
Java进阶专题(二十二) 微服务架构体系-SpringCloudAlibaba
前言
"微服务”一词源于 Martin Fowler的名为 Microservices的,博文,可以在他的官方博客上找到http:/ /martinfowler . com/articles/microservices.html简单地说,微服务是系统架构上的一种设计风格,它的主旨是将一个原本独立的系统拆分成多个小型服务,这些小型服务都在各自独立的进程中运行,服务之间通过基于HTTP的 RESTfuL AP进行通信协作。常见微服务框架:Spring的spring cloud、阿里dubbo、华为ServiceComb、腾讯Tars、Facebook thrift、新浪微博Motan。本章节我们先从了解组成完整系统的各个组件开始,下章节将利用这些组件,搭建出一个完善的分布式系统。
Spring Cloud
这就不用多说了,官网有详细的介绍。
Spring Cloud Alibaba
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务
主要组件
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架。
Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
服务注册与发现
Eureka:官方宣布2.x不再开源(闭源),之前的版本已经停止更新;也就说Eureka将来更多的技术提升已经没有了。所以,如果希望注册中心有更多强大功能的话,还需要另辟蹊径 。
Zookeeper:在企业级Zookeeper注册中心与 Dubbo组合比较多一些,kafka使用的也是,随着Eureka的停更,我们可以通过spring-cloud-starter-zookeeper-discovery这个启动器,将Zookeeper做为springcloud的注册中心。
Consul:go语言开发的,也是一个优秀的服务注册框架,使用量也比较多。
Nacos:来自于SpringCloudɵɹibaba,在企业中经过了百万级注册考验的,不但可以完美替换Eureka,还能做其他组件的替换,所以,Naocs也强烈建议使用。
介绍下Nacos用作注册中心
Nacos简介
Nacos(Dynamic Naming and Configur ation Service) 是阿里巴巴2018年7月开源的项目,致力于发现、配置和管理微服务。
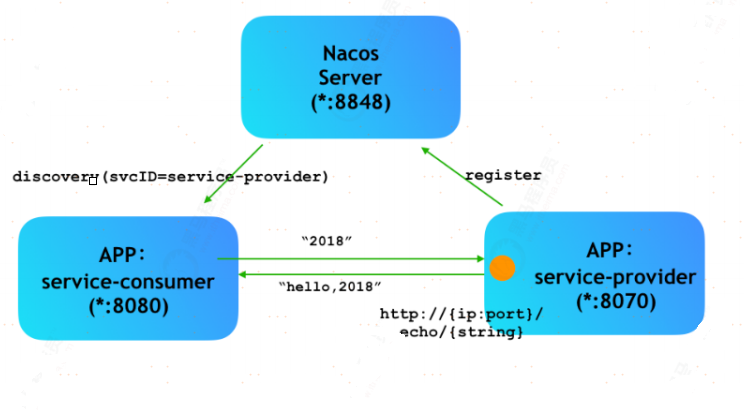
Nacos安装
单节点
--下载镜像
docker pull nacos/nacos-server:1.3.1
--启动容器
docker run --name nacos --env MODE=standalone --privileged=true -p 8848:8848 --restart=always -d dc833dc45d8f
访问:
http://127.0.0.1:8848/nacos 账号密码都是nacos
集群
安装前提
64 bit OS Linux/Unix/Mac,推荐使用Linux系统。
集群需要依赖mysql,单机可不必
3个或3个以上Nacos节点才能构成集群
搭建Nacos高可用集群步骤:
1、需要去Nacos官网clone Nacos集群项目nacos-docker
2、nacos-docker是使用的Docker Compose对容器进行编排,所以首先需要安装Docker Compose详细信息可参照Nacos官网:https:/ /nacos.io/zh-cn/docs/quick-start-docker.html
1)安装Docker Compose
什么是Docker Compose
Compose项目是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。
#在Linux下下载(下载到/usr/local/bin)
curl -L https://github.com/docker/compose/releases/download/1.25.0/run.sh > /usr/local/bin/docker-compose
# 设置文件可执行权限
chmod +x /usr/local/bin/docker-compose
# 查看版本信息
docker-compose --version
2)克隆Nacos-docker项目
#切换到自定义目录
cd /usr/local/nacos
#开始clone
git clone https://github.com/nacos-group/nacos-docker.git
3)运行nacos-docker脚本
#执行编排命令
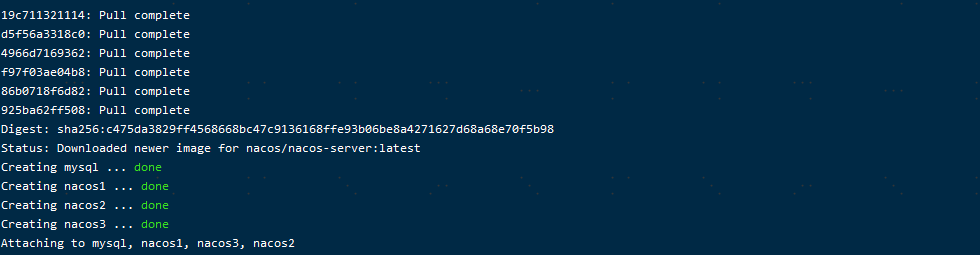
docker-compose -f /usr/local/nacos/nacos-docker/example/cluster-hostname.yaml up
上面的编排命令主要下载mysql镜像和nacos镜像,自动完成镜像下载/容器启动
Pulling from nacos/nacos-mysql,版本是5. 7(执行初始化脚本)
Pulling nacos3 (nacos/nacos-server:latest)最新版本
4)停止、启动
#启动
docker-compose -f /usr/local/nacos/nacos-docker/example/cluster-hostname.yaml start
#停止
docker-compose -f /usr/local/nacos/nacos-docker/example/cluster-hostname.yaml stop
5)访问Nacos
http://192.168.1.1:8848/nacos
http://192.168.1.1:8849/nacos
http://192.168.1.1:8850/nacos
Nacos快速入门
配置服务提供者
服务提供者可以通过 Nacos 的服务注册发现功能将其服务注册到 Nacos server 上。
添加nacos依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>${latest.version}</version>
</dependency>
添加配置
server.port=8070
spring.application.name=nacos-demo
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
启动类
@SpringBootApplication
@EnableDiscoveryClient
public class NacosProviderApplication {
public static void main(String[] args) {
SpringApplication.run(NacosProviderApplication.class, args);
}
@RestController
class EchoController {
@RequestMapping(value = "/echo/{string}", method = RequestMethod.GET)
public String echo(@PathVariable String string) {
return "Hello Nacos Discovery " + string;
}
}
}
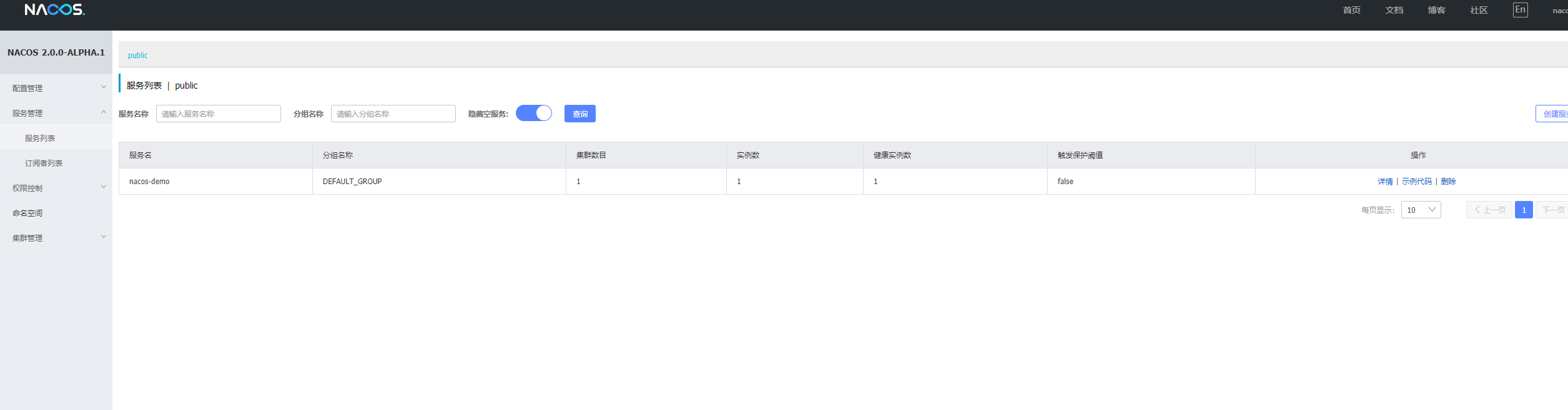
启动后,控制台:

说明注册成功,后台查看该服务:
下面我们用spring cloud 整合naocs实现服务调用
配置服务消费者
添加配置
server.port=8080
spring.application.name=service-consumer
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
添加启动类:服务消费者使用 @LoadBalanced RestTemplate 实现服务调用
@SpringBootApplication
@EnableDiscoveryClient
public class NacosConsumerApplication {
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(NacosConsumerApplication.class, args);
}
@RestController
public class TestController {
private final RestTemplate restTemplate;
@Autowired
public TestController(RestTemplate restTemplate) {this.restTemplate = restTemplate;}
@RequestMapping(value = "/echo/{str}", method = RequestMethod.GET)
public String echo(@PathVariable String str) {
return restTemplate.getForObject("http://service-provider/echo/" + str, String.class);
}
}
}
测试
启动 ProviderApplication 和 ConsumerApplication ,调用 http://localhost:8080/echo/2018,返回内容为 Hello Nacos Discovery 2018。
分布式配置中心解决方案与应用
目前市面上用的比较多的配置中心有(时间顺序)
Disconf:2014年7月百度开源的配置管理中心,同样具备配置的管理能力,不过目前已经不维护了,最近的一次提交是4-5年前了。
Spring Cloud Config:2014年9月开源,Spring Cloud 生态组件,可以和Spring Cloud体系无缝整合。
Apollo:2016年5月,携程开源的配置管理中心,具备规范的权限、流程治理等特性。
Nacos:2018年6月,阿里开源的配置中心,也可以做DNS和RPC的服务发现
介绍下Nacos用作分布式配置中心
启动了 Nacos server 后,您就可以参考以下示例代码,为您的 Spring Cloud 应用启动 Nacos 配置管理服务了。完整示例代码请参考:nacos-spring-cloud-config-example
- 添加依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
<version>${latest.version}</version>
</dependency>
注意:版本 2.1.x.RELEASE 对应的是 Spring Boot 2.1.x 版本。版本 2.0.x.RELEASE 对应的是 Spring Boot 2.0.x 版本,版本 1.5.x.RELEASE 对应的是 Spring Boot 1.5.x 版本。
更多版本对应关系参考:版本说明 Wiki
- 在
bootstrap.properties中配置 Nacos server 的地址和应用名
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.application.name=example
说明:之所以需要配置 spring.application.name ,是因为它是构成 Nacos 配置管理 dataId字段的一部分。
在 Nacos Spring Cloud 中,dataId 的完整格式如下:
${prefix}-${spring.profiles.active}.${file-extension}
prefix默认为spring.application.name的值,也可以通过配置项spring.cloud.nacos.config.prefix来配置。spring.profiles.active即为当前环境对应的 profile,详情可以参考 Spring Boot文档。 注意:当spring.profiles.active为空时,对应的连接符-也将不存在,dataId 的拼接格式变成${prefix}.${file-extension}file-exetension为配置内容的数据格式,可以通过配置项spring.cloud.nacos.config.file-extension来配置。目前只支持properties和yaml类型。
- 通过 Spring Cloud 原生注解
@RefreshScope实现配置自动更新:
@RestController
@RequestMapping("/config")
@RefreshScope
public class ConfigController {
@Value("${useLocalCache:false}")
private boolean useLocalCache;
@RequestMapping("/get")
public boolean get() {
return useLocalCache;
}
}
- 首先通过调用 Nacos Open API 向 Nacos Server 发布配置:dataId 为
example.properties,内容为useLocalCache=true
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=example.properties&group=DEFAULT_GROUP&content=useLocalCache=true"
- 运行
NacosConfigApplication,调用curl http://localhost:8080/config/get,返回内容是true。 - 再次调用 Nacos Open API 向 Nacos server 发布配置:dataId 为
example.properties,内容为useLocalCache=false
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=example.properties&group=DEFAULT_GROUP&content=useLocalCache=false"
- 再次访问
http://localhost:8080/config/get,此时返回内容为false,说明程序中的useLocalCache值已经被动态更新了。
分布式服务调用
RPC概述
RPC 的主要功能目标是让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。为实现该目标,RPC 框架需提供一种透明调用机制,让使用者不必显式的区分本地调用和远程调用。
RPC的优点:分布式设计、部署灵活、解耦服务、扩展性强。
RPC框架
Dubbo:国内最早开源的 RPC 框架,由阿里巴巴公司开发并于 2011 年末对外开源,仅支持 Java 语言。
Motan:微博内部使用的 RPC 框架,于 2016 年对外开源,仅支持 Java 语言。
Tars:腾讯内部使用的 RPC 框架,于 2017 年对外开源,仅支持 C++ 语言。
Spring Cloud:国外 Pivotal 公司 2014 年对外开源的 RPC 框架,提供了丰富的生态组件。
gRPC:Google 于 2015 年对外开源的跨语言 RPC 框架,支持多种语言。
Thrift:最初是由 Facebook 开发的内部系统跨语言的 RPC 框架,2007 年贡献给了 Apache 基金,成为
Apache:开源项目之一,支持多种语言。
RPC框架优点
RPC框架一般使用长链接,不必每次通信都要3次握手,减少网络开销。
RPC框架一般都有注册中心,有丰富的监控管理发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作协议私密,安全性较高
RPC 协议更简单内容更小,效率更高,服务化架构、服务化治理,RPC框架是一个强力的支撑。
RPC框架应用:使用Spring Cloud Alibaba 整合Dubbo实现
由于 Dubbo Spring Cloud 构建在原生的 Spring Cloud 之上, 其服务治理方面的能力可认为是 Spring Cloud Plus,不仅完全覆盖 Spring Cloud 原生特性,而且提供更为稳定和成熟的实现,特性比对如下表所示:

Dubbo 作为 Spring Cloud 服务调用
默认情况,Spring Cloud Open Feign 以及@LoadBalanced`RestTemplate 作为 Spring Cloud 的两种服务调用方式。 Dubbo Spring Cloud 为其提供了第三种选择,即 Dubbo 服务将作为 Spring Cloud 服务调用的同等公民出现,应用可通过 Apache Dubbo 注解@Service 和@Reference 暴露和引用 Dubbo 服务,实现服务间多种协议的通讯。同时,也可以利用 Dubbo 泛化接口轻松实现服务网关。
快速上手
按照传统的 Dubbo 开发模式,在构建服务提供者之前,第一个步骤是为服务提供者和服务消费者定义 Dubbo 服务接口。
为了确保契约的一致性,推荐的做法是将 Dubbo 服务接口打包在第二方或者第三方的 artifact(jar)中,该 artifact 甚至无需添加任何依赖。
对于服务提供方而言,不仅通过依赖 artifact 的形式引入 Dubbo 服务接口,而且需要将其实现。对应的服务消费端,同样地需要依赖该 artifact,并以接口调用的方式执行远程方法。接下来的步骤则是创建 artifact。
创建服务API
创建一个api模块,专门写各种接口的:
/**
* @author 原
* @date 2020/12/8
* @since 1.0
**/
public interface TestService {
String getMsg();
}
创建服务提供者
导入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<!-- api接口的依赖包-->
<dependency>
<groupId>com.dubbo.demo</groupId>
<artifactId>dubbo-demo-api</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
编写配置
dubbo:
scan:
# dubbo 服务扫描基准包
base-packages: org.springframework.cloud.alibaba.dubbo.bootstrap
protocol:
# dubbo 协议
name: dubbo
# dubbo 协议端口( -1 表示自增端口,从 20880 开始)
port: -1
spring:
cloud:
nacos:
# Nacos 服务发现与注册配置
discovery:
server-addr: 127.0.0.1:8848实现
/**
* @author 原
* @date 2021/1/28
* @since 1.0
**/
@Service//dubbo的service注解
public class TestServiceImpl implements TestService {
@Override
public String getMsg() {
return "123123";
}
}
启动类
/**
* @author 原
* @date 2021/1/28
* @since 1.0
**/
@SpringBootApplication
@EnableDiscoveryClient
public class DubboProviderApplication {
public static void main(String[] args) {
SpringApplication.run(DubboProviderApplication.class,args);
}
}
创建服务消费者
除了api的实现类 其他复用提供者的代码
编写测试类
/**
* @author 原
* @date 2021/1/28
* @since 1.0
**/
@RestController
public class TestController {
@Reference
TestService testService;
@GetMapping("/dubbo/test")
public String getMsg(){
return testService.getMsg();
}
}
访问:
返回111
服务流量管理
为什么要流控降级
流量是非常随机性的、不可预测的。前一秒可能还风平浪静,后一秒可能就出现流量洪峰了(例如双十一零点的场景)。然而我们系统的容量总是有限的,如果突然而来的流量超过了系统的承受能力,就可能会导致请求处理不过来,堆积的请求处理缓慢,CPU/Load飙高,最后导致系统崩溃。因此,我们需要针对这种突发的流量来进行限制,在尽可能处理请求的同时来保障服务不被打垮,这就是流量控制。
一个服务常常会调用别的模块,可能是另外的一个远程服务、数据库,或者第三方API 等。例如,支付的时候,可能需要远程调用银联提供的 API;查询某个商品的价格,可能需要进行数据库查询。然而,这个被依赖服务的稳定性是不能保证的。如果依赖的服务出现了不稳定的情况,请求的响应时间变长,那么调用服务的方法的响应时间也会变长,线程会产生堆积,最终可能耗尽业务自身的线程池,服务本身也变得不可用。
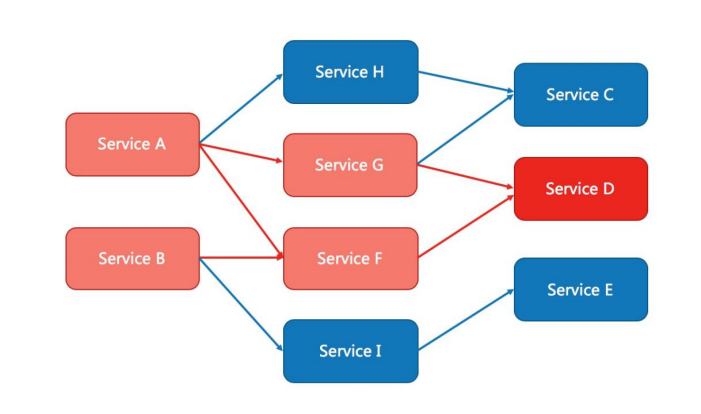
现代微服务架构都是分布式的,由非常多的服务组成。不同服务之间相互调用,组成复杂的调用链路。以上的问题在链路调用中会产生放大的效果。复杂链路上的某一环不稳定,就可能会层层级联, 最终导致整个链路都不可用。 因此我们需要对不稳定的弱依赖服务进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。
关于容错组件的停更/升级/替换
服务降级:
Hystrix:官网不极力推荐,但是中国企业中还在大规模使用,对于限流和熔断降级虽然在1 .5版本官方还支持(版本稳定),
但现在官方已经开始推荐大家使用Resilience4j
Resilience4J:官网推荐使用,但是国内很少用这个。
Sentienl:来自于Spring Cloud Alibaba,在中国企业替换Hystrix的组件,国内强烈建议使用
这里就主要介绍下Sentinel。
Sentinel介绍
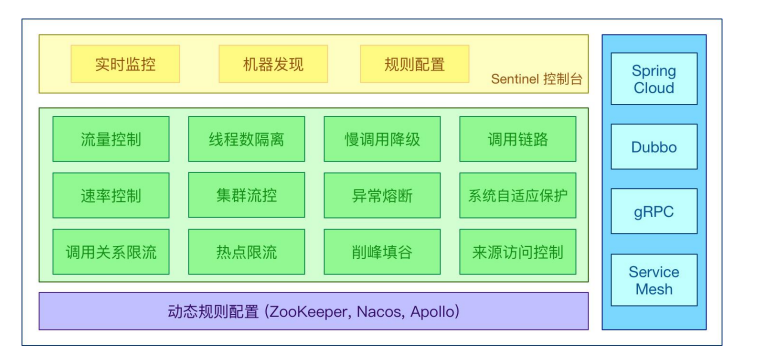
Sentinel是阿里开源的项目,提供了流量控制、熔断降级、系统负载保护等多个维度来保障服务之间的稳定性。
Sentinel的流控操作起来非常简单,在控制台进行配置即可看见效,所见即所得
Sentinel 具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
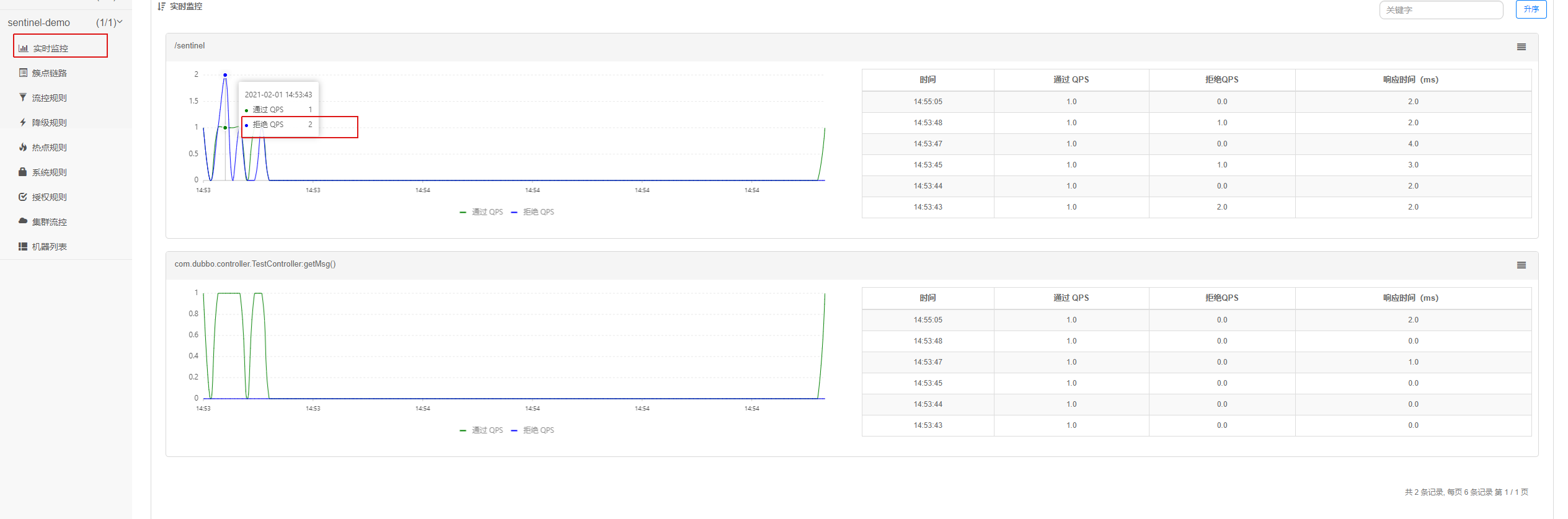
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
官网
https://github.com/alibaba/Sentinel
中文
https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D
https://sentinelguard.io/zh-cn/docs/introduction.html
Sentinel 的使用可以分为两个部分:
核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 7 及以上的版本的运行时环境,同时对Dubbo / Spring Cloud 等框架也有较好的支持。
控制台(Dashboard):控制台主要负责管理推送规则、监控、集群限流分配管理、机器发现等
使用场景
在服务提供方(Service Provider)的场景下,我们需要保护服务提供方自身不被流量洪峰打垮。 这时候通常根据服务提供方的服务能力进行流量控制, 或针对特定的服务调用方进行限制。我们可以结合前期压测评估核心口的承受能力,配置 QPS 模式的限流,当每秒的请求量超过设定的阈值时,会自动拒绝多余的请求。
为了避免调用其他服务时被不稳定的服务拖垮自身,我们需要在服务调用端(Service Consumer)对不稳定服务依赖进行隔离和熔断。手段包括信号量隔离、异常比例降级、RT 降级等多种手段。
当系统长期处于低水位的情况下, 流量突然增加时, 直接把系统拉升到高水位可能瞬间把系统压垮。这时候我们可以借助 Sentinel 的 WarmUp 流控模式控制通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,而不是在一瞬间全部放行。这样可以给冷系统一个预热的时间,避免冷系统被压垮。
利用 Sentinel 的匀速排队模式进行“削峰填谷”, 把请求突刺均摊到一段时间内, 让系统负载保持在请求处理水位之内,同时尽可能地处理更多请求。
利用 Sentinel 的网关流控特性,在网关入口处进行流量防护,或限制 API 的调用频率。
Sentinel安装
1、下载jar包https://github.com/alibaba/Sentinel/releases
2、启动
java -Dserver.port=8787 -Dcsp.sentinel.dashboard.server=127.0.0.1:8787 -Dproject.name=sentinel-dashboard -jar /home/sentinel/sentinel-dashboard-1.8.0.jar
3、访问
http://127.0.0.1:8787/#/login
初始账号密码sentinel/sentinel

可以看到sentinel是自己本身的监控

sentinel快速入门
1、导入依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.0</version>
</dependency>
2、测试类
public class TestService {
public static void main(String[] args) {
initFlowRules();
while (true) {
Entry entry = null;
try {
entry = SphU.entry("HelloWorld");
/*您的业务逻辑 - 开始*/
System.out.println("hello world");
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {
/*流控逻辑处理 - 开始*/
System.out.println("block!");
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
}
//设置流量控制规则 设置当QPS达到20时 会限制流量(抛出异常,可以执行处理)
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
}
执行结果:
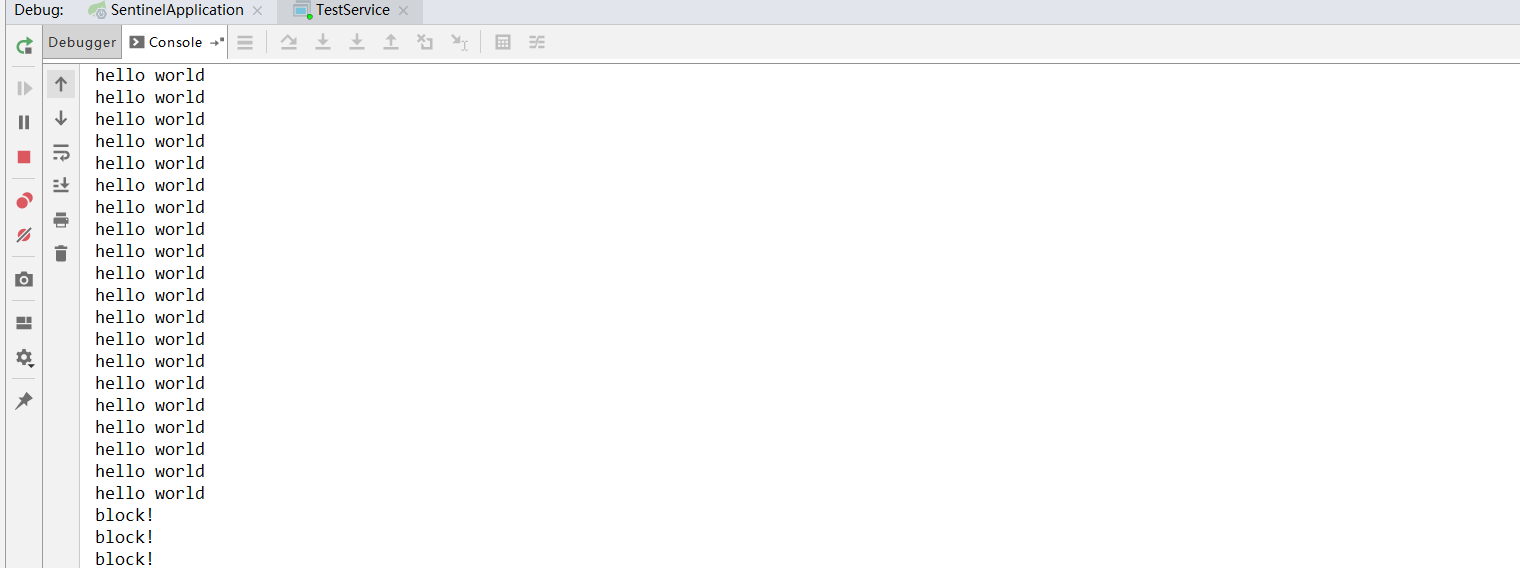
可以看到,这个程序每秒稳定输出 "hello world" 20 次,和规则中预先设定的阈值是一样的。 block表示被阻止的请求。
官方使用文档:https://github.com/alibaba/Sentinel/wiki/如何使用
Sentinel整合SpringCloud实现服务限流/熔断
导入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
</dependencies>
配置
server.port=8082
spring.application.name=sentinel-demo
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring.cloud.sentinel.transport.dashboard=127.0.0.1:8787
//在需要流控的方法加上@SentinelResource
@RestController
public class TestController {
@GetMapping("/sentinel")
@SentinelResource
public String getMsg(){
return "11";
}
}
启动应用,访问http://127.0.0.1:8082/sentinel后去sentinel后台
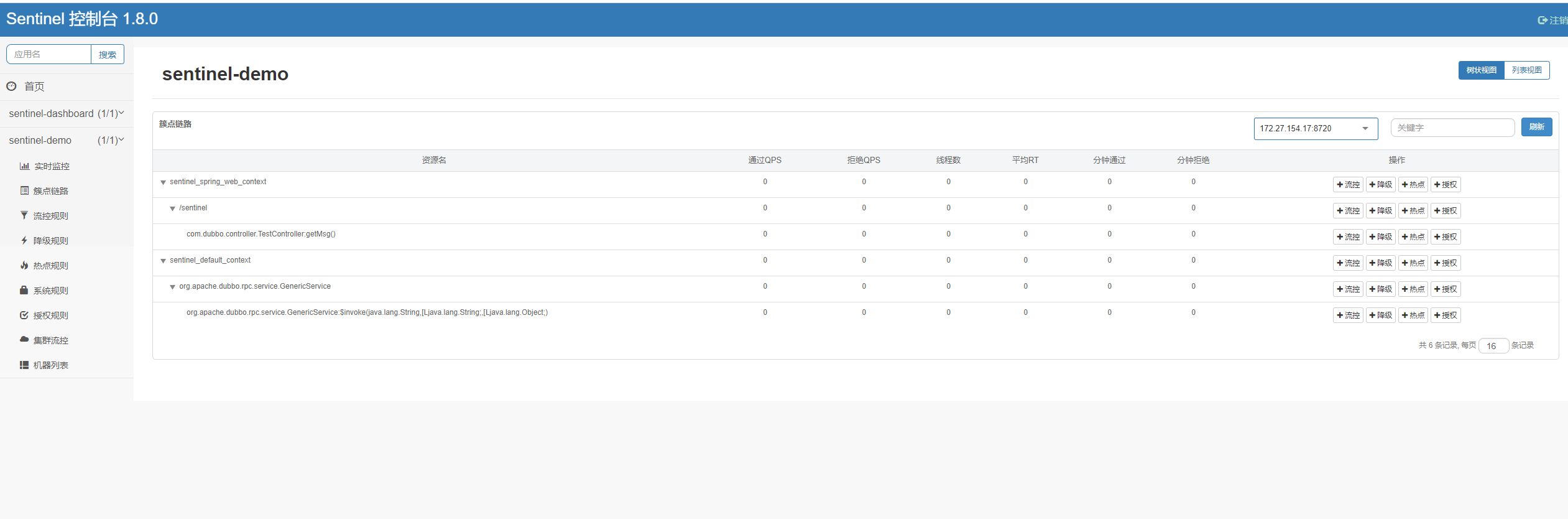
下面我们来配一条最简单的流控规则。针对 sentinel_spring_web_context /sentinel 这个服务调用配置限流规则(需要有过访问量才能看到)。我们配一条 QPS 为 1的流控规则,这代表针对该服务方法的调用每秒钟不能超过 1 次,超出会直接拒绝。
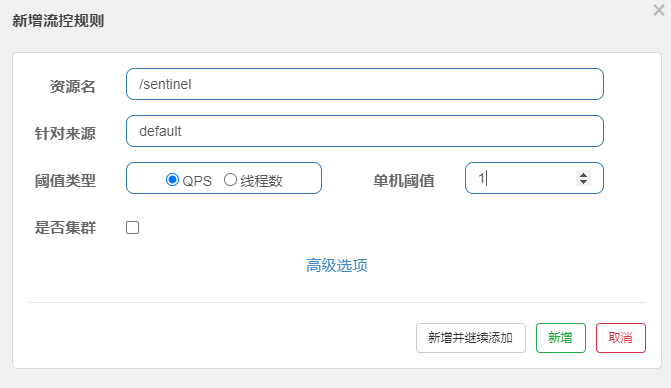
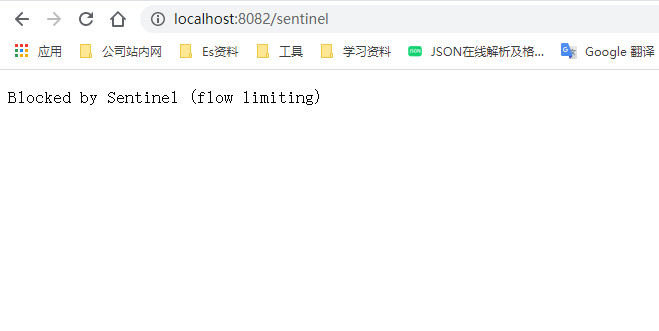
现在快速访问:http://localhost:8082/sentinel
查看实时监控页面:
其他功能的使用,大家可以参考官方文档自行摸索。
如何选择流控降级组件
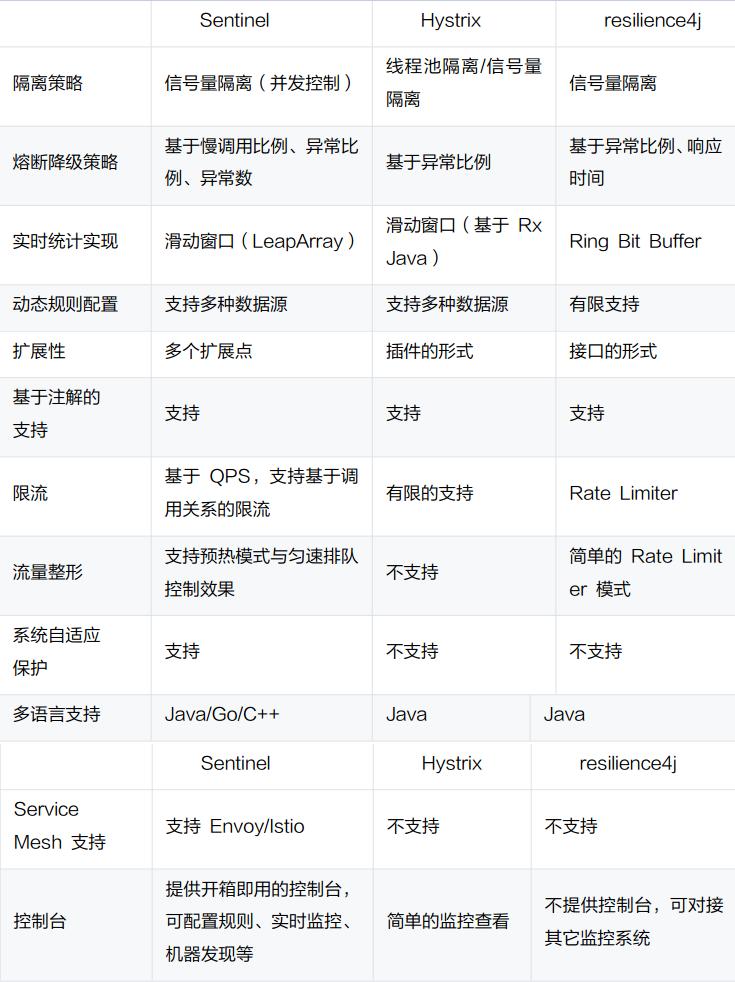
以下是 Sent inel 与其它fault-tolerance 组件的对比:
分布式事务
为什么需要分布式事务?
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单来说就是组成事务的各个单元处于不同数据库服务器上。 如何保证服务间的一致性?当在一条较长的微服务调用链中, 位于中间位置的微服务节点出现异常,如何保证整个服务的数据一致性?分布式一致性的引入, 一定不可避免带来性能问题, 如何更高效的解决分布式一致性问题,一直是我们致力于解决此问题的关键出发点。
分布式事务解决方案分类
刚性事务
刚性事务指的就是遵循本地事务四大特性(ACID)的强一致性事务。它的特点就是强一致性,要求组成事务的各个
单元马上提交或者马上回滚,没有时间弹性,要求以同步的方式执行。通常在单体架构项目中应用较多,一般都是
企业级应用(或者局域网应用)。例如:生成合同时记录日志,付款成功后生成凭据等等。但是,在时下流行的互
联网项目中,这种刚性事务来解决分布式事务就会有很多的弊端。其中最明显的或者说最致命的就是性能问题。
因为某个参与者不能自己提交事务,必须等待所有参与者执行OK了之后,一起提交事务,那么事务锁住的时间就
变得非常长,从而导致性能非常低下。基于此我们也就得出了一个结论,阶段越多,性能越差。
柔性事务
柔性事务是针对刚性事务而说的,我们刚才分析了刚性事务,它有两个特点,第一个强一致性,第二个近实时性
(NRT)。而柔性事务的特点是不需要立刻马上执行(同步性),且不需要强一致性。它只要满足基本可用和最终
一致就可以了。要想真正的明白,需要从BASE理论和CAP理论说起。
CAP理论和BASE理论
1)CAP理论
CAP理论,又叫做CAP原则,网上对他的概念描述非常的清晰,且一致。换句话说,我们在网上搜到的CAP理论的
描述,基本都是一样的。它的描述是这样的:
CAP指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition
tolerance)。其中,C,A,P的说明如下:
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端]的读写请求。(对数据更新具备高可用
性)
分区容错性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就
意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
CAP原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出
取舍。而对于分布式数据系统,分区容错性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一
致性和可用性之间取一个平衡。对于大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,
是目前多数分布式数据库产品的方向。
2)BASE理论
BASE理论是指,Basically Available(基本可用)、Soft-state( 软状态/柔性事务)、Eventual Consistency(最
终一致性)。
1、基本可用 BA:(Basically Available ):
指分布式系统在出现故障的时候,允许损失部分可用性,保证核心可用。但不等价于不可用。比如:搜索引擎0.5
秒返回查询结果,但由于故障,2秒响应查询结果;网页访问过大时,部分用户提供降级服务等。简单来说就是基
本可用。
2、软状态 S:( Soft State):
软状态是指允许系统存在中间状态,并且该中间状态不会影响系统整体可用性。即允许系统在不同节点间副本同步
的时候存在延时。简单来说就是状态可以在一段时间内不同步。
3、最终一致性 E:(Eventually Consistent ):
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态,不需要实时保证系统数据的强一致性。最终一
致性是弱一致性的一种特殊情况。BASE理论面向的是大型高可用可扩展的分布式系统,通过牺牲强一致性来获得
可用性。ACID是传统数据库常用的概念设计,追求强一致性模型。简单来说就是在一定的时间窗口内, 最终数据
达成一致即可。
BASE理论是基于CAP原则演化而来,是对CAP中一致性和可用性权衡的结果。
核心思想:即使无法做到强一致性,但每个业务根据自身的特点,采用适当的方式来使系统达到最终一致性。
分布式事务解决方案
二阶段提交2PC(3PC)
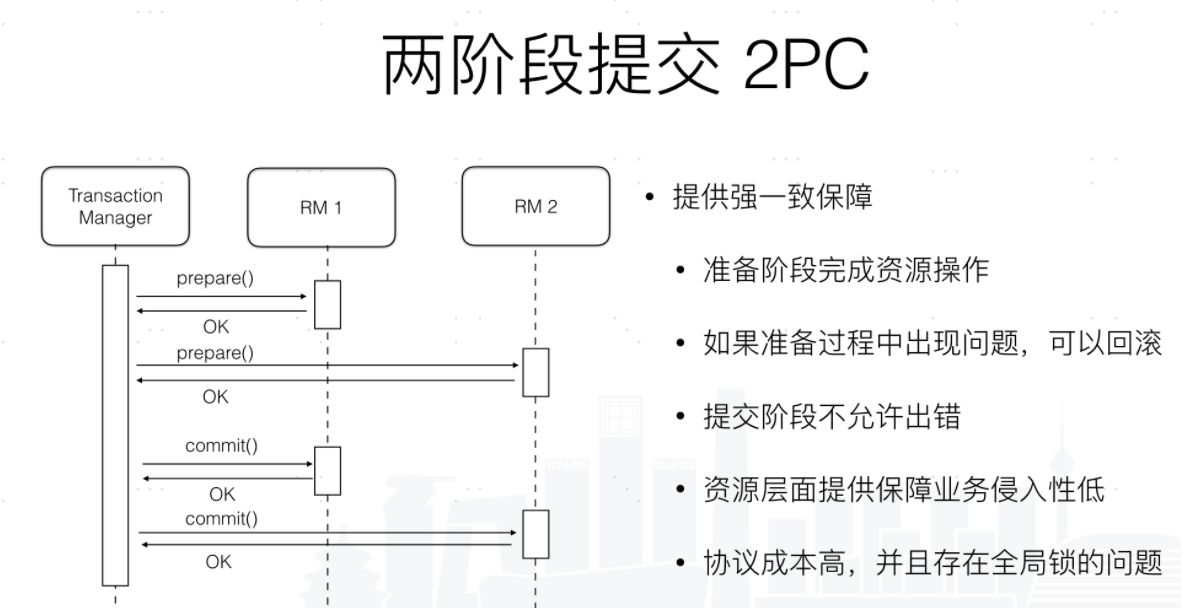
关于更多2pc与3pc的介绍,可以参考博文:2PC和3PC原理,这不是我们今天讨论的重点。
XA
XA 标准提出后的 20 多年间未能得到持续的演进,在学术界有协议优化和日志协同处理等相关的研究,在工业界使用 XA 落地方案的相对较少,主要集中在应用服务器的场景。XA 方案要求相关的厂商提供其具体协议的实现,目前大部分关系数据库支持了 XA 协议,但是支持程度不尽相同,例如,MySQL 在 5.7 才对 xa_prepare 语义做了完整支持。XA 方案被人诟病的是其性能, 其实更为严重的是对于连接资源的占用, 导致在高并发未有足够的连接资源来响应请求成为系统的瓶颈。在微服务架构下 XA 事务方案随着微服务链路的扩展成为一种反伸缩模式,进一步加剧了资源的占用。另外 XA 事务方案要求事务链路中的 resource 全部实现 XA 协议方可使用,若其中某一资源不满足,那么就无法保证整个链路的数据一致性。
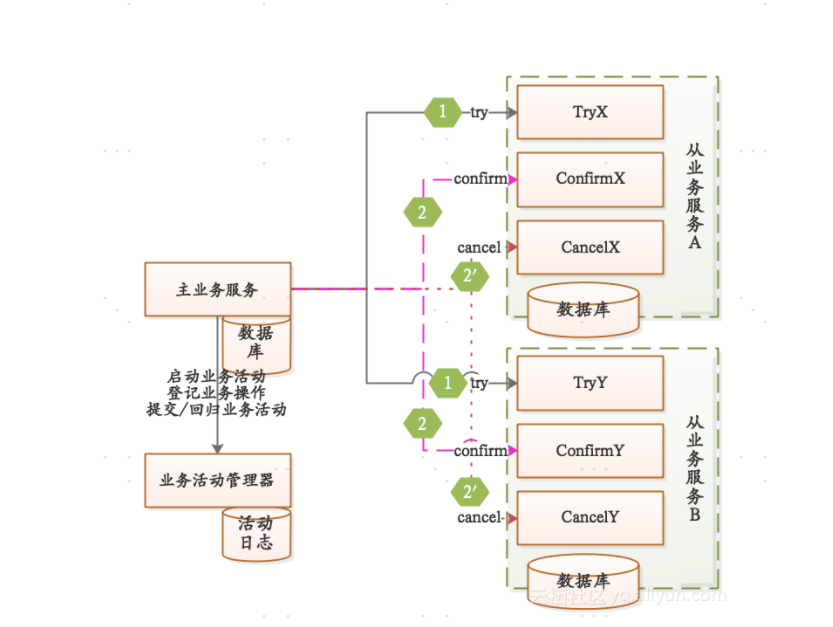
TCC补偿方案
TCC分别指的是Try,Confirm,Cancel。它是补偿型分布式事务解决方案。何为补偿呢?其实我们把TCC这3个部分分别做什么捋清楚,就很容理解了。首先,我们先来看下它们的主要作用:
Try 阶段主要是对业务系统做检测及资源预留。
Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是
不会出错的。即:只要Try成功,Confirm一定成功。
Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
由此,我们可以得出结论,就是在Try阶段进行尝试提交事务,当Try执行OK了,Confirm执行,且默认认为它一定成功。但是当Try提交失败了,则由Cancel处理回滚和资源释放。
从概念上 TCC 框架可以认为是一种万能框架,但是其难点是业务对于这三个接口的实现,开发成本相对较高,有较多业务难以做资源预留相关的逻辑处理, 以及是否需要在预留资源的同时从业务层面来保证隔离性。因此,这种模式比较适应于金融场景中易于做资源预留的扣减模型。
Saga

Saga其实是30年前的一篇数据库论文里提到的一个概念。在论文中一个Saga事务就是一个长期运行的事务,这个事务是由多个本地事务所组成, 每个本地事务有相应的执行模块和补偿模块,当saga事务中的任意一个本地事务出错了, 可以通过调用相关事务对应的补偿方法恢复,达到事务的最终一致性。
有了 TCC 解决方案为什么还需要 Saga 事务解决方案?上文提到了 TCC 方案中对业务的改造成本较大, 对于内部系统可以自上而下大刀阔斧的推进系统的改造, 但对于第三方的接口的调用往往很难推动第三方进行 TCC 的改造,让对方为了你这一个用户去改造 TCC 方案而其他用户并不需要,需求上明显也是不合理的。要求第三方业务接口提供正反接口比如扣款和退款,在异常场景下必要的数据冲正是合理的。另外,Saga 方案更加适应于工作流式的长事务方案并且可异步化。
最终一致性方案
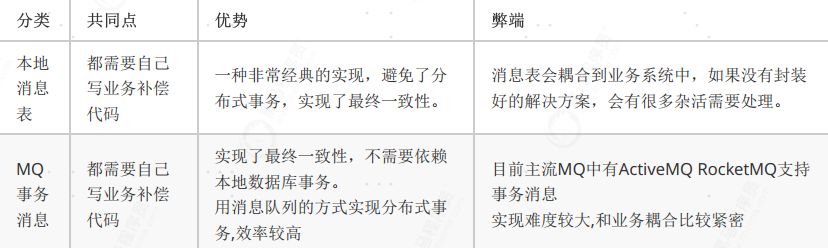
本地消息表
这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于
ebay。它和MQ事务消息的实现思路都是一样的,都是利用MQ通知不同的服务实现事务的操作。不同的是,针对
消息队列的信任情况,分成了两种不同的实现。本地消息表它是对消息队列的稳定性处于不信任的态度,认为消息
可能会出现丢失,或者消息队列的运行网络会出现阻塞,于是在数据库中建立一张独立的表,用于存放事务执行的
状态,配合消息队列实现事务的控制。
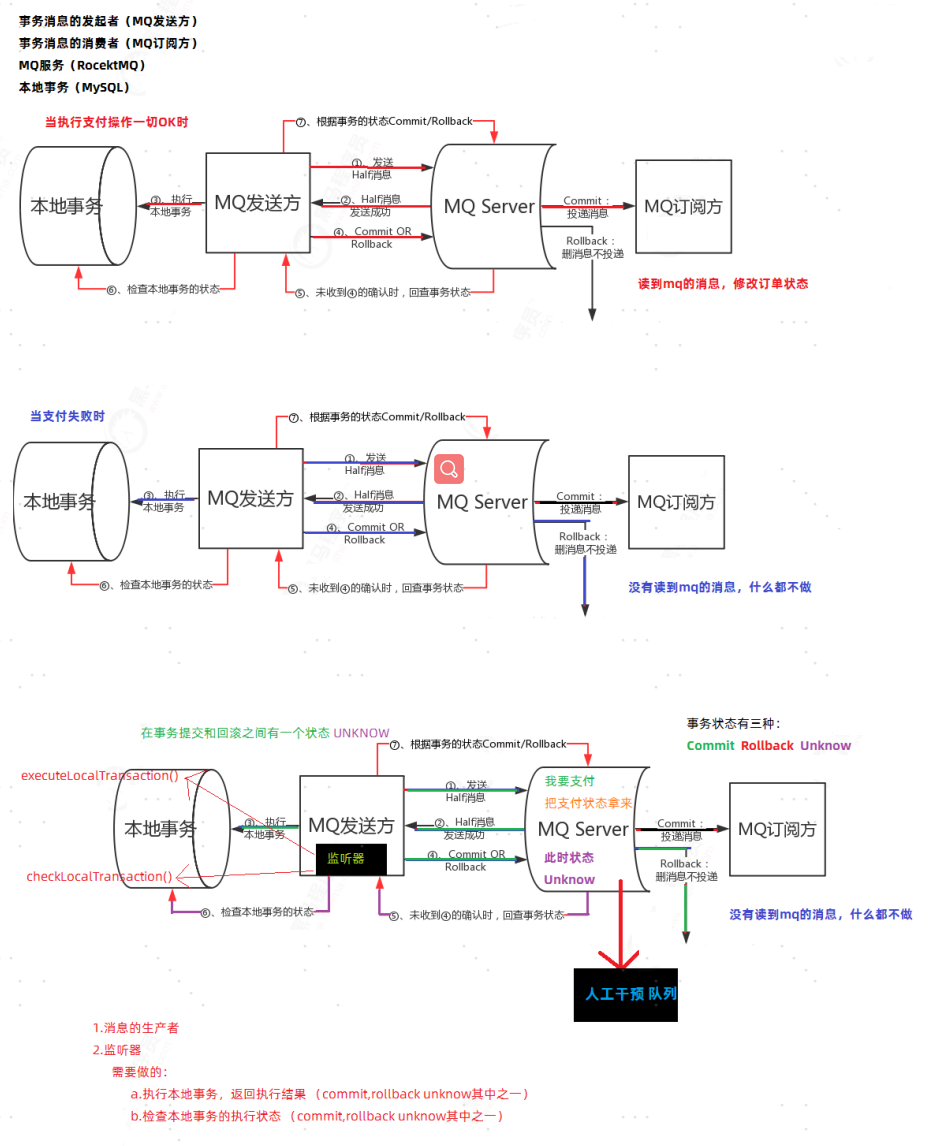
MQ事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,ActiveMQ,他们支持事务消息的方式也是类似于采用的
二阶段提交。但是有一些常用的MQ也不支持事务消息,比如 RabbitMQ 和 Kafka 都不支持。
以阿里的 RocketMQ 中间件为例,其思路大致为:
第一阶段Prepared消息,会拿到消息的地址。
第二阶段执行本地事务。
第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了
RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
用一个下单业务流程图来表示下:
两者对比
分布式事务框架Seata
FESCAR是阿里巴巴 开源的分布式事务中间件,以高效并且对业务0侵入的方式,解决微服务场景下面临的分布式
事务问题。Seata是fescar的升级版本,从2019年4月起,更名为seata。
seata的典型案例分析
在seata的官方网站中提供了一套详细的业务流程介绍,我们就以此为例,展开讲解。
首先是单体架构的事务场景介绍:电商购物中的3个业务模块(库存、订单和账户)。他们操作本地数据库,由于
同库同源,所以本地事务可以保证其一致性,如下图所示:
但是在微服务架构中,由于每个业务模块变成了独立的服务,且每个服务连接自己的数据库,此时由原来同库同源
变成了不同数据库不同数据源的情况,虽然每个服务自己的数据库操作仍然可以使用本地事务控制,但是要让服务
间的事务保持一致性就需要用到分布式事务了。
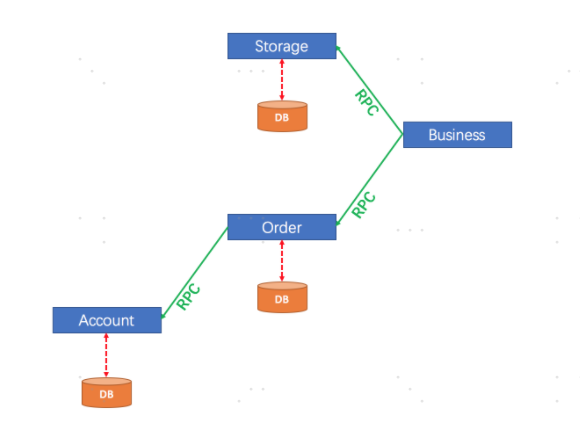
在此时,引入了seata,它提供了一个“完美”的解决方案。如下图所示:

在图中的三个和seata相关的组件,前面在介绍fescar的时候已经介绍了,它也是seata的基本组件,他们分别是:
1)事务协调器(TC):维护全局和分支事务的状态,驱动全局提交或回滚。
2)事务管理器(TM):定义全局事务的范围:开始全局事务,提交或回滚全局事务。
3)资源管理器(RM):管理分支事务的资源,与TC通信以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
seata管理分布式事务的生命周期
- TM要求TC开始新的全局事务。 TC生成表示全局事务的XID。
- XID通过微服务的调用链传播。
- RM将本地事务注册为XID到TC的相应全局事务的分支。
- TM要求TC提交或回滚XID的相应全局事务。
- TC在XID的相应全局事务下驱动所有分支事务,以完成分支提交或回滚。
库存服务
public interface StorageService {
/**
* deduct storage count
*/
void deduct(String commodityCode, int count);
}
订单服务
public interface OrderService {
/**
* create order
*/
Order create(String userId, String commodityCode, int orderCount);
}
账户服务
public interface AccountService {
/**
* debit balance of user's account
*/
void debit(String userId, int money);
}
主业务逻辑
public class BusinessServiceImpl implements BusinessService {
private StorageService storageService;
private OrderService orderService;
/**
* purchase
*/
public void purchase(String userId, String commodityCode, int orderCount) {
storageService.deduct(commodityCode, orderCount);
orderService.create(userId, commodityCode, orderCount);
}
}
public class OrderServiceImpl implements OrderService {
private OrderDAO orderDAO;
private AccountService accountService;
public Order create(String userId, String commodityCode, int orderCount) {
int orderMoney = calculate(commodityCode, orderCount);
accountService.debit(userId, orderMoney);
Order order = new Order();
order.userId = userId;
order.commodityCode = commodityCode;
order.count = orderCount;
order.money = orderMoney;
// INSERT INTO orders ...
return orderDAO.insert(order);
}
}
我们只需要一个@GlobalTransactional关于业务方法的注释:
@GlobalTransactional
public void purchase(String userId, String commodityCode, int orderCount) {
......
}
由Dubbo + SEATA提供支持的示例
步骤1:建立资料库
- 要求:具有InnoDB引擎的MySQL。
注意:实际上,在示例用例中,这3个服务应该有3个数据库。但是,为了简单起见,我们只能创建一个数据库并配置3个数据源。
使用您刚创建的数据库URL /用户名/密码修改Spring XML。
dubbo-account-service.xml dubbo-order-service.xml dubbo-storage-service.xml
<property name="url" value="jdbc:mysql://x.x.x.x:3306/xxx" />
<property name="username" value="xxx" />
<property name="password" value="xxx" />
步骤2:创建UNDO_LOG表
UNDO_LOG SEATA AT模式需要此表。
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
步骤3:建立表格,例如业务
DROP TABLE IF EXISTS `storage_tbl`;
CREATE TABLE `storage_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
UNIQUE KEY (`commodity_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
步骤4:启动服务器
- 从https://github.com/seata/seata/releases下载服务器软件包,将其解压缩。
Usage: sh seata-server.sh(for linux and mac) or cmd seata-server.bat(for windows) [options]
Options:
--host, -h
The host to bind.
Default: 0.0.0.0
--port, -p
The port to listen.
Default: 8091
--storeMode, -m
log store mode : file、db
Default: file
--help
e.g.
sh seata-server.sh -p 8091 -h 127.0.0.1 -m file
步骤5:运行示例
前往样品仓库:seata-samples
- 启动DubboAccountServiceStarter
- 启动DubboStorageServiceStarter
- 启动DubboOrderServiceStarter
- 运行DubboBusinessTester进行演示测试
TBD:用于运行演示应用程序的脚本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号