

11-机器学习-xgboost极限梯度提升算法 (boosting提升法)
总结
xgboost(极限梯度提升算法):在分类和回归上都拥有超高性能的先进评估器
梯度提升树原理:通过不停的迭代,得到很多的弱评估器,当迭代结束后得到 k 个弱评估模型就是一棵树,每棵树都会有叶子节点,给每个叶子节点赋一个权重值,权重值累加得结果就是我们最终得梯度提升树返回得预测结果
xgboost
xgboost简介
- XGBoost全称是eXtreme Gradient Boosting,可译为极限梯度提升算法。它由陈天奇所设计,致力于让提升树突破自身的计算极限,以实现运算快速,性能优秀的工程目标。和传统的梯度提升算法相比,XGBoost进行了许多改进,并且已经被认为是在分类和回归上都拥有超高性能的先进评估器。 在各平台的比赛中、高科技行业和数据咨询等行业也已经开始逐步使用XGBoost,了解这个算法,已经成为学习机器学习中必要的一环。
- 性能超强的算法往往有着复杂的原理,XGBoost也不能免俗,因此它背后的数学深奥复杂。但是授课中,我们不会重点讲解和关注其算法的底层实现和原理,只要大家能够把XGBoost合理的运用在我们的机器学习项目中且能够创造真实价值就足够了。
xgboost库与XGB的sklearn API
- 在开始讲解XGBoost的细节之前,我先来介绍我们可以调用XGB的一系列库,模块和类。陈天奇创造了XGBoost之后,很快和一群机器学习爱好者建立了专门调用XGBoost库,名为xgboost。xgboost是一个独立的,开源的,专门提供XGBoost算法应用的算法库。它和sklearn类似,有一个详细的官方网站可以供我们查看,并且可以与C,Python,R,Julia等语言连用,但需要我们单独安装和下载。
- xgboost documents:https://xgboost.readthedocs.io/en/latest/index.html
- xgboost库要求我们必须要提供适合的Scipy环境,如果你是使用anaconda安装 的Python,你的Scipy环境应该是没有什么问题。


我们有两种方式可以来使用我们的xgboost库
第一种方式:是直接使用xgboost库自己的建模流程

- 其中最核心的,是DMtarix这个读取数据的类,以及train()这个用于训练的类。与sklearn把所有的参数都写在类中的方式不同,xgboost库中必须先使用字典设定参数集,再使用train来将参数及输入,然后进行训练。会这样设计的原因,是因为XGB所涉及到的参数实在太多,全部写在xgb.train()中太长也容易出错。在这里,我为大家准备了 params可能的取值以及xgboost.train的列表,给大家一个印象。

第二种方式:使用XGB库中的sklearn的API
- 这是说,我们可以调用如下的类,并用我们sklearn当中惯例的实例化,fit和predict的流程来运行XGB,并且也可以调用属性比如coef_等等。当然,这是我们回归的类,我们也有用于分类的类。他们与回归的类非常相似,因此了解一个类即可。

- 看到这长长的参数列表,可能大家会感到头晕眼花——没错XGB就是这么的复杂。但是眼尖的小伙伴可能已经发现了, 调用xgboost.train和调用sklearnAPI中的类XGBRegressor,需要输入的参数是不同的,而且看起来相当的不同。但其实,这些参数只是写法不同,功能是相同的。
- 比如说,我们的params字典中的第一个参数eta,其实就是我们XGBRegressor里面的参数learning_rate,他们的含义和实现的功能是一模一样的。只不过在sklearnAPI中,开发团队友好地帮助我们将参数的名称调节成了与sklearn中其他的算法类更相似的样子。
两种使用方式的区别:
- 使用xgboost中设定的建模流程来建模,和使用sklearnAPI中的类来建模,模型效果是比较相似的,但是xgboost库本身的运算速度(尤其是交叉验证)以及调参手段比sklearn要简单。
- 但是,我们前期已经习惯使用sklearn的调用方式,我们就先使用sklearn的API形式来讲解和使用XGB。
梯度提升算法:XGBoost的基础是梯度提升算法,因此我们必须先从了解梯度提升算法开始。
- 梯度提升(Gradient boosting):
- 是构建预测模型的最强大技术之一,它是集成算法中提升法(Boosting)的代表算法。集成算法通过在数据上构建多个弱评估器,汇总所有弱评估器的建模结果,以获取比单个模型更好的回归或分类表现。
- 集成不同弱评估器的方法有很多种。就像我们曾经在随机森林的课中介绍的,一次性建立多个平行独立的弱评估器的装袋法。也有像我们今天要介绍的提升法这样,逐一构建弱评估器,经过多次迭代逐渐累积多个弱评估器的方法。
- 我们知道梯度提升法是集成算法中提升法(Boosting)的代表算法。回顾:在集成学习讲解中我们说boosting算法是将其中参与训练的基础学习器按照顺序生成。序列方法的原理是利用基础学习器之间的依赖关系。通过对之前训练中错误标记的样本赋值较高的权重,可以提高整体的预测效果。
- 基于梯度提升的回归或分类模型来讲,其建模过程大致如下:最开始先建立一棵树,然后逐渐迭代,每次迭代过程中都增加一棵树,逐渐形成众多树模型集成的强评估器。
- 是构建预测模型的最强大技术之一,它是集成算法中提升法(Boosting)的代表算法。集成算法通过在数据上构建多个弱评估器,汇总所有弱评估器的建模结果,以获取比单个模型更好的回归或分类表现。

- XGB算法原理:
- XGB中构建的弱学习器为CART树,这意味着XGBoost中所有的树都是二叉的。
- 在讲解决策树算法原理时,我们主要讲解的是信息熵实现的树模型,除此外,还有一种是基于基尼系数实现的CART树,它既可以处理分类也可以处理回归问题,并且构建出的只能是二叉树。
- XGBT中的预测值是所有弱分类器上的叶子节点权重直接求和得到,计算叶子权重是一个复杂的过程。
- 那么什么是叶子的权重呢?
- 先来举个例子,我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,这个分值就是叶子节点的权重。假设,我们训练出了2棵树tree1和tree2,两棵树的结论的打分值累加起来便是最终的结论,所以小男孩的预测分数就是两棵树中小男孩所落到的结点的分数相加:2 + 0.9 = 2.9。爷爷的预测分数同理:-1 + (-0.9)= -1.9。具体如下图所示::
- XGB中构建的弱学习器为CART树,这意味着XGBoost中所有的树都是二叉的。

- 因此,假设这个集成模型XGB中总共有k棵决策树,则整个模型在这个样本i上给出的预测结果为:

-
- yi(k)表示k课树叶子节点权重的累和或者XGB模型返回的预测结果,K表示树的总和,fk(xi)表示第k颗决策树返回的叶子节点的权重(第k棵树返回的结果)
- 从上面的式子来看,在集成中我们需要的考虑的第一件事是我们的超参数K,究竟要建多少棵树呢?
- 试着回想一下我们在随机森林中是如何理解n_estimators的:n_estimators越大,模型的学习能力就会越强,模型也 越容易过拟合。在随机森林中,我们调整的第一个参数就是n_estimators,这个参数非常强大,常常能够一次性将模 型调整到极限。在XGB中,我们也期待相似的表现,虽然XGB的集成方式与随机森林不同,但使用更多的弱分类器来 增强模型整体的学习能力这件事是一致的。
from xgboost import XGBRegressor as XGBR from sklearn.ensemble import RandomForestRegressor as RFR from sklearn.datasets import load_boston from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import KFold, cross_val_score, train_test_split data = load_boston() X = data.data y = data.target Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
xgb
reg = XGBR(n_estimators=100).fit(Xtrain,Ytrain) reg.score(Xtest,Ytest) # 0.9050988954757183 MSE(Ytest,reg.predict(Xtest)) # 8.830916470718748 cross_val_score(reg,Xtrain,Ytrain,cv=5).mean() # 0.7995062802699481
随机森林
rfr = RFR(n_estimators=100).fit(Xtrain,Ytrain) rfr.score(Xtest,Ytest) # 0.8951649975839067 MSE(Ytest,rfr.predict(Xtest)) # 9.755304263157894 cross_val_score(rfr,Xtrain,Ytrain,cv=5).mean() # 0.7940731408344127 model_count = [] scores = [] for i in range(50,170): xgb = XGBR(n_estimators=i).fit(Xtrain,Ytrain) score = xgb.score(Xtest,Ytest) scores.append(score) model_count.append(i) %matplotlib inline import matplotlib.pyplot as plt plt.plot(model_count,scores)
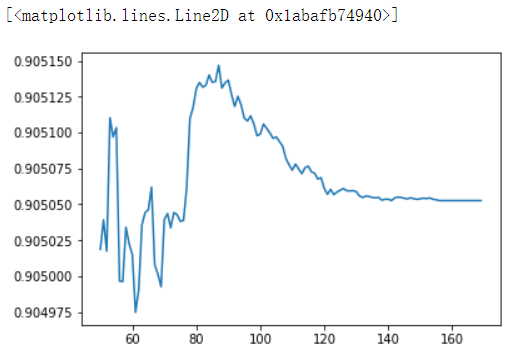
重要参数
有放回随机抽样:subsample(0-1,默认为1)
- 确认了有多少棵树之后,我们来思考一个问题:建立了众多的树,怎么就能够保证模型整体的效果变强呢?集成的目的是为了模型在样本上能表现出更好的效果,所以对于所有的提升集成算法,每构建一个评估器,集成模型的效果都会比之前更好。也就是随着迭代的进行,模型整体的效果必须要逐渐提升,最后要实现集成模型的效果最优。要实现这个目标,我们可以首先从训练数据上着手。
- 我们训练模型之前,必然会有一个巨大的数据集。我们都知道树模型是天生容易发生过拟合,并且如果数据量太过巨 大,树模型的计算会非常缓慢,因此,我们要对我们的原始数据集进行有放回抽样(bootstrap)。有放回的抽样每 次只能抽取一个样本,若我们需要总共N个样本,就需要抽取N次。每次抽取一个样本的过程是独立的,这一次被抽到的样本会被放回数据集中,下一次还可能被抽到,因此抽出的数据集中,可能有一些重复的数据。
- 在无论是装袋还是提升的集成算法中,有放回抽样都是我们防止过拟合,让单一弱分类器变得更轻量的必要操作。实际应用中,每次抽取50%左右的数据就能够有不错的效果了。sklearn的随机森林类中也有名为boostrap的参数来帮 助我们控制这种随机有放回抽样。
- 在梯度提升树中,我们每一次迭代都要建立一棵新的树,因此我们每次迭代中,都要有放回抽取一个新的训练样本。不过,这并不能保证每次建新树后,集成的效果都比之前要好。因此我们规定,在梯度提升树中,每构建一个评估器,都让模型更加集中于数据集中容易被判错的那些样本。
- 首先我们有一个巨大的数据集,在建第一棵树时,我们对数据进行初次又放回抽样,然后建模。建模完毕后,我们对模型进行一个评估,然后将模型预测错误的样本反馈给我们的数据集,一次迭代就算完成。紧接着,我们要建立第二棵决策树,于是开始进行第二次又放回抽样。但这次有放回抽样,和初次的随机有放回抽样就不同了,在这次的抽样中,我们加大了被第一棵树判断错误的样本的权重。也就是说,被第一棵树判断错误的样本,更有可能被我们抽中。
- 基于这个有权重的训练集来建模,我们新建的决策树就会更加倾向于这些权重更大的,很容易被判错的样本。建模完毕之后,我们又将判错的样本反馈给原始数据集。下一次迭代的时候,被判错的样本的权重会更大,新的模型会更加倾向于很难被判断的这些样本。如此反复迭代,越后面建的树,越是之前的树们判错样本上的专家,越专注于攻克那些之前的树们不擅长的数据。对于一个样本而言,它被预测错误的次数越多,被加大权重的次数也就越多。我们相信,只要弱分类器足够强大,随着模型整体不断在被判错的样本上发力,这些样本会渐渐被判断正确。如此就一定程度上实现了我们每新建一棵树模型的效果都会提升的目标。
- 在sklearn中,我们使用参数subsample来控制我们的随机抽样。在xgb和sklearn中,这个参数都默认为1且不能取到 0,这说明我们无法控制模型是否进行随机有放回抽样,只能控制抽样抽出来的样本量大概是多少。
- 注意:那除了让模型更加集中于那些困难错误样本,采样还对模型造成了什么样的影响呢?采样会减少样本数量,而从学习曲线来看样本数量越少模型的过拟合会越严重,因为对模型来说,数据量越少模型学习越容易,学到的规则也会越具体越不适用于测试样本。所以subsample参数通常是在样本量本身很大的时候来调整和使用。
import numpy as np subs = [] scores = [] for i in np.linspace(0.05,1,20): xgb = XGBR(n_estimators=182,subsample=i).fit(Xtrain,Ytrain) score = xgb.score(Xtest,Ytest) subs.append(i) scores.append(score) plt.plot(subs,scores)
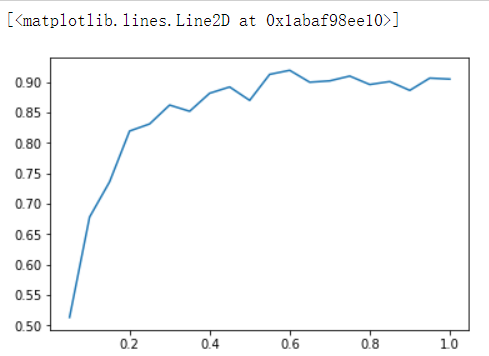
迭代的速率:learning_rate
- 从数据的角度而言,我们让模型更加倾向于努力攻克那些难以判断的样本。但是,并不是说只要我新建了一棵倾向于困难样本的决策树,它就能够帮我把困难样本判断正确了。困难样本被加重权重是因为前面的树没能把它判断正确,所以对于下一棵树来说,它要判断的测试集的难度,是比之前的树所遇到的数据的难度都要高的,那要把这些样本都判断正确,会越来越难。如果新建的树在判断困难样本这件事上还没有前面的树做得好呢?如果我新建的树刚好是一棵特别糟糕的树呢?所以,除了保证模型逐渐倾向于困难样本的方向,我们还必须控制新弱分类器的生成,我们必须保证,每次新添加的树一定得是对这个新数据集预测效果最优的那一棵树。
- 思考:如何保证每次新添加的树一定让集成学习的效果提升呢?
- 现在我们希望求解集成算法的最优结果,那我们可以:我们首先找到一个损失函数obj,这个损失函数应该可以通过带入我们的预测结果y来衡量我们的梯度提升树在样本的预测效果。然后,我们利用梯度下降来迭代我们的集成算法。
- 在模型中,使用参数learning_rate来表示迭代的速率。learning_rate值越大表示迭代速度越快,算法的极限会很快被达到,有可能无法收敛到真正最佳的损失值。learning_rate越小就越有可能找到更加精确的最佳值,但是迭代速度会变慢,耗费更多的运算空间和成本。
rates = [] scores = [] for i in np.linspace(0.05,1,20): xgb = XGBR(n_estimators=182,subsample=0.9,learning_rate=i).fit(Xtrain,Ytrain) score = xgb.score(Xtest,Ytest) rates.append(i) scores.append(score) plt.plot(rates,scores)
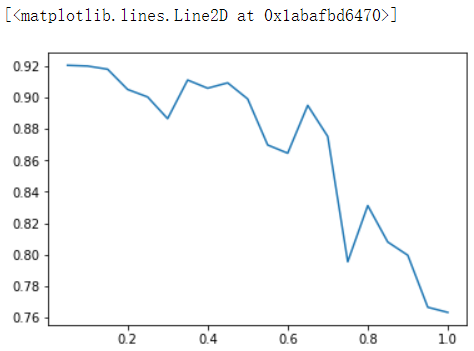
选择弱评估器:booster
- 梯度提升算法中不只有梯度提升树,XGB作为梯度提升算法的进化,自然也不只有树模型一种弱评估器。在XGB中, 除了树模型,我们还可以选用线性模型,比如线性回归,来进行集成。虽然主流的XGB依然是树模型,但我们也可以 使用其他的模型。基于XGB的这种性质,我们有参数“booster"来控制我们究竟使用怎样的弱评估器。

for booster in ["gbtree","gblinear","dart"]: reg = XGBR(n_estimators=180 ,learning_rate=0.1 ,random_state=420 ,booster=booster).fit(Xtrain,Ytrain) print(booster) print(reg.score(Xtest,Ytest)) #自己找线性数据试试看"gblinear"的效果吧~ [16:48:34] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror. gbtree 0.9231068620728082 [16:48:34] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror. gblinear 0.6286510307485139 [16:48:34] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror. dart 0.923106843149575
总结
到目前我们已经学习13个模型
KNN 线性回归 多项式回归 岭回归 高斯 多项式 伯努利 逻辑回归 Kmeans SVM 决策树 随机森林 XGBOOSt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号