


文献阅读Fault diagnosis of rolling bearing using symmetrized dot pattern and density-based clustering
2021-11-10 15:37 WGH123456 阅读(651) 评论(0) 收藏 举报摘要:
滚动轴承通常在复杂的工作条件下工作,这使得它更容易发生机械故障。振动信号通常是复杂的、非线性的、非平稳的。提出了一种新的滚动轴承诊断方法,该方法结合自适应对称点阵和基于密度的带噪声应用空间聚类(ASDP-DBSCAN)。首先简要介绍了SDP技术,然后利用SDP模式重构振动信号。其次,为了最大限度地提高SDP模式之间的差异,结合Hill函数和遗传算法(HFGA),提出了一种新的SDP模式参数优化方法,有利于提高诊断准确率。然后,利用改进的DBSCAN生成聚类模板,以降低噪声对诊断准确性的影响。此外,利用聚类模板与未知SDP模式之间的相似性分析进行故障分类。最后,将该方法应用于滚动轴承故障诊断。实验结果表明,该方法在滚动轴承故障诊断中比其他方法更有效。
背景/问题:
略,轴承诊断问题的背景都大同小异。
解决办法(创新点):
简单解释SDP:对称点模式分析作为一种新的信号表示方法,能够充分描述信号的特征,并以可视化图形的形式表达出来。SDP适用于将输入信号的细微差异变得明显来分析[15]。当所需信号的幅值低于背景噪声[16]时,该技术比其他技术更有效。这项技术最初被设计用来直观地描述语音波形。已经有很多人把SDP方法应用于故障诊断领域,但是传统的SDP参数选择依赖经验和知识。根据DeRosier[23] 的分析说明合理的使用参数能够使得SDP的效果更好
(1)提出了自适应的SDP--ASDP。通过使用改进的遗传算法来更新SDP的参数
简单解释DBSCAN:传统故障诊断模型的训练需要大量的标记数据,但实际上轴承故障数据又很少。传统的K-nearest neighbor (KNN) 算法是和fuzzy c-means (FCM) 虽然已经有了较好的效果,但是由于机械通常在恶劣的工作环境下工作,难免会产生噪声,影响诊断效果。所以基于密度的带噪声应用空间聚类DBSCAN应运而生。DBSCAN已经广泛被用于去噪,之前多被用于检测方面,在故障诊断方面应用还比较少。
(2)利用改进的DBSCAN生成聚类模板。
在此基础上,提出了基于ASDP-DBSCAN的故障分类方法,并应用滚动轴承故障数据对该方法进行评价。
实现细节:
总体流程如下:
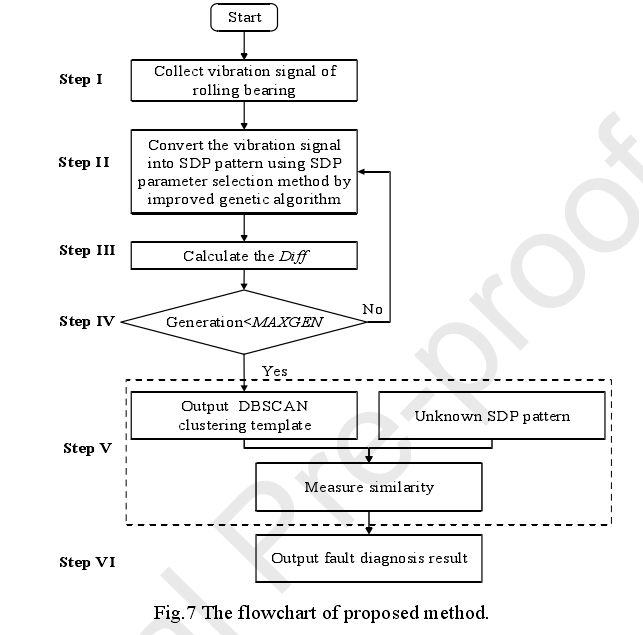
SDP:
首先给出绘图的公式:
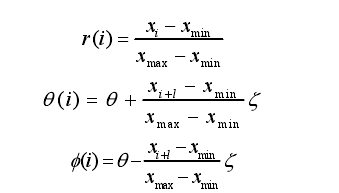
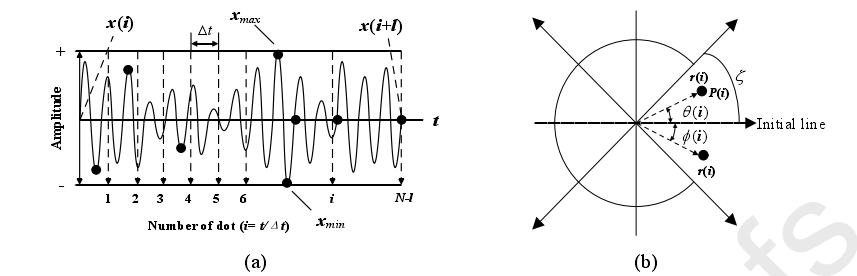
在时域波形中,第i个离散采样点xi的振幅和第i+l个采样点x(i+l)的振幅代入SDP公式中。其中r(i)为极坐标的半径,θ(i)为极坐标中逆时针旋转的角度,Φ(i)为极坐标中顺时针旋转的角度。
l为间隔参数,xmax为和xmin分别为[i,i+l]这个区间内振幅的最大值和最小值。假设在一个极坐标图里作n个这样的对称图形,那么θ=360m/n(m=1,2……n)θ为对称平面旋转角 ,ζ为放大因子。
频率间的差别在极坐标中表现为曲率与点分布位置的不同。在SDP中3个参数θ,ζ,l的选择非常重要,合理选取参数可以提高生成图形的分辨率,不易发生重叠。
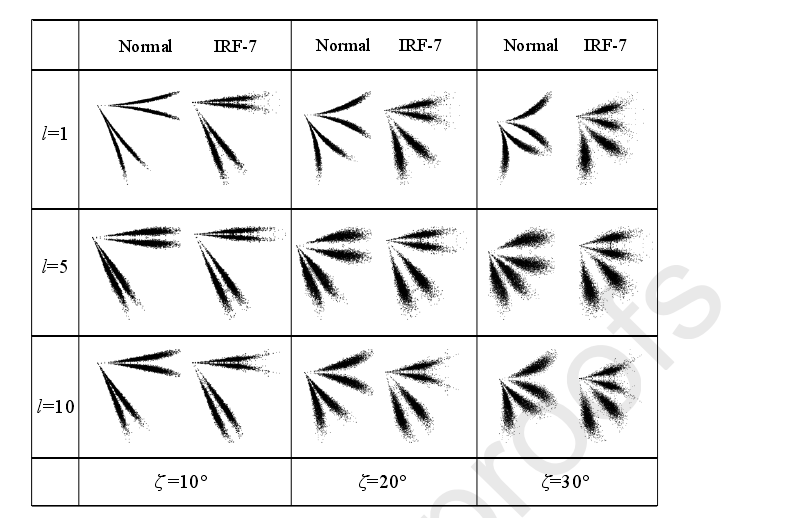
如上图所示,在参数l=5 zeta=10的时候,正常状态和RF-7状态非常相似,这不利于机器对他做出识别。因此本文提出了一种基于hill函数的遗传算法来自适应生成参数值。
首先,数字图像处理方法将SDP模式转换为数字矩阵。SDP模式的数字矩阵g可以表示为
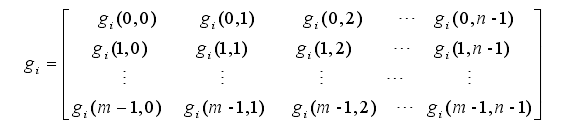
其中gi代表某种工况(例如Normal,IRF),矩阵中的每个数代表坐标轴上对应的灰度值。
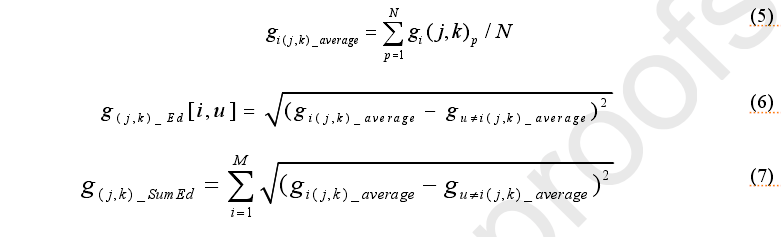
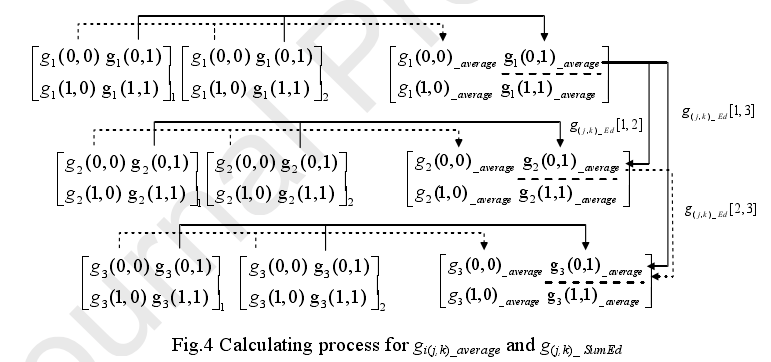
对于同一位置的一个操作状态,其中包含N个SDP模式,公式5定义了(j,k)处的平均灰度值为gi(j,k)_average,公式6定义了在坐标位置(j,k)在不同工况I和U的距离。公式7定义了在位置(J,K)上,所有工况距离的总和。通过公式可以得出,如果公式7的值越大,则SDP图像模式之间的差异越大,分辨率越高,越容易进行识别分类,提取特征等等。他的计算过程如下
基于以上分析,最后将SDP模式之间的差异定义为如下:
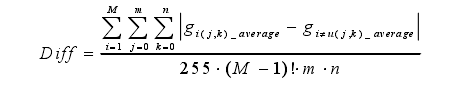
为了得到最大化的差异,必须经过在全局解空间的搜索得到最合适的l和ζ,Hill函数具有非负性和单调性[35](具体文献是 S. Ko, S. Gunasekaran, Analysis of cheese melt profile using inverse-Hill function, J. Food Eng. 87 (2008) 266–273)的特性,对于每一个特定的和可饱和的结合都是一个很好的近似值( saturable binding翻译怪怪的,不懂啥意思)。受Hill函数的启发,在Eq.(9)中提出了一个新的概率函数P(k)来调整解空间的范围,有利于避免早熟收敛
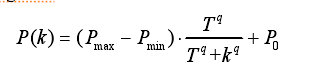
其中其中,最大概率Pmax,最小概率Pmin,初始概率P0在0到1之间。门槛系数T和Hill系数q在整个过程中都是常数。k等于当前代数,小于最大代数MAXGEN。
,由此可以重新定义一个遗传算法的定义交叉概率Pc(k)和变异概率Pm(k)
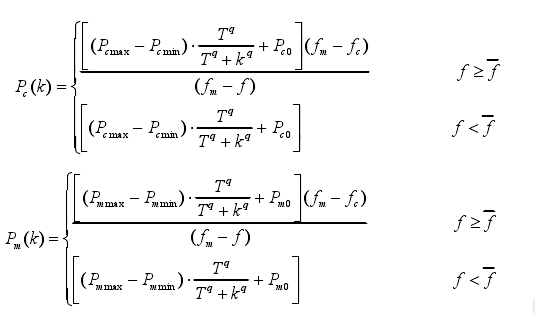
其中,fm为适应度最大值。Fc表示两个个体跨界时的较大适应度值。F是个体对变异的适应度值。Pcmax和Pmmax分别为交叉概率和变异概率的最大值。Pcmin和Pmmin分别为交叉概率和变异概率的最小值。Pm0和Pc0分别为突变概率和交叉概率的初值。
DBSCAN这个聚类介绍几个概念:
核心对象(core object),在给定的半径r内,对象个数大于minnum的对象称为 核心对象。
直接密度可达(Directly density-reachable),存在2个核心对象,其中一个在另一个的范围(半径r)内,则就是直接密度可达
密度可达(Density-reachable),存在一个长度为n对象序列,其中前n-1对象中,x(i+1)对xi是直接密度可达的,则x1到xn是密度可达。
密度相连(Density-connected),2个对象xi,xj,存在另一个对象xk,其中xk与xi是密度可达,xk与xj是密度可达,则xi与xj成为密度相连,可以理解为密度可达的传递性。
聚类中心(Clustering center),在一个聚类簇中,对其他所有核心对象距离最短的点。
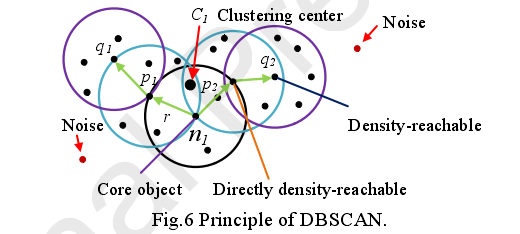
,参数r和Minnum对聚类结果起决定作用。然而,很难合理地选择它们。密度阈值Minnum决定了聚类过程中的核心对象,r决定了核心对象的搜索空间。特别是当r太小时,DBSCAN可能会将有用数据定义为噪声。相反,DBSCAN会将噪声数据分成一个聚类,这可能会产生很糟糕的聚类结果。针对这些问题,本文所提出的改进DBSCAN:
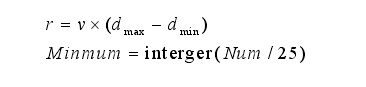
其中v为约简系数,取值范围为0 ~ 1。Dmax、dmin分别表示任意两个样本之间的最小、最大距离。Num是样本的总数。
生成DBSCAN聚类模板的方法如下(他的作用是:通过给定的故障训练样本,通过对同一点像素灰度值的聚类,得到每个故障一个SDP图像模板,然后未知的SDP图像(也就是测试样例)进行差异分析,如果差异小于一个阈值,就匹配)
将聚类簇的聚类中心作为DBSCAN聚类模板中对应坐标点的像素灰度的阈值。而聚类对象是一个工况下相同像素点的灰度值(同一个像素点的灰度值的个数=该工况下SDP图像的个数。在后面的实验中,每一个工况下样本有600个,也就有是有一种故障有600个SDP图像,然后对对这600个点进行聚类,得到一个“平均”的灰度值,从而排除噪音的干扰),对于一个操作状态i,聚类模板Ci的数字矩阵可以表示为
(这个CI(i,j)模板上的坐标只是灰度阈值,模板应该是由大于阈值的点组成的)
其中ci表示第i个工况的模板矩阵,Ci(0,0)表示在(0,0)坐标下的聚类中心,聚类对象包括gi(0,0)1,gi(0,0)2……gi(0,0)N,N是SDP图像的总数。
相关程度CC(correlation coefficient)定义如下

其中 CC值越大,测试样例和故障模板就越匹配。
在实验设置上,数据采集(由LabVIEW软件编写)通过两个PCB 608A11压电ICP加速度计在感应电机和轴承座上采集振动信号,如图8所示。采样频率设置为8200hz, 0.5s周期的振动信号长度为4100个点。此外,每个错误的实验将持续10分钟。在本研究中,每个测点(一个加速度计)包含4100个测点,因此每个故障有600个样本。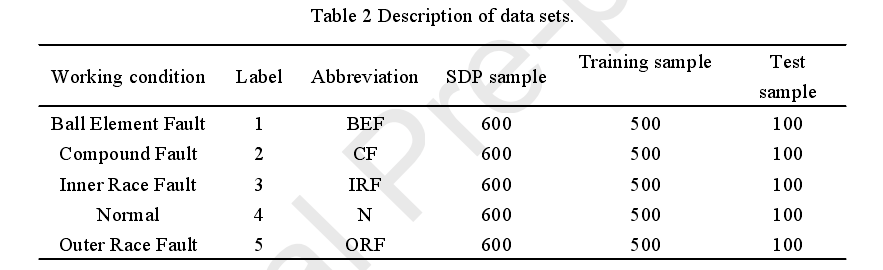
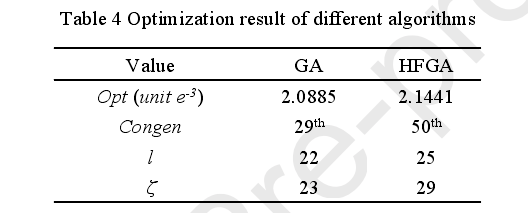
根据基于hill函数的遗传算法得到了SDP最优参数l和ζ如下
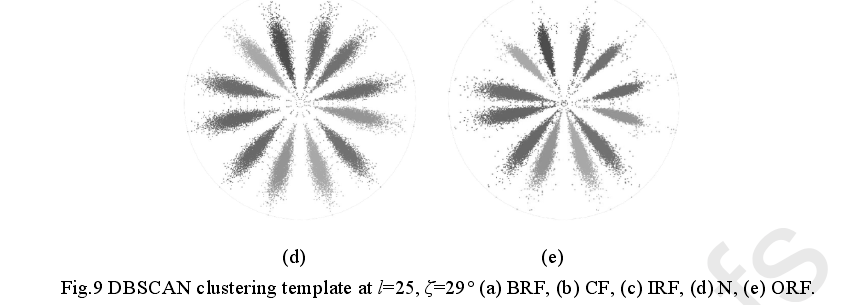
然后得到了SDP在各个工况下的图像聚类模板
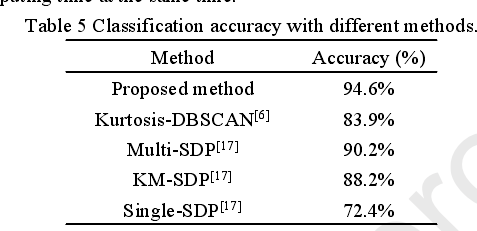
得到DBSCAN聚类模板后,计算未知SDP图像与聚类模板的相关系数,进行分类工作。为了进一步证明所提出的方法(ASDP-DBSCAN)的优点,我们进行了其他四种诊断方法,包括峭度- dbscan(时域提取峭度)[6]、单模板SDP (Single-SDP)[17]、多模板SDP (Multi-SDP)[17]、K-means聚类SDP (KM-SDP)[17]。表5显示了不同方法的分类准确率。该方法的精度高于其他方法。ASDP-DBSCAN(94.6%)和Kurtosis-DBSCAN(83.9%)的结果证明了基于sdp的方法在特征提取领域的有效性。这可能是由于两种不同工况的振动信号,其时域峰度可能相同,从而产生误分类。相反,这些振动信号被转换成SDP模式,它们在SDP模式中的特征可能完全不同。因此,基于sdp的方法对相同振动信号的分类结果更加正确
最后在不同噪音和不同训练样本占比的情况下也一一进行了比较,所提出的方法正确率都是高于其他方法的。这里就不一一列举了
总结:本文提出了一种基于自适应对称点阵模式分析和基于密度的聚类方法(ASDP-DBSCAN)的滚动轴承故障诊断方法。首先,利用SDP技术对滚动轴承运行状态的振动信号进行分析。通过对振动信号的对称点模式分析,可以将振动信号映射成可访问的可视化表示形式,为故障诊断奠定基础。然后,提出了自适应sdp参数选择方法。结合Hill函数,自适应更新交叉概率和变异概率。在此基础上,获得了SDP模式的最优参数,这对于减少人工经验和专业知识的依赖具有重要意义。进一步,采用改进的DBSCAN生成故障聚类模板,以降低噪声对诊断精度的影响。最后,通过实验验证了该方法的有效性。优化结果表明,HFGA算法在搜索结果和搜索效率方面都优于遗传算法。此外,通过与其他故障诊断方法的多次对比实验,证明了ASDP-DBSCAN方法的优越性和有效性。实验结果也表明,该方法比Kurtosis-DBSCAN、Multi-SDP、KM-SDP和Single-SDP具有更好的鲁棒性和有效性,证明了该方法能够获得更好的性能。
讨论与思考:
1.文中所提的“自适应的SDP参数选择方法”,其实是在给定的样本中,训练得到的最优参数。感觉有点像静态的自适应,因为给定样本和训练完,这个最优参数就不变了。如果参数要变,只能换一批训练状态再通过遗传算法得到新的最优解。。感觉不是动态的自适应。有点怪怪的
2.虽然我们采用了这种方法进行故障诊断,但聚类模板的生成是一项耗时的工作。对于未来的工作,开发一种减少计算时间的方法和设计更多的特征提取和诊断方法是非常有意义的。
3.在一篇最新的硕论中(山大),他引用了这篇文章,并评价 “但是该类方法大多是通过随机定义聚类中心,而后通过不断迭代寻优的结果”,这我就不是很懂了,聚类中心不是给出明确定义的吗,感觉不是随机的。 随机的应该是那些自适应方法初始参数的选择或者I其他参数吧?有待仔细再看一波
生词:
planetary行星的;empirical经验主义的;intrinsic固有的,内在的;ensemble全体;abbreviation缩写;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号