collections集合的总括。
序言
突然遇到集合的有关面试题,感觉很懵逼,所以特意总结了一下,关于我们常用的 ArrayList、LinkedList、Set等集合的一些区别和用法。
还有,这份微小型总结肯定是从很多博文中摘取精华拿过来的,因为我还是一个菜鸟,不能自己写出自己的见解,还是在学习的路程中,见谅。
参考博文:
http://shmilyaw-hotmail-com.iteye.com/blog/1595399
http://www.cnblogs.com/nayitian/p/3266090.html#collectionframe
大神真的很多,学无止境,学的越多,越发现自己的无知,感谢能站在巨人的肩膀上前行。
个人想法:这只是初步的一份小总结,之后的文章会对每一个集合进行详细的讲解,比如,看源码,内部如何实现的,这样加深自己对这些集合的理解
、
------WZY
一、简述
这是collection总体的一个关系图,很庞大,我就挑我们常用的来讲解一下。
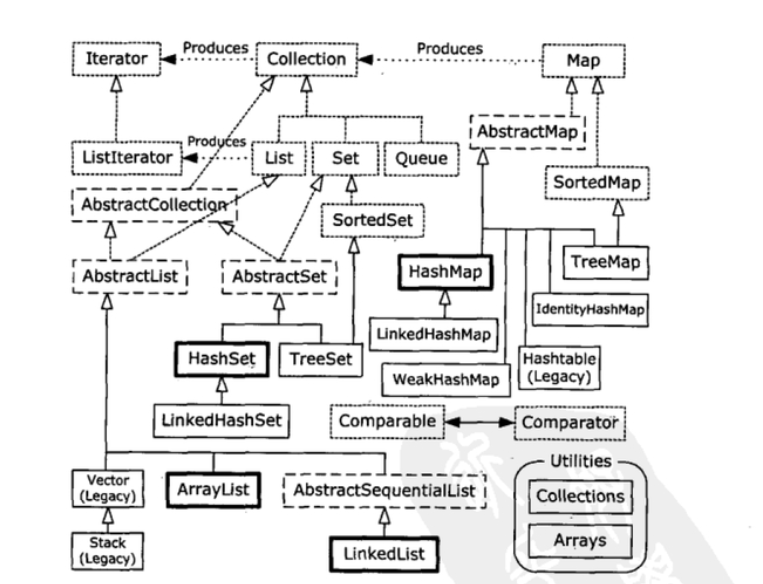
集合类这块,总的来说,就分为两大类,
1:按照一定顺序进行迭代访问的集合类
2:按照key、value这样的键值对关系进行访问的集合类
二、第一种,按照一定顺序进行迭代访问的集合类的继承关系图,
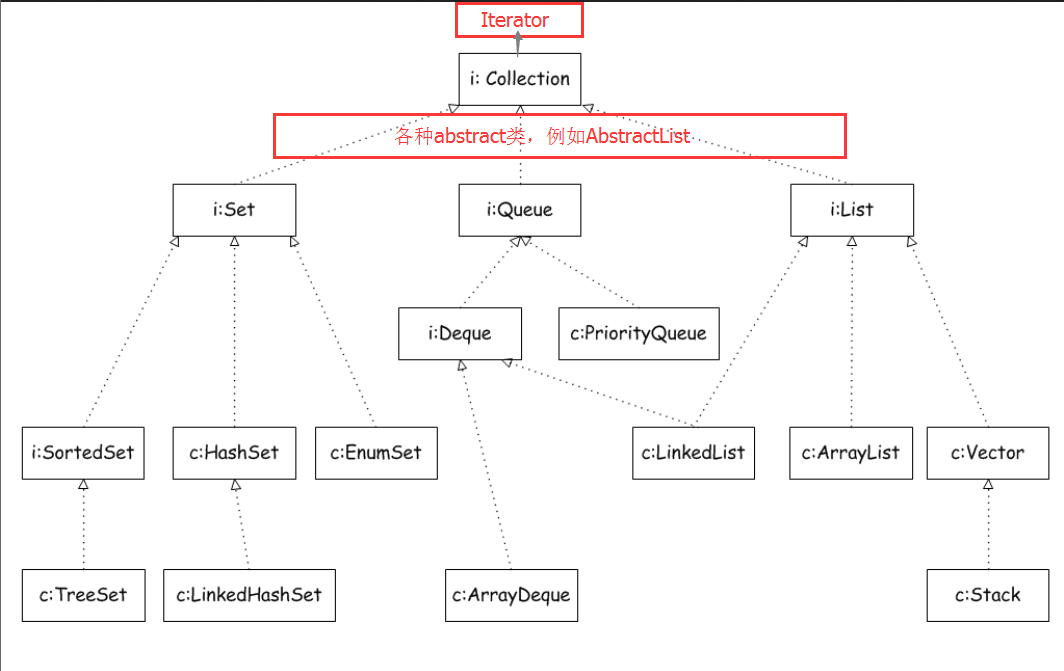
Set接口:无顺序,不可重复。
HashSet类:方便用于数据的查询,加入的元素特别要注意hashCode()方法的实现,不是同步的,多线程访问同一个hashSet对象时,需要手工同步
LinkedHashSet类:根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序。与HashSet相比方便用于数据的增加和删除,
这两个就好比arrayList和LinkedList,一个方便查询一个方便增删
SortSet类是SortedSet接口的实现类:看类名是用来排序等其他功能来使用的。后面的文章我会一一更加详细的解释。
EnumSet类:专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值
List接口:有顺序,可以重复
LinkedList类:内部使用链表的形式来存储数据,在增加和删除数据上面性能更好
它实现了List接口和Deque接口,说明它具有两边接口的特性,因此它可以当作一个双端队列来用,也可以当作栈来用,并且它是以链表的形式来实现的,所以查询性能差,但是增加和删除操作性能高。
ArrayList类:内部使用数组来存储数据,也就相当于数据结构的顺序表存储,在查询数据上面性能好,
Vertor类:跟ArrayList相比,它是线程安全的,而ArrayList是线程不安全的,
Stack类继承Vertor类:看名字,其实就是方便模拟“栈”这种数据结构
Queue接口:用于模拟队列这种数据结构,然后该接口中声明了一些基本操作的方法。例如:add、offer、remove等
PriorityQueue类:PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按队列元素的大小重新排序
Deque接口:Deque代表一个双端队列,可以当作一个双端队列使用,也可以当作“栈”来使用,因为它包含出栈pop()与入栈push()方法。
ArrayDeque类为Deque的实现类:也就是实现了Deque接口中定义的方法,解释跟deque差不多
各种线性表选择策略
- 数组:是以一段连续内存保存数据的;随机访问是最快的,但不支持插入、删除、迭代等操作。
- ArrayList与ArrayDeque:以数组实现;随机访问速度还行,插入、删除、迭代操作速度一般;线程不安全。
- Vector:以数组实现;随机访问速度一般,插入、删除、迭代速度不太好;线程安全的。
- LinkedList:以链表实现;随机访问速度不太好,插入、删除、迭代速度非常快。
三、第二种,使用key、value键值对的形式进行访问的集合类。
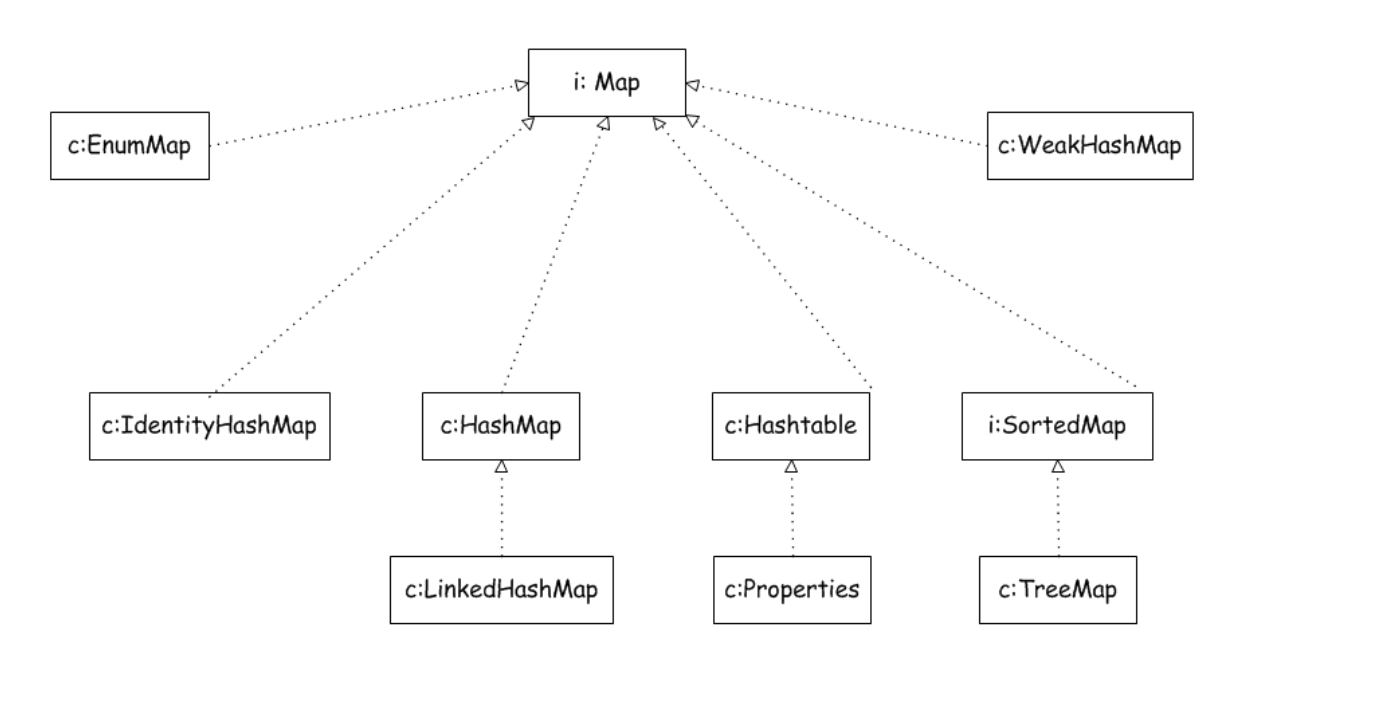
Map接口:定义一些基本的操作,例如put(key,value), containKey(Object key)等一系列操作。
HashMap类和Hashtable类对比,一般使用HashMap,因为Hashtable类是很古老的,据查都不建议用。平常我们也是用HashMap
HashMap类是线程不安全的,而Hashtable是线程安全的
HashMap类可以使用null作为key和value,而Hashtable不可以
Properties类继承Hashtable类
增加了额外的一些方法,例如:load(InputStream inStream)从属性文件加载key-value等方法。
可以将key-value用xml文件的格式保存,可能就是跟xml文件打一些交道
LinkedHashMap类继承HashMap类
LinkedHashMap从HashMap类继承而来。以链表来维护内部顺序。很多方面跟LinkedHashSet类似。LinkedHashMap它可以记住key-value对的添加时的顺序, 同时避免使用 TreeMap时性能受到的影响。
SortedMap接口和TreeMap实现类
类似于SortedSet及TreeSet,TreeMap也可以自定义比较器(Comparable)实现定制排序。它的额外提供的方法也与TreeSet类似,增加了访问第一个、前一个、后一个、最 后一个key-value对的方法,并提供了从TreeMap中提取子集的方法。TreeMap不允许null作为key,要不然怎么比较呢?
IdentityHashMap类
与HashMap的不同在于,只有两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等;而对于普通HashMap而言,只要key1.equals(key2)且hashCode相同即可。同样允许null值,不能保证顺序。
EnumMap类
EnumMap是一个与枚举类一起使用的Map实现。它的key必须是单个枚举类的枚举值。EnumMap不允许使用null作为key,但可作为value。
各种Map实现类选择策略
- 正常情况使用HashMap,而不是Hashtable。
- 如果考虑排序,那么考虑使用TreeMap。通常TreeMap比HashMap等在插入、删除操作时要慢不少,因为它需要在底层采用红黑树来管理key-value对。
- 如果考虑插入时的顺序,那么使用LinkedHashMap是个不错的选择。
- 如果想优化垃圾回收,建议使用WeakHashMap实现类(本文未提及);要求key完全匹配(同一对象),则使用IdentityHashMap;还有枚举类不多说了。
- 关于null值:Hashtable不允许key为null,也不允许value为null;TreeMap与EnumMap不允许key为null;HashMap及其子类LinkedHashMap,IdentityHashMap允许key为null。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号