


Unicode字符集的由来
Unicode字符集的由来
本文起源于行走在阳光下的那些不可见字符中的知识边界,因为涉及到字符相关,而我也不能很清楚的描述Unicode的前世今生,故而有了此文。

计算机技术的革命极大地方便了人们的工作与生活,使得人类生活前进了一大步,可是在计算机发展进程中,世界各地由于语言文字不一,有过那么一段混乱难受的日子...
字符世界的起源
由于计算机在美国诞生,因此字符集最初也只考虑了美国人当时的需求,诞生了大家熟知的ASCII(American Standard Code for Information Interchange),它由26个基本拉丁字母、阿拉伯数字、英式标点符号和一些控制字符组成。
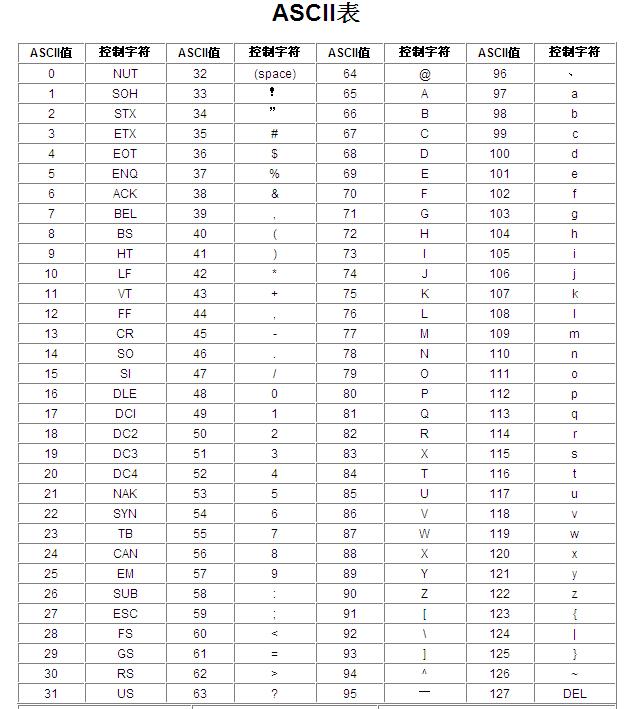
随着世界的发展,各国人民也开始接触计算机,然而各国人民也有自己独特的文化需求,最开始的字符集满足不了人们日益增长的需求,各国出现了不同的字符集标准,比如国内早期的Java程序员熟知的GBK、GB18030等,我曾经实习的时候接触的用JSP的老系统里就有相关的编码设定,如果用错误编码设定了文档解析格式,可能就会看到乱码,再想想世界上那么多个国家,会有多少编码标准啊,这也是互联网早期乱码比较多的原因吧。
各种编码的字符互不兼容,相互之间的通信可能由于编码的不同,而导致对方看到的是乱码,这就如中国历史中的大秦统一文字和度量单位之前的华夏文明一样,语言不通、货币不通,交流困难。时间的车轮滚滚向前,推动着历史的发展,于是Unicode(Universal Coded Character Set)出现了,它对世界上大部分的文字系统进行了整理、编码,使得计算机能够以更简单的方式来呈现和处理字符,它的目的就是为所有的字符提供统一的编码,任何的平台、系统、设备、应用或者语言都能兼容且无风险使用。
至今Unicode仍在不断的增修,当前最新版本为2019年5月公布的12.1,包含137994个字符,不仅包括当今世界上150种语言模型和历史性的手写码和符号,还包括多种符号集与表情符号。
Unicode
九层之台,起于累土。这样世界性的标准绝不是一蹴而就,必有其坚实的基础,设计原则就是Unicode的一大基础,在《The Unicode Standard Version 6.2 - Core Specification》有提到Unicode的设计原则,

我们熟知的UTF-8其实是Unicode的一种实现方式,即Unicode 转换格式(Unicode Transform Format),是一种为了减少传输数据的大小而设计的变长编码,每个字符使用1/2/3字节按照一定算法进行转换识别。此外,Unicode的实现方式还包括UTF-7、UTF-16、UTF-32、punycode、GB18030等。
总的来说,Unicode于乱世出生逐渐成为标准统一字符世界,至今仍持续发展,造福了社会,极大的提升了生产效率,虽未与ASCII并列与IEEE里程碑,但也是计算机科学史中一件举足轻重的大事记。
本次探索到此结束,全文本着追溯Unicode是什么为什么产生等问题,进行了一系列追寻,大致理清了Unicode的一些“前世今生”,基本对Unicode能够有个大概的认知,需要更加深入的探索的小伙伴可以留言一起探讨~
ps: 及时总结,静心沉淀;如风少年,砥砺前行。
冬至快乐~
如想了解更多,请移步我的博客
欢迎关注我的公众号 “和F君一起xx”
reference:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号