
Spring AI 实战:构建智能对话体系
Spring AI 实战:构建智能对话系统的完整指南
项目概述
经过半个月的磕磕碰碰的学习与疯狂的和AI的对话,我构建了一个基于 Spring AI 的智能对话系统。本文将分享从零到一的完整开发历程,涵盖核心概念、技术实现和踩坑经验。
学习目标全景
核心技术栈掌握
- 流式接口:实现实时对话体验
- 对话上下文联想:基于 Redis 的滑动窗口记忆
- LLM 模型增强:RAG 检索增强生成
- 矢量库存储:PgVector 实战应用
- 文档智能处理:多格式解析与语义分块
- MCP运用:调用PGSQL MCP进行数据查询
- 用户画像标签构建:LFU->TinyLFU->W-TinyLFU算法,结合时间线绘画用户画像
项目实战价值
- 快速掌握 Spring AI 核心用法
- 探索 AI 技术在实际项目中的落地场景
- 构建完整的 AI 应用架构思维
技术演进路径
基础对话流程 (无增强的LLM)
流程解释:
- 用户在前端界面输入问题(Prompt)。
- 前端通过HTTP调用后端的Spring
Controller。 - Controller调用Spring AI的
ChatClient。 ChatClient将请求路由到配置的LLM模型(如通义千问)。- LLM基于其内置知识生成回复。
- 响应返回给前端渲染。
特点:简单、快速,但答案完全依赖模型的内部知识,无法处理私有、实时信息,容易产生“幻觉”
RAG (检索增强生成) 流程
这是核心增强流程,解决了基础流程的痛点。它展示了如何通过外部知识库来增强LLM的能力。
流程解释 (在线部分):
- 用户提问。
- Controller接收到问题后,不直接发送给LLM,而是先交给
检索器(Retriever)。 - 检索器将问题转换为向量,并在矢量数据库中执行相似度搜索,找到最相关的几个文本片段(Context)。
- 将这些片段(Context)和原始问题一起,组装成一个结构化的增强Prompt(例如:“请根据以下上下文回答:…[context]…问题:…[question]…”)。
- 将增强后的Prompt发送给LLM。
- LLM的回复是基于提供的上下文生成的,因此更准确、更相关。
- 返回最终答案。
特点:答案质量高、有据可查、可处理私有和实时数据。这是构建企业级知识库问答系统的核心架构。
智能体 (Agent) 工作流
智能体将能力从“回答问题”提升到“完成任务”。它引入了“思考-行动”循环和工具调用。
流程解释:
- 用户提出一个复杂的、需要多步操作的请求。
- 智能体(Agent) 接管请求,开始它的“思考”循环。
- 智能体根据当前情况规划下一步应该做什么(“我需要先搜索航班”)。
- 智能体决定需要调用一个工具(Tool) 来执行动作(调用
FlightSearchTool)。 - 工具执行完毕(例如,调用外部机票搜索API),返回结果(JSON格式的航班列表)给智能体。
- 智能体观察工具的结果,并进行下一步思考(“现在我有了航班列表,我需要找到最便宜的那一班”)。
- 这个“思考-行动-观察”循环会持续进行,直到智能体认为它已经收集到足够的信息来组装最终答案。
- 智能体生成最终回复并返回。
特点:功能强大、自主性强、能够完成复杂任务。是通向“AI自主员工”的关键。
整合视图与可观测性
这张图展示了在一个完整的系统中,以上所有概念如何协同工作,并融入评估和可观测性。
流程解释:
- 入口:所有请求通过Controller进入,可以根据路由或内容分发到不同的处理流程(基础、RAG、Agent)。
- 核心流程:三个核心流程共享并依赖外部的支撑系统(数据库、工具库)。
- 可观测性:在所有关键步骤上,都有日志、指标、链路追踪的埋点,数据流入可观测性平台(如Prometheus+Grafana、SkyWalking)。
- 评估与优化:
- 人工评估:定期抽样检查回答质量。
- 自动评估:使用评估器自动判断回答的相关性、事实准确性等。
- 评估结果形成一个反馈环,用于持续优化Prompt设计、检索器参数、模型选择等,形成一个自我改进的系统。
️ 系统架构设计
核心模块划分
┌─────────────────┐
│ 前端交互层 │ - Vue 3 + Element Plus
├─────────────────┤
│ API网关层 │ - Spring Boot 3.4.0
├─────────────────┤
│ AI能力层 │ - Spring AI + 通义千问
├─────────────────┤
│ 数据持久层 │ - PostgreSQL + MongoDB + Redis
└─────────────────┘
关键技术选型
| 类别 | 技术栈 | 版本 | 用途 |
|---|---|---|---|
| 后端框架 | Spring Boot | 3.4.0 | 应用框架 |
| AI框架 | Spring AI | 1.0.0 | AI能力核心 |
| 向量数据库 | PostgreSQL + PgVector | Latest | 向量存储检索 |
| 缓存 | Redis | Latest | 会话记忆 |
| 文档数据库 | MongoDB | Latest | 聊天历史 |
核心功能实现
1. 智能对话引擎
流式对话实现
// 关键代码:流式响应处理
@GetMapping("/streamChat")
public Flux<String> streamChat(@RequestParam String query,
@RequestParam String sessionId) {
return chatClient.prompt(query)
.advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, sessionId))
.stream()
.content();
}技术亮点:
- 基于 Reactor 的响应式流处理
- 实时 token 推送,提升用户体验
- 自动会话记忆管理
上下文记忆管理
// Redis 记忆存储配置
@Bean
public MessageWindowChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(redisRepository)
.maxMessages(20) // 保留最近20轮对话
.build();
}2. RAG 检索增强系统
文档处理流水线
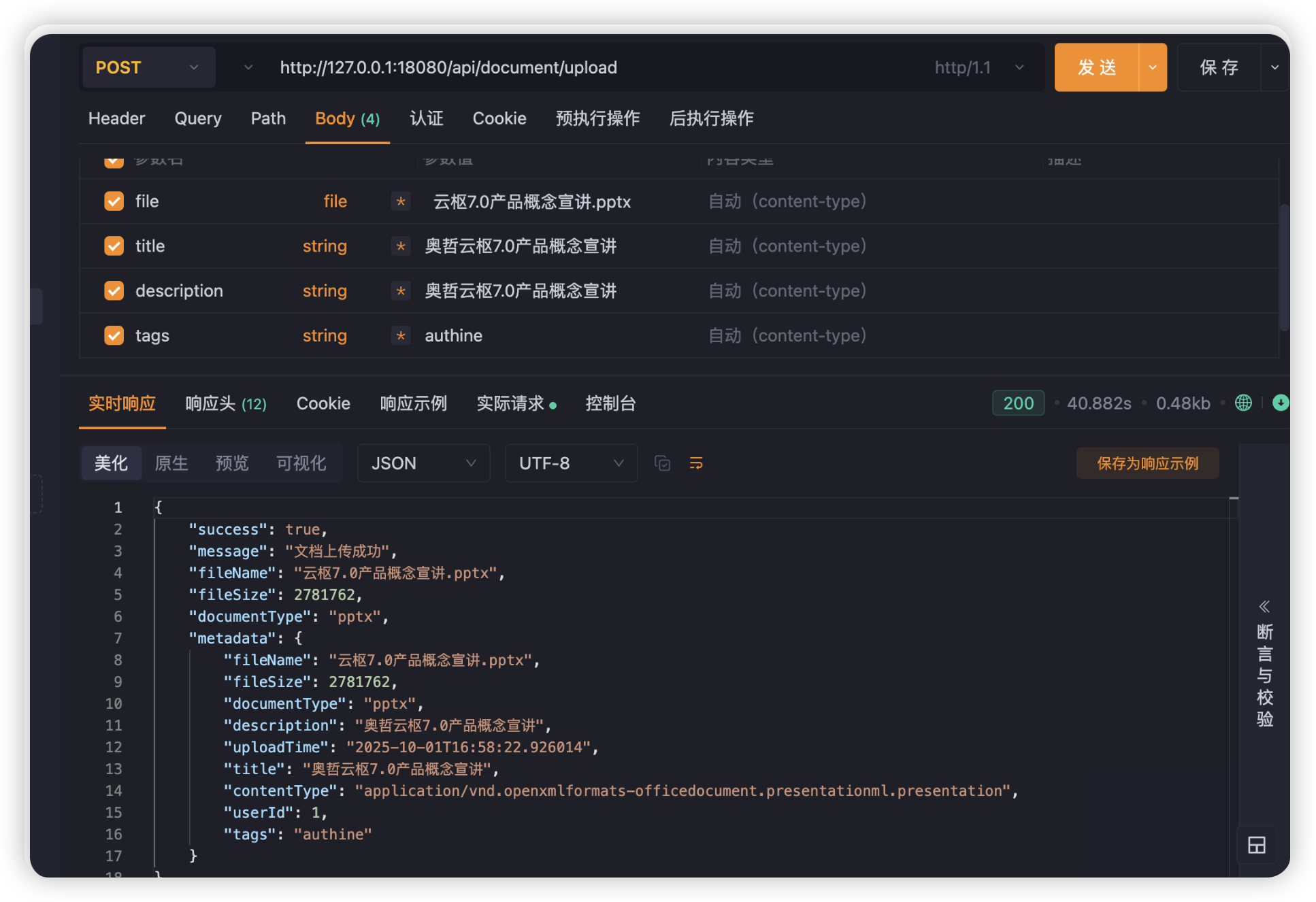
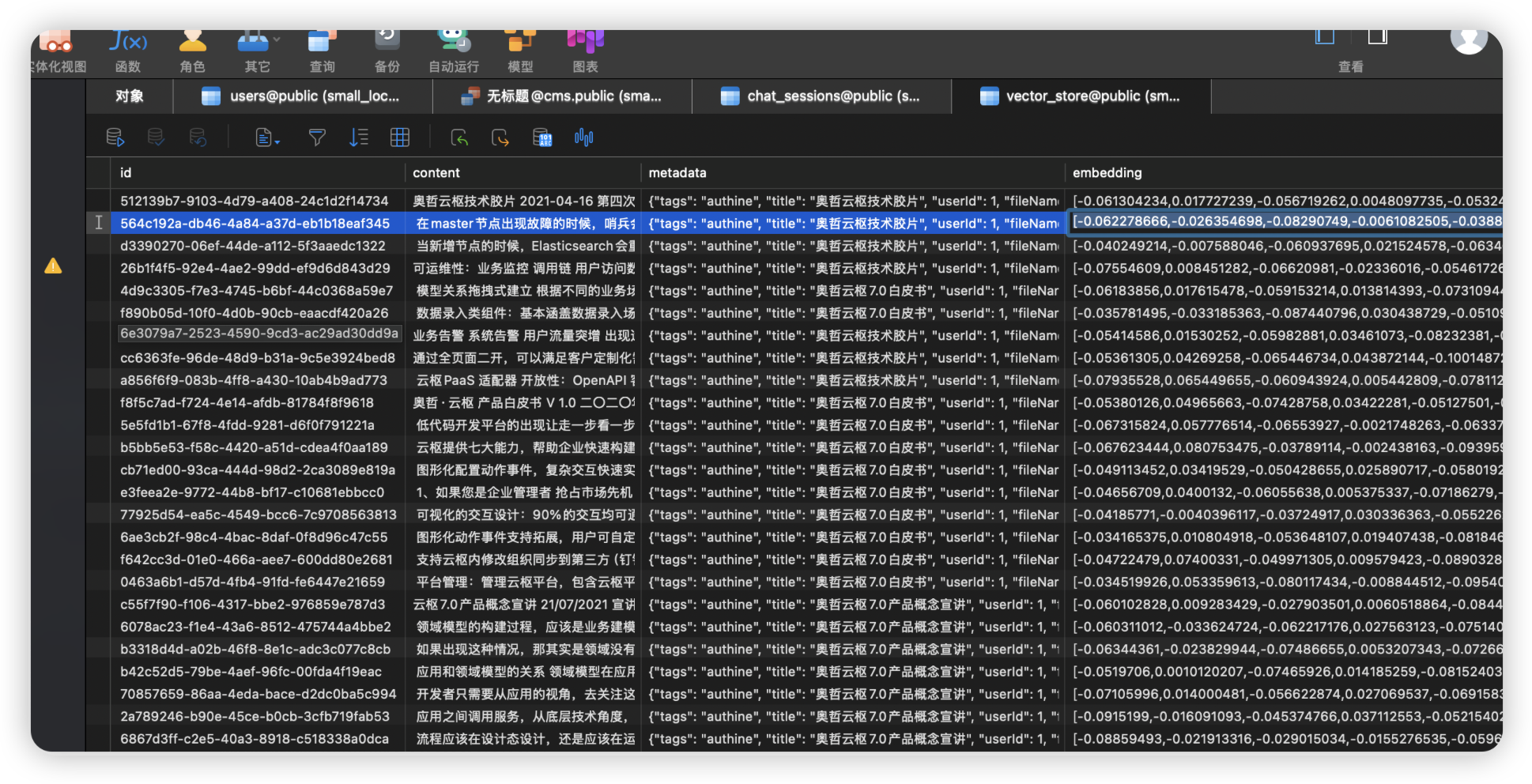
文档上传 → 格式解析 → 文本分块 → 向量化 → 存储检索智能文本分块策略
- 语义化分割:按段落边界保持语义完整
- 动态块大小:短文档500字符,长文档1000字符
- 重叠处理:200字符重叠避免上下文断裂
- 中文优化:按句子标点智能分割
向量检索核心
public Flux<String> ragStreamChat(String query, String sessionId) {
List<Document> relevantDocs = vectorStore.similaritySearch(query);
if (CollectionUtils.isEmpty(relevantDocs)) {
return streamChat(query, sessionId, false, query);
}
String enhancedPrompt = buildRagPrompt(query, relevantDocs);
return streamChat(enhancedPrompt, sessionId, true, query);
}3. 多格式文档支持
| 文档格式 | 解析技术 | 特点 |
|---|---|---|
| Apache PDFBox | 保持文本结构和格式 | |
| Word | Apache POI | 支持.doc/.docx |
| PowerPoint | Apache POI | 提取幻灯片内容 |
| Markdown | Tika | 原生支持 |
| 纯文本 | Tika | 简单高效 |
项目成果展示
功能完成度
- ✅ 基础对话聊天
- ✅ 流式对话响应
- ✅ 上下文联想记忆
- ✅ 文档上传解析
- ✅ 向量库存储检索
- ✅ RAG 增强对话
- ✅ 对话历史管理
界面展示
登录注册模块
AI 会话模块
初始对话页面
历史会话页面&Markdown格式渲染
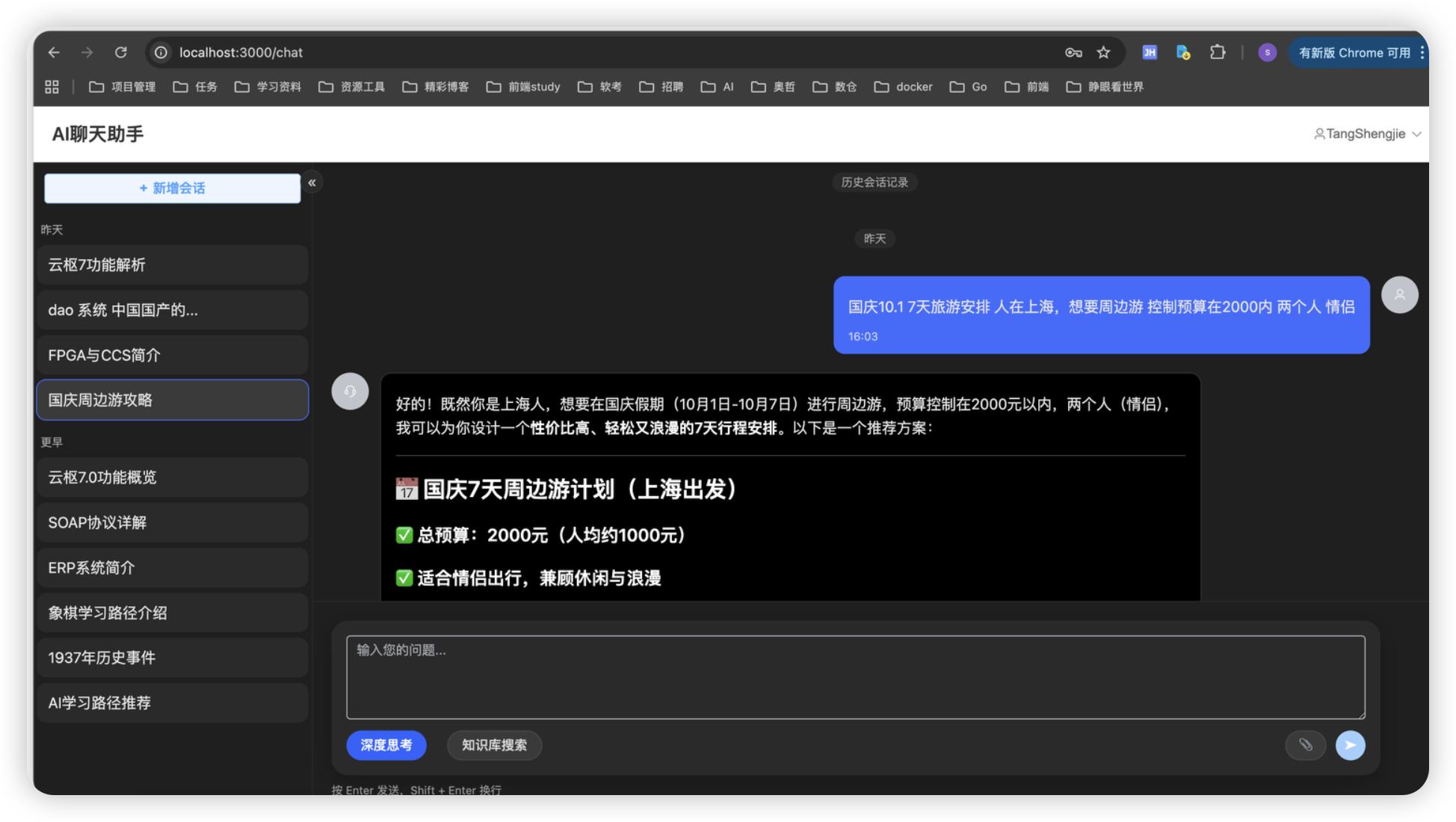
但是很不幸,我不会前端,在流式输出的时候,他不能转成Markdown格式,只能在我渲染完成后变成Markdown格式。
文档上传与解析&向量库存储
RAG 增强
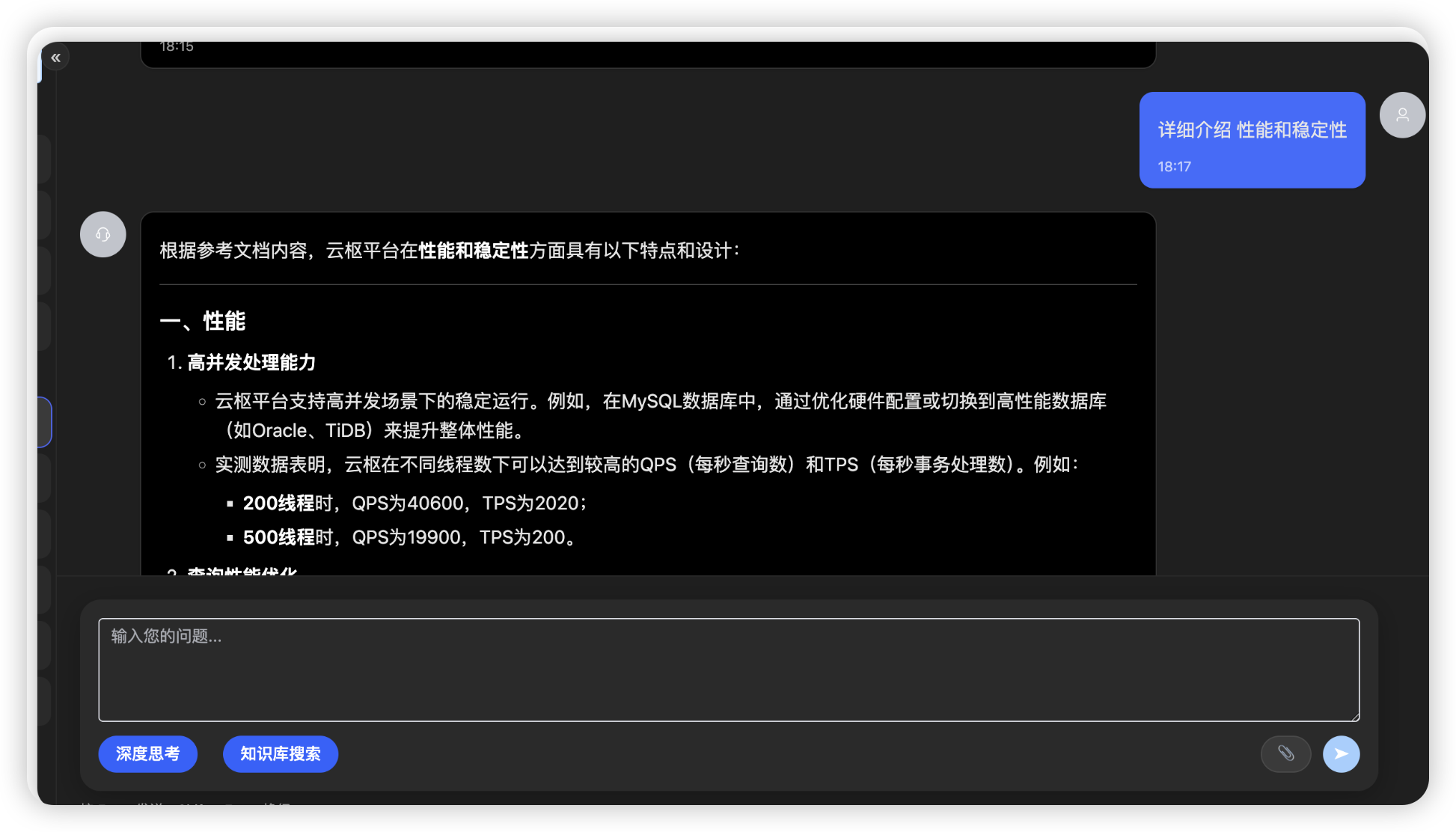
其实这张图就解释了上下文联想和RAG的LLB增强
技术难点与解决方案
难点1:流式输出与Markdown渲染
问题:流式输出时无法实时渲染Markdown格式
解决方案:前端先按文本流显示,完成后统一转换为Markdown(暂时无法一边流式输出,一边进行Markdown格式化)
难点2:中文文本分块
问题:传统按固定长度分块会切断中文语义
解决方案:基于标点符号的语义化分块算法
难点3:向量检索精度
问题:相似度检索结果不准确
解决方案:调整块大小、重叠策略和相似度阈值
性能优化实践
记忆管理优化
- 短期记忆:Redis存储最近20轮对话,快速访问
- 长期记忆:MongoDB归档完整历史,支持检索
- 滑动窗口:控制上下文长度,优化token消耗
检索效率提升
- 向量索引优化
- 相似度阈值调优
- 检索结果重排序
未来规划
短期目标
- MCP调度系统集成
- Spring Agent链式调用
- 会员标签算法实现
长期愿景
- 智能用户画像系统
- AI社交推荐(猜你喜欢、灵魂伴侣)
- 多模态交互支持
学习心得
技术收获
- Spring AI生态:深入理解AI应用开发范式
- 向量数据库:掌握相似度检索的核心原理
- RAG模式:学会用外部知识增强LLM能力
- 系统架构:构建完整AI应用的技术栈组合
实践感悟
“不想在凌晨加班,那边在清晨读书。”
资源分享
学习资料与方法
- Spring AI Exapmle
- JAVA AI官方文档
- spring-ai-alibaba-examples
- Cursor Max Model(code-supernova-1-million)
- GitHub Copliot Chat
- DeepSeek
项目地址
[GitHub项目链接]:
https://github.com/shengjieTang4419/ai_cms
https://github.com/shengjieTang4419/ai_cms_front
欢迎Star & Fork!
交流互动
如果你对Spring AI或AI应用开发有任何问题,欢迎在评论区交流讨论。我也会持续分享更多AI实战经验!
作者:shengjie.tang
更新时间:2025年10月
版权声明:转载请注明出处,谢谢!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号