Hive(十三)【Hive on Spark 部署搭建】
Hive on Spark 官网详情:https://cwiki.apache.org//confluence/display/Hive/Hive+on+Spark:+Getting+Started
一.安装Hive
具体安装参考:Hive(一)【基本概念、安装】
安装和Spark对应版本一起编译的Hive,当前官网推荐的版本关系如下:
| HiveVersion | SparkVersion |
|---|---|
| 1.1.x | 1.2.0 |
| 1.2.x | 1.3.1 |
| 2.0.x | 1.5.0 |
| 2.1.x | 1.6.0 |
| 2.2.x | 1.6.0 |
| 2.3.x | 2.0.0 |
| 3.0.x | 2.3.0 |
| master | 2.3.0 |
二.安装Spark
①在Hive所在机器安装Spark,配置Spark on Yarn模式。
可以将spark的日志,集成到Yarn上
②配置Spark的环境变量。
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile.d/my_env.sh
具体安装参考:Spark(一)【spark-3.0安装和入门】
三.向HDFS上传Spark纯净版jar包
使用不带hadoop的spark的包:spark-3.0.0-bin-without-hadoop.tgz
①解压
tar -zxvf /opt/software/spark/spark-3.0.0-bin-without-hadoop.tgz
②上传只HDFS的/spark-jars目录,该目录在下面需要配置
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
四.修改hive-site.xml文件
添加如下内容
<!--Spark依赖位置,上面上传jar包的hdfs路径-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎,使用spark-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
注意: hive.spark.client.connect.timeout的默认值是1000ms,如果执行hive的insert语句时,抛如下异常,可以调大该参数到10000ms
FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session d9e0224c-3d14-4bf4-95bc-ee3ec56df48e
五.测试
①启动hive的metstore服务和hive客户端
[root@hadoop102 ~]$ hive --service metastore
[root@hadoop102 hive]$ bin/hive
②创建一张测试表
hive (default)> create table student(id int, name string);
③通过insert测试效果
hive (default)> insert into table student values(1,'abc');
若结果如下,则说明配置成功,第一次初始化spark session比较费时间,下次执行就很快了。
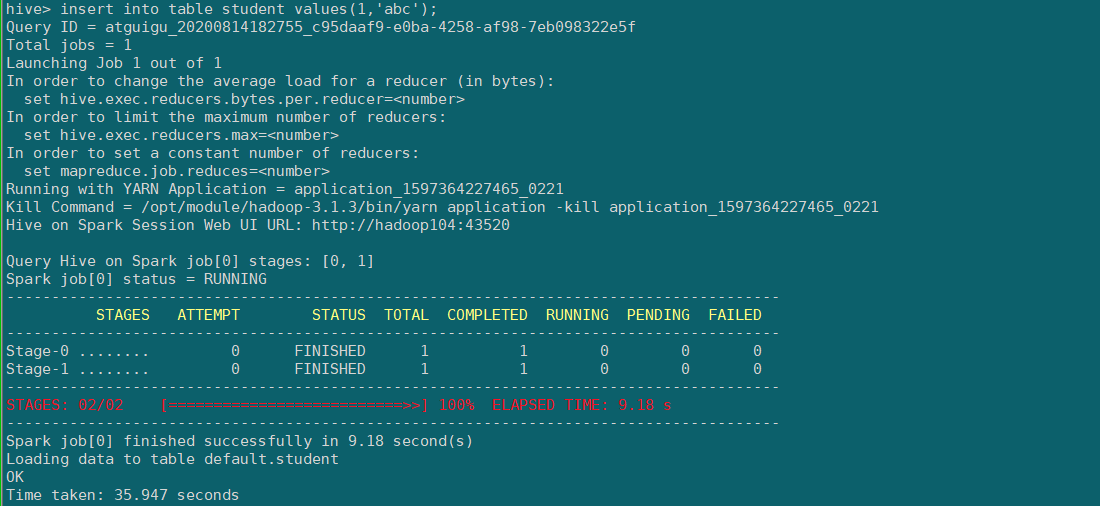
hive on spark 的相关原理可参考
FAQ
1.执行sql语句,报错信息。
hive> insert into table student values(1,'abc');
Query ID = atguigu_20200814150018_318272cf-ede4-420c-9f86-c5357b57aa11
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job failed with java.lang.ClassNotFoundException: org.apache.spark.AccumulatorParam
FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.
原因:由于当前的hive的版本3.1.2,spark版本3.0.0,只能自己编译。
建议用官方发布的hive+spark版本搭配。
2.启动hive的metstore服务,不然可能报错
hive> insert into table student values(1,'abc');
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient

 浙公网安备 33010602011771号
浙公网安备 33010602011771号