
【Python数据分析】工作日发文章比周末发文章访问量高?
前言
看前面有位朋友分析了一下每天某个时间发文章的访问量区别,以讨论非系统性因素对文章访问量的影响。之所以进一步讨论工作日和周末发文对文章访问量的影响,一是觉得很有意思,二是毕业设计与此有很大关系,三是觉得还是有点意义的,于是决定做一下这个工作。那么到底周末发文的访问量是不是总体来说比工作日低呢,请往下看。
工具
1.Python 3.5
2.BeautifulSoup 4.4.1
3.Requests模块
分析网页
由于之前的工作已知博客园博客展览页是要通过ajax请求换页,这里我采用了Requests模块,post一个请求即可。
payload = {"CategoryType":"SiteHome","ParentCategoryId":0,"CategoryId":808,"PageIndex":i,"ItemListActionName":"PostList"}
r = requests.post(posturl,data = payload)
这样就可以接收到第i页的博文列表的HTML内容了。
再来看一下我们要爬取的内容:

我们要爬取两个内容:发布时间 与 阅读量,这次我们爬取40—200页共161页的内容,并分两种情况:剔除3000以上访问量的文章以及考虑全部文章,然后要做的工作有两个:根据打扫过的数据,统计出一周周一到周日每天的文章总数与访问量总数,最后用WPS表格来制作出对比图。一提到解析网页,我毫无疑问地又想到了BeautifulSoup这款工具,简单好用,功能强大,推荐。
那么我们首先用BeautifulSoup抓出 class = post_item_foot 的 ‘发布于...’ 内容,以及抓出 class = 'article_view' 的 ’阅读(...)‘内容,再去除一些无用的部分,最后提取出日期三个数据y,m,d,以及阅读量,这里我们无需关心文章到底是谁发的或者具体时间。
(ps:Python 3.5下装BeautifulSoup老是不成功,后来发现有更高的版本4.4.1,就果断换了,然后一发成功,不知道什么原因)
部分代码如下:
bs = BeautifulSoup(r.text,"html.parser") #转化成beautifulsoup对象 View = bs.findAll(attrs = {'class' : 'article_view','class' : 'post_item_foot'}) #找出两个class内容 strallview = str(View) #转化为字符串 viewcountsmatch = re.findall('阅读\(\d+\)',strallview) viewdaymatch = re.findall('发布于 ....-\d+-\d+',strallview)
得出日期三个数据以后,这里我使用蔡勒公式(Zeller Fomula)直接计算出该日是星期几。蔡勒公式函数代码如下:
def ZellerFomula(y,m,d): if m == 1 or m == 2: y -= 1 m += 12 c = y // 100 y = y - c * 100 w = (c // 4) - 2 * c + (y + y // 4) + (13 * (m + 1) // 5) + d - 1 while w < 0: w += 7 w %= 7 if w == 0: w += 7 return w
然后就是简单的统计了。
这里我有一个考虑,由于日子越早的文章显然访问量总是会更高,所以为了在一定程度上抵消这种效应,我为每一页的20篇文章设置了一个权重:
weight = 1 - 0.0005 * (i - 40)
即i越大,页数越大,发布越早,访问量相应打一个折扣,这里我设置的最大折扣为92%,即第200页的文章相应的阅读量为其原来阅读量的92%,希望能稍微提升一下结果的公平性。
代码
这时候写出python代码(剔除3000+文章版本):
import requests import re import urllib from bs4 import BeautifulSoup def ZellerFomula(y,m,d): if m == 1 or m == 2: y -= 1 m += 12 c = y // 100 y = y - c * 100 w = (c // 4) - 2 * c + (y + y // 4) + (13 * (m + 1) // 5) + d - 1 while w < 0: w += 7 w %= 7 if w == 0: w += 7 return w f = open('keyvalue.txt','w') posturl = 'http://www.cnblogs.com/mvc/AggSite/PostList.aspx' daysum = [0,0,0,0,0,0,0,0,0] count = [0,0,0,0,0,0,0,0,0] for i in range(40,201): weight = 1 - 0.0005 * (i - 40) payload = {"CategoryType":"SiteHome","ParentCategoryId":0,"CategoryId":808,"PageIndex":i,"ItemListActionName":"PostList"} r = requests.post(posturl,data = payload) bs = BeautifulSoup(r.text,"html.parser") View = bs.findAll(attrs = {'class' : 'article_view','class' : 'post_item_foot'}) strallview = str(View) viewcountsmatch = re.findall('阅读\(\d+\)',strallview) viewdaymatch = re.findall('发布于 ....-\d+-\d+',strallview) #print(viewcountsmatch) #print(viewdaymatch) for j in range(len(viewcountsmatch)): vcm = viewcountsmatch[j] vcm = re.sub('阅读\(','',vcm) vcm = re.sub('\)','',vcm) #print(vcm) vc = int(vcm) if(vc > 3000): continue vdm = viewdaymatch[j] vdm = re.sub('发布于 ','',vdm) vdm = vdm.split('-',2) #print(vdm) ans = ZellerFomula(int(vdm[0]),int(vdm[1]),int(vdm[2])) #print(ans) ass = int(weight*vc) #print(str(ass)+ ' ' +str(vc)) daysum[ans] += ass count[ans] += 1 for i in range(1,8): f.write(str(daysum[i])+' ') f.write(str(count[i])) f.write('\n') f.close()
这代码写了很久,主要python很久没碰也不熟悉了。
运行结果与分析
然后我们运行就可以爬了,耗时大约40+秒,结果如下:
1.剔除版本数据

每行前面是161篇文章中星期1~7的文章访问总量,后面是文章数量。不算3000+访问以上的文章总数3104篇,贡献访问量1573399。
2.未剔除版本
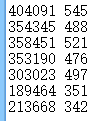
文章总数3220 = 161 x 20篇,贡献访问量2176232.
由上可以看出,3000+访问以上的较优质文章116篇,占比3.6%,其贡献的访问量为602833,占比27.7%,这也是预料之中的。
图表

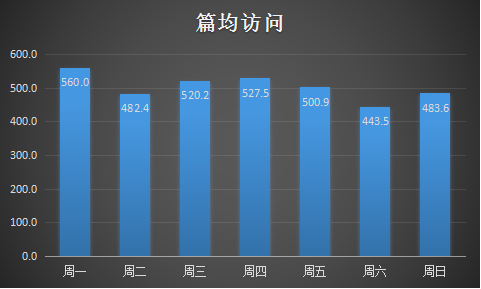
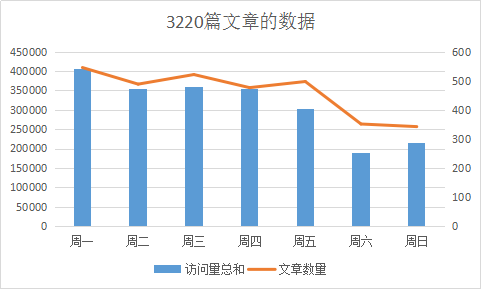
由图可得,两种方式总体上的差距并不大,从发文数量上看,周一发文最多,可能是大家都上班了,开始新一周的工作使然。随后周二到周四发文数量略有波动,但是都差不太多,并且比周一少。到周五由于放假了,文章数量也相应减少。到周末两天发文数量就有了很大下降,这也是预料之中。
从文章访问量来看,周一达到最大,随后又以较周一低的水平波动,到周末达到低谷,一大原因也是由于文章数量的减少。
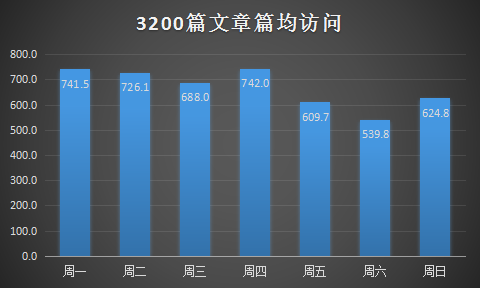
从平均访问情况来看,周一至周五的平均访问量普遍比周末稍高一点,印证了结论“工作日发文要比周末发文平均访问量多”,但是并没有多太多,其中周一达到最高峰,随后有波动,到周日有一个反弹,说明“周一效应”还是有一点的。
两幅图的有些显著的不同就是访问量来看,剔除3000+文章以后,周二的访问量有10W+的显著下降,这是否说明周二的时候高质量文章的访问在急速增长的原因呢。
补充
后来我发现光考虑篇均访问还不全面,因为周一即使篇均访问较高,但是它的文章数也是很大的,所以周一的文章必然会很快被覆盖过去,所以这里有一个性价比的问题,于是我又算了一项指标,即篇均访问与当日文章数量之比,底数越大小即文章数量越小,越晚被覆盖,曝光率越大,篇均访问越大自然带来的效应越大。所以有了下面这张图:
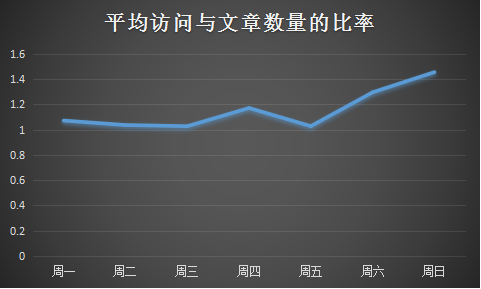
事实证明,性价比最高的发文日期居然是发的很少,访问很少的周末!
后续工作
虽然本次挖掘3220篇文章数据较小,感觉还是可以从速度方面进行优化的。
权重也是我自己简单设计的,这方面也可以进一步优化。
欢迎大家提出意见与建议。
结论与启示
所以说,如果你想要让你的文章获得更多的访问量,获得更大的影响力,尽量在工作日发文吧。当然,我前面说过,这些都只是非系统性因素,俗话说,打铁还需自身硬,提高自己文章的质量和水平才是获得更大文章影响力的决定性因素。希望广大园友能够致力于发布质量更高的文章,共同构建一个属于我们的优质的博客园。
本文就是上星期四晚上写就的,一直到现在才发,试下效果。事实是写完文章很难忍住不发,哈哈。
同样,爬取博客园只是为了学习之用,无其他目的,望理解。感谢韩子迟的工作。
作者:whatbeg
出处1:http://whatbeg.com/
出处2:http://www.cnblogs.com/whatbeg/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
更多精彩文章抢先看?详见我的独立博客: whatbeg.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号