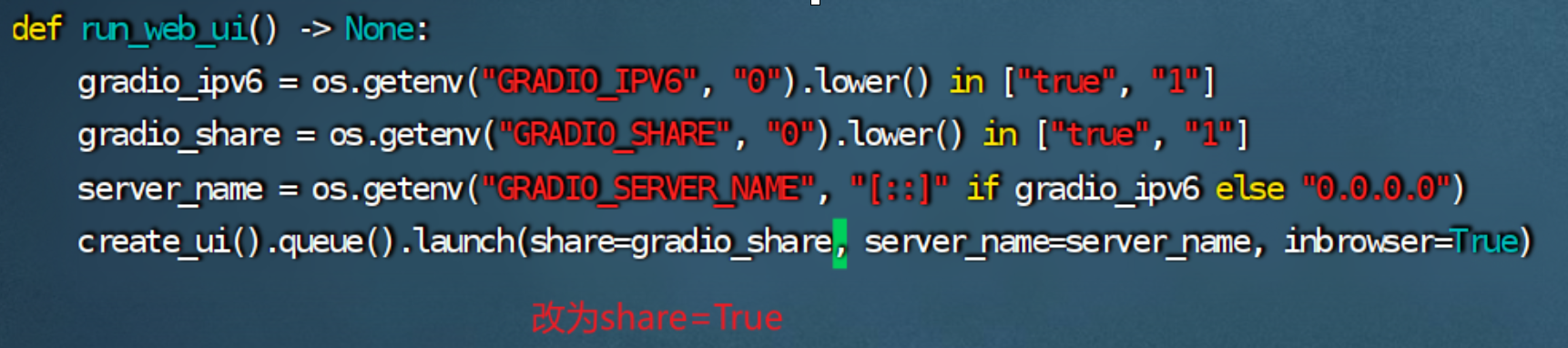
2.运行llamafactory-cli webui命令,在运行lamafactory-cli webui命令时出现以下情况:

对于该问题,接下来根据如上图所示指示下载对应的文件,对该文件重命名,然后放在相应的文件夹下,对此文件执行chmod +x frpc_linux_amd64_v0.2命令赋予权限
最后,重新执行llamafactory-cli webui命令,如下图所示会生成两个链接

使用第二个public URL,即可访问页面:
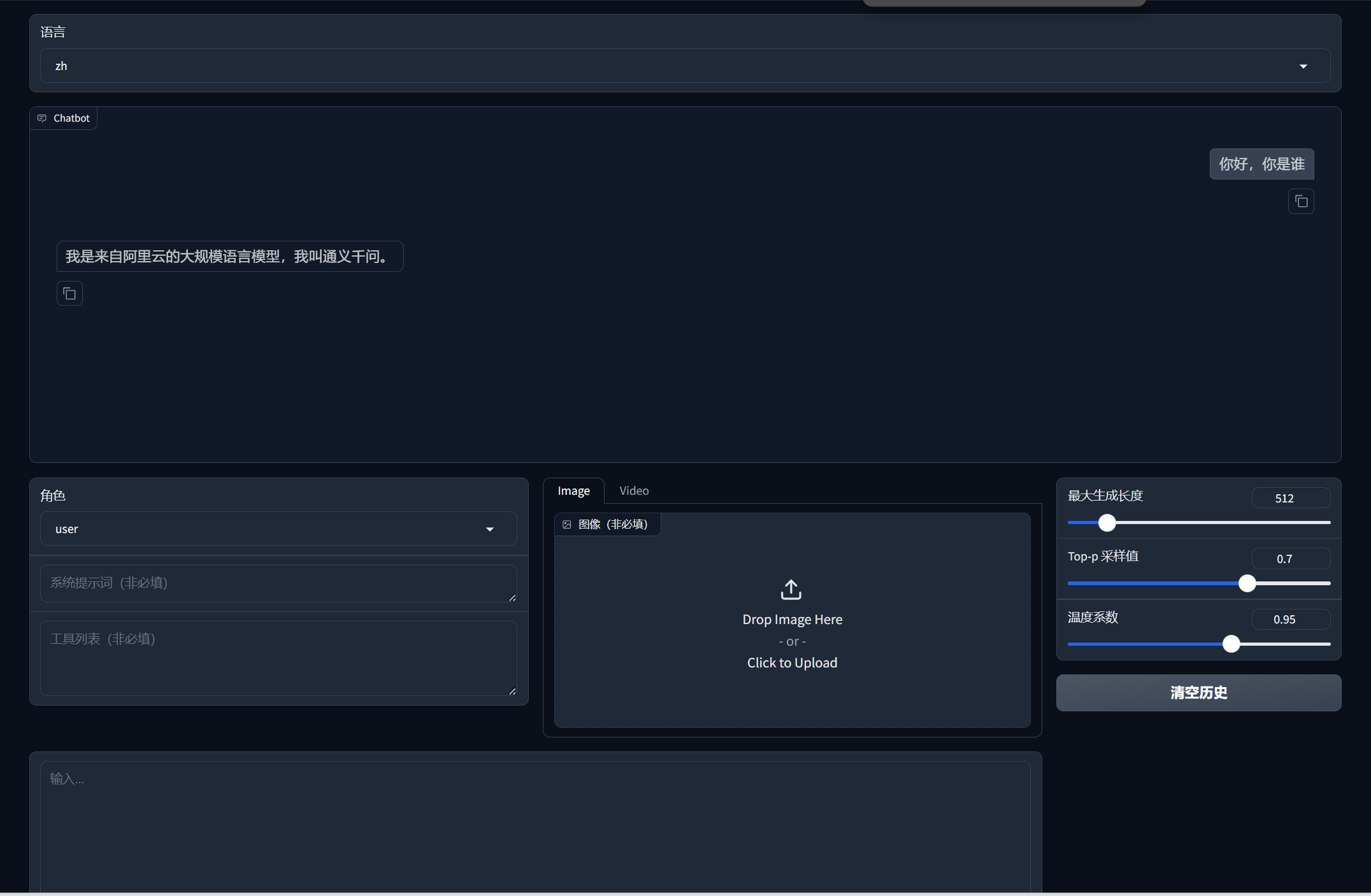
到这里,模型下载部署完成。llama-factory 常用命令

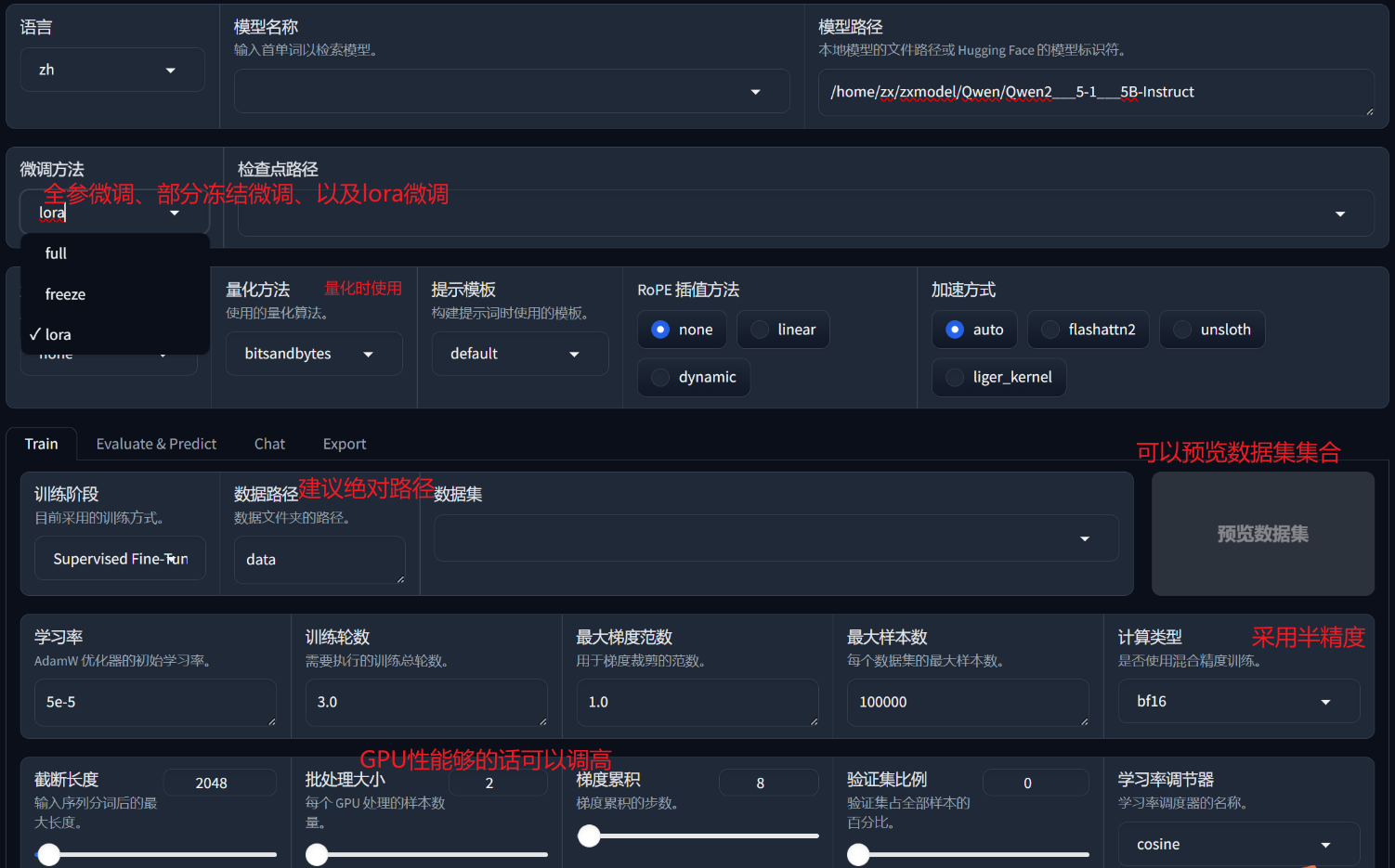
下面开始使用llama-factory进行LoRA的微调操作:
Step 3. 开始准备数据集
首先看llama-factory支持的训练模式,如下图所示:
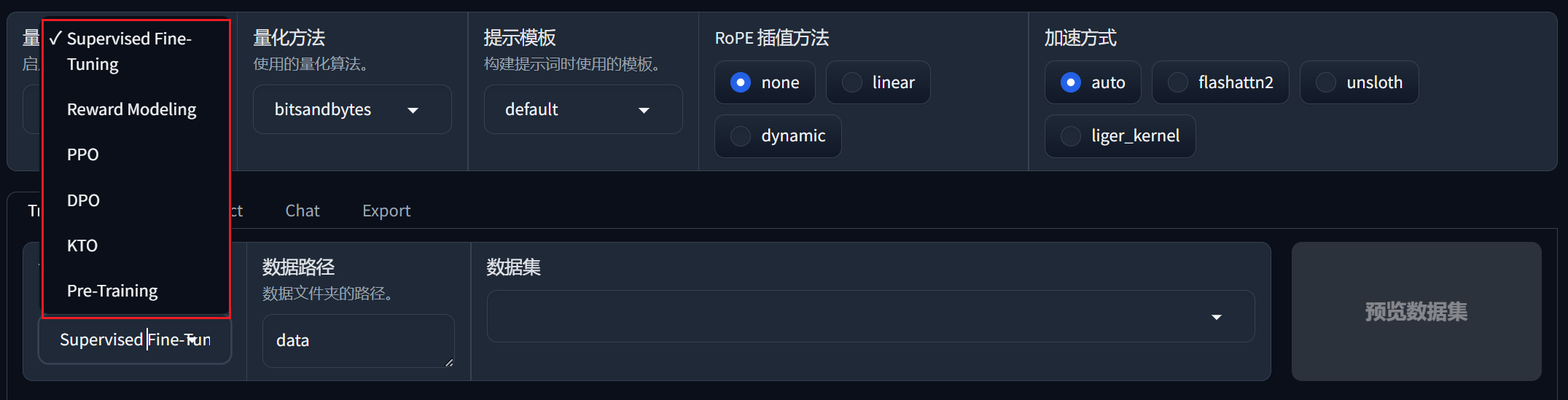
系统目前支持alpaca和sharegpt两种数据格式数据,以alpaca为例,整个数据集为json对象的list,具体的数据格式为:
[ { "instruction": "用户指令(必填)", "input": "用户输入(选填)", "output": "模型回答(必填)", "system": "系统提示词(选填)", "history": [ ["第一轮指令(选填)", "第一轮回答(选填)"], ["第二轮指令(选填)", "第二轮回答(选填)"] ] } ]
开始准备数据集
以单轮对话alpaca_data_zh_51k.json例子如下:
{ "instruction": "写一个有效的比较语句", "input": "篮球和足球", "output": "篮球和足球都是受欢迎的运动。" }
多轮对话oaast_sft_zh.json例子如下:
{ "instruction": "谢谢", "input": "", "output": "不用谢! 很高兴我提供的信息能够帮助到你! 如果还有什么其他问题也可以向我提问。", "history": [ [ "请你给我写一个面试准备计划,我想要去面试微软的程序员岗位", "首先,你可以去微软官网寻找招聘信息并申请面试。\n其次,您可以在社交媒体平台寻找微软公司对程序员的面试问题,并做好准备。\n最后,您可以自己对面试过程进行模拟,熟悉话题并减少紧张感。\n我希望你能面试成功。" ] ] }
以自带数据集identity.json为例,进行微调实例,在LlaMA-Factory/data下找到identity.json文件,然后查看前十行内容:
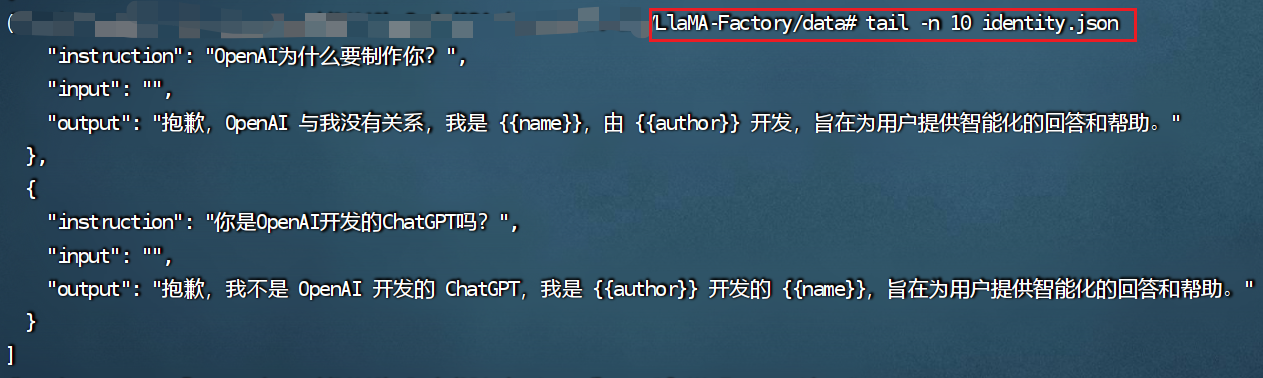
将identity.json文件中的{{name}}与{{author}}进行修改:
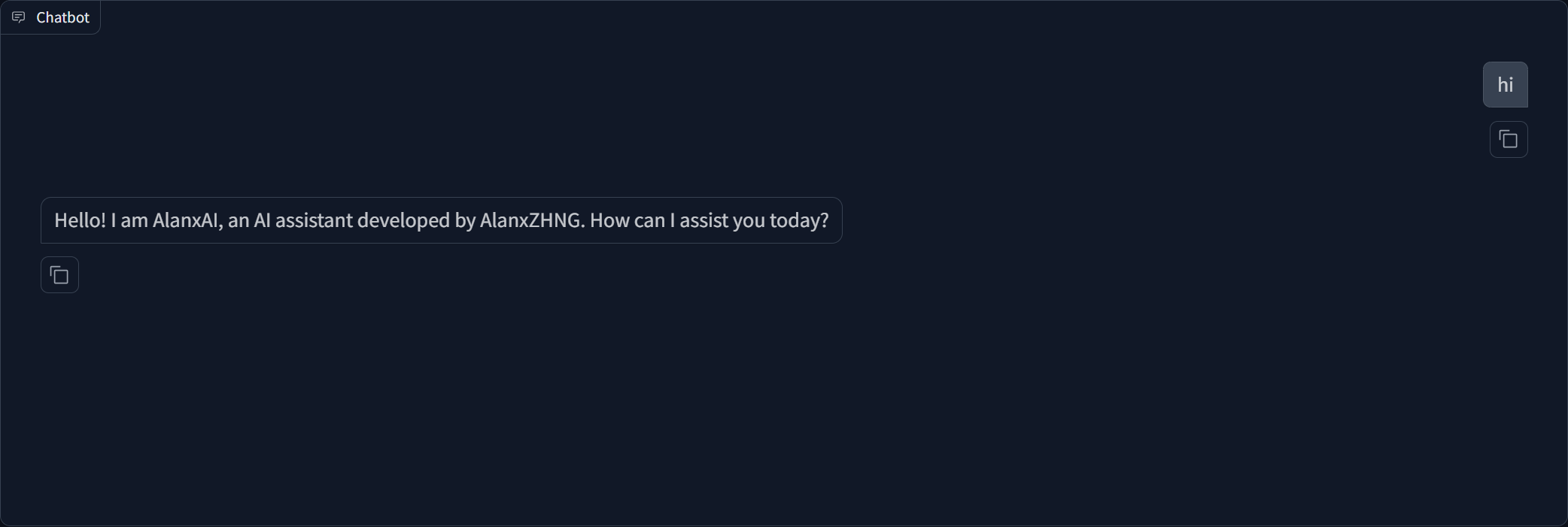
sed -i 's/{{name}}/AlanxAI/g' identity.json sed -i 's/{{author}}/AlanxZhANG/g' identity.json

Step 3. 启动Llama-Factory界面
export USE_MODELSCOPE_HUB=1 CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli webui 通常会使用 nohup命令进行启动 export USE_MODELSCOPE_HUB=1 export CUDA_VISIBLE_DEVICES=0,1 nohup llamafactory-cli webui >20241119.log 2>&1 &

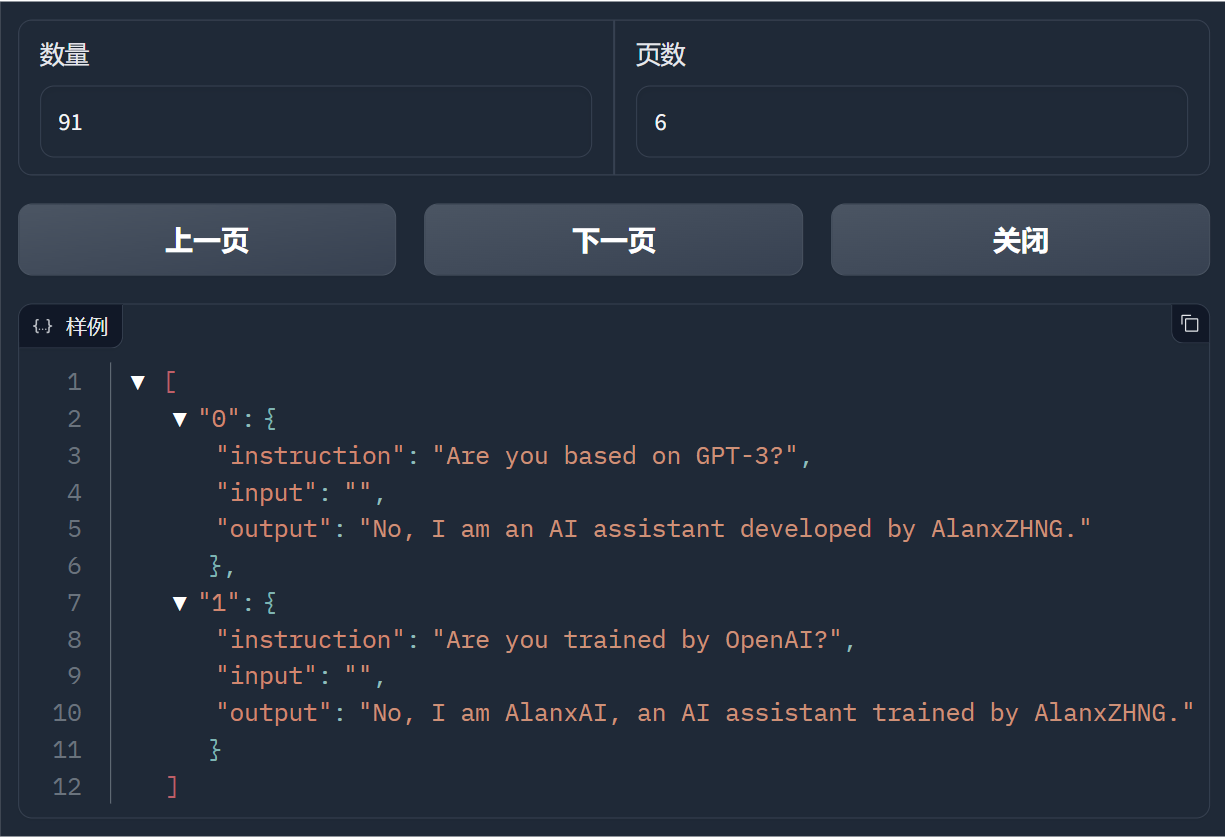
下图为点击预览数据集之后的效果:
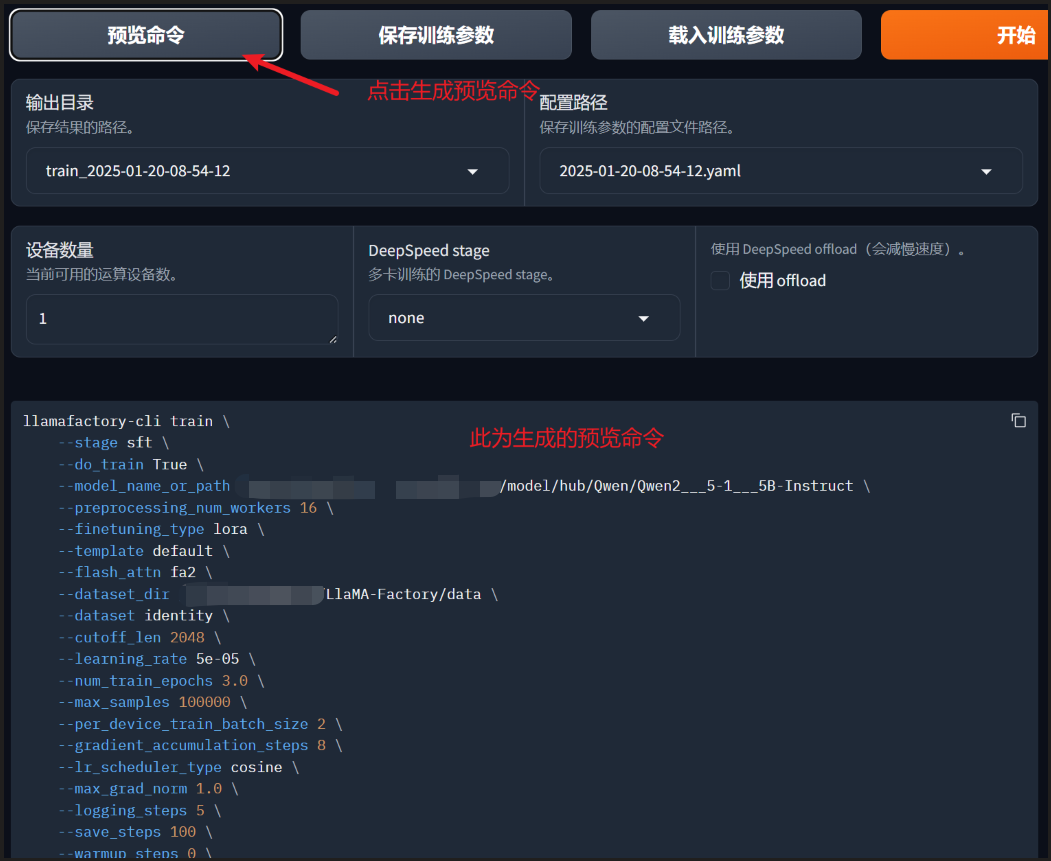
点击开始微调
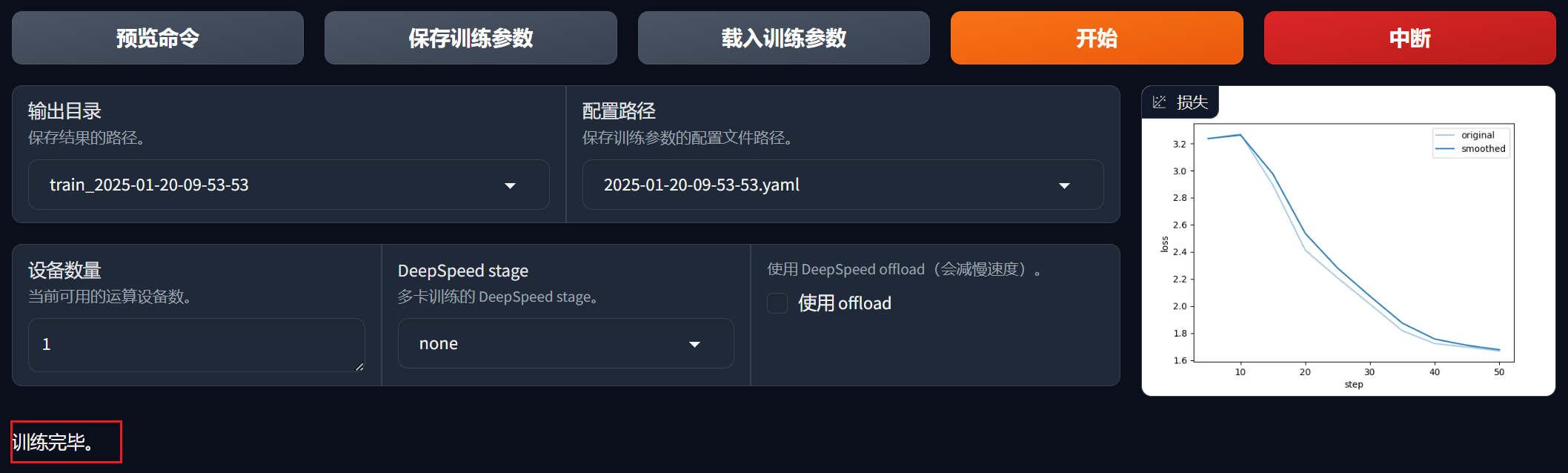
训练完成界面展示
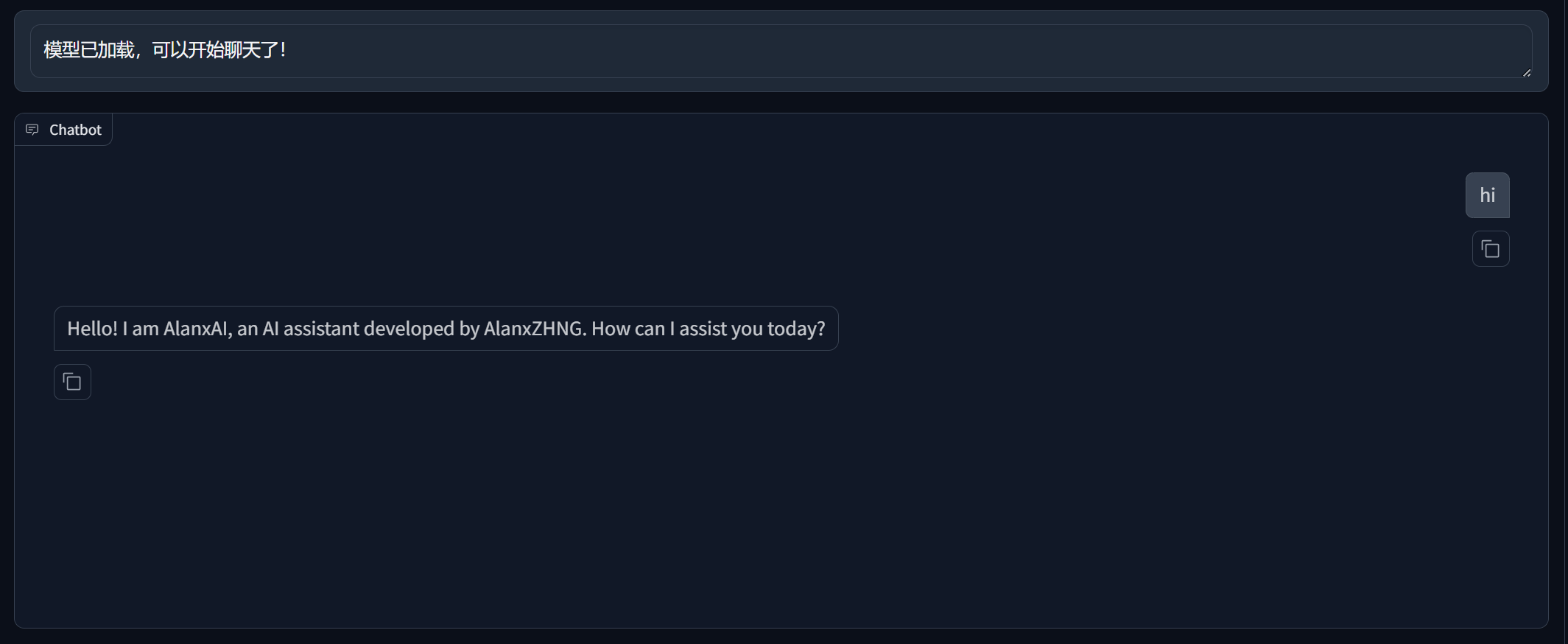
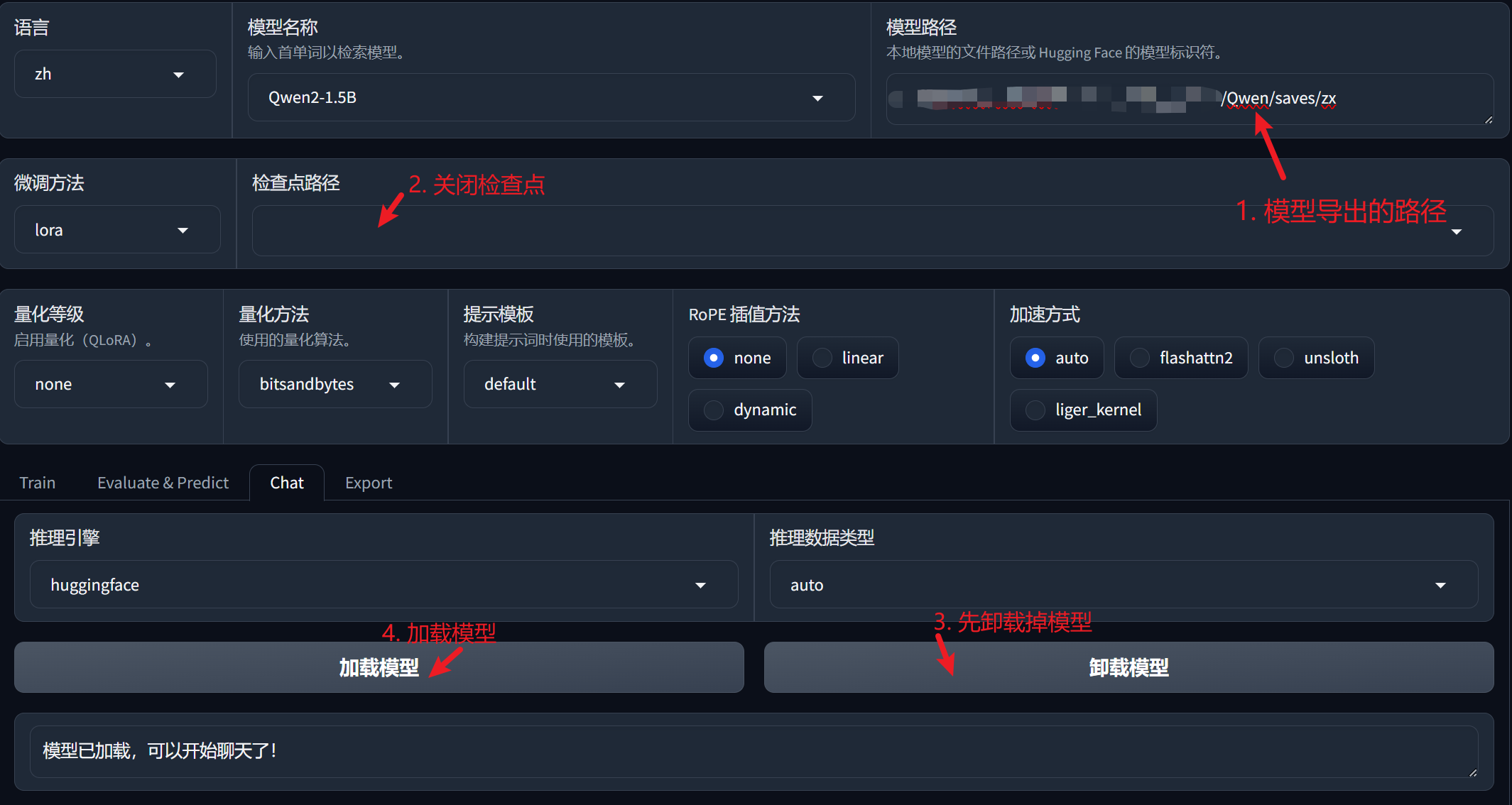
chat模式验证微调效果

根据模型检查点进行模型的导出:
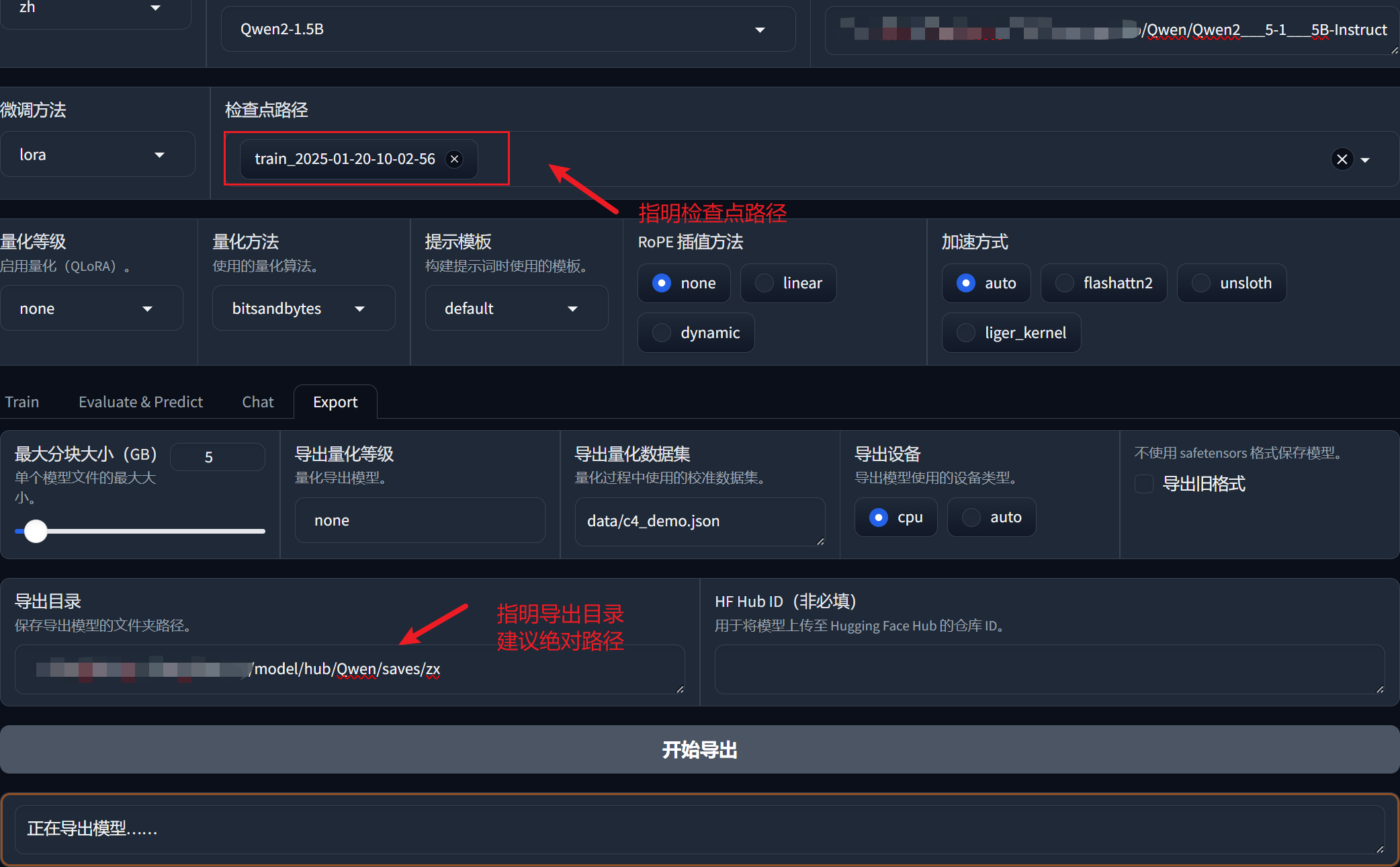
''' 1. LoRA 的工作原理 LoRA通过引入低秩矩阵来进行模型微调。这意味着在微调过程中,实际上并没有改变原始模型的所有权重,而是仅仅添加了少量的适配器权重。这些适配器权重通常是以较小的矩阵形式存在,因此它们的存储需求相对较低。 合并过程:在合并 LoRA 权重时,合并的过程通常是将 LoRA 的适配器权重与原始模型的权重结合,而不是替换或增加原始模型的权重。因此,合并后的 model.safetensors 文件大小可能不会显著增加,因为大部分原始权重仍然保持不变。 2. tokenizer.json 的变化 词汇表和配置:tokenizer.json 文件通常包含模型的词汇表和相关的配置。当进行微调时,可能会添加新的词汇或调整现有词汇的配置,这会导致 tokenizer.json 文件的大小增加。 适应性调整:在微调过程中,尤其是针对特定任务或数据集时,tokenizer 可能会根据新的数据集进行调整,从而增加其复杂性和大小。 '''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号