
MySQL
横为行,竖为列
MySQL编写顺序
select 列名 from 表名 where 条件 group by 分组 having 过滤条件
order by 排序列 limit 起始行,总条数;
MySQL 语句执行顺序
form-->where-->group by-->having-->select-->order by-->limit
(1)from指定数据来源
(2)where对查询数据第一次过滤
(3)group by 分组
(4)having 第二次过滤
(5)select 查询的各个字段的值
(6)oder by 排序
(7)limit 限定查询的结果
show databases; #显示所有数据库
create database 库名; #创建数据库
use 库名; #使用数据库
create table 表名; #创建表
drop table 表名; #删除表
show tables; #查看所有表
show create table 表名;#查看单个表的引擎和编码
rename table 原表名 to 新表名;给表添加字段:#重命名表
(1)在最后添加:alter tbale 表名 add 字段 类型;
(2)在最前添加:alter table 表名 add 字段 类型 first;
(3)在某个字段后面添加:alter table 表名 add 新字段 类型 after 目标字段;
3.给表添加字段:
(1)在最后添加:alter tbale 表名 add 字段 类型;
(2)在最前添加:alter table 表名 add 字段 类型 first;
(3)在某个字段后面添加:alter table 表名 add 新字段 类型 after 目标字段;
alter table 表名 engine=myisam/innodb charset=utf-8; #修改表的属性
alter table 表名 change 原字段 新字段 类型; #修改表的字段的名称和类型
alter tbale 表名 drop 字段名; #删除字段
小结:
4.运算符
(1)算数运算符:加减乘除+ - x / 注意:%不是运算符,是占位符
(2)逻辑运算符:and or not 注意:and用在不同的字段,相同的字段不可以使用,,而且一
但相同的字段使用了and,那么系统可能不会报错,也查询不到数据
(3)不等值判断:> < >= <= !=和<>都是不等于 没区别
5.null空值判断 一般搭配where使用
is null
is not null
select first_name,commission_pct
from t_employees
where commission_pct is null; /is not null;
6.枚举in
in(值1,值2,值3.....)意思就是在括号内的数据内选择搭配where使用
使用枚举查询 效率低,建议少用,可通过多条拼接查询
7.下标:在mysql中字符串下标从1开始 ,但是需要注意limit是从0开始
java字符串的下标是从0开始,但是在mysql中,字符串下标是从1开始!!!
语法:insert('str',pos,len,'newstr')字符串,位置,长度,新的字符串
insert('str',pos,len,'newstr')字符串,位置,长度,新的字符串
(1)insert('str',pos,len,'newstr')字符串,位置,长度,新的字符串
str 要插入字符的字段,pos从第几个位置后开始插入len插入的长度为多少 newsrt要插入的文字
例:select insert('这是第一个数据库',3,2,'mysql') ;insert:插入修改
结果:这是mysql数据库
这是一个数据库对应下标1234567
3,2释义为从第三个下标开始选择 为一,要修改的字符串为2个 即为个,后面接修改的数据
(2)限定/分页查询 limit下标是从0开始的
比如12345 对应的下标是01234
8.字符串截取substring
substring(str.num.len) 将str字符串指定num位置开始截取len个长度
SELECT SUBSTRING('今天天气真好啊',1,2);#从下标为1的位置开始,往后2位置截取 输出:今天
9.模糊查询 结合where使用
like '张%' 无限长度 张三,张三三,张三三三
like '张_ _ '
select first_name,employee from t_employees where first_name like 's%'; /like 's _ _';
10.分支结构
case
when 条件1 then '结果1'
when 条件2 then '结果2'
when 条件3 then '结果3'
else '结果4'
end as '表名'; #不带as去命名的话会把搜索语句直接显示在第一列上
SELECT employee_id,first_name,salary,
CASE
WHEN SALARY>=10000 THEN 'A'
WHEN SALARY>=8000 AND SALARY<10000 THEN 'B'
WHEN salary>=6000 AND SALARY<8000 THEN 'C'
ELSE 'E'
END AS'薪资等级'
FROM t_employees;
11.时间函数
SELECT NOW();#当前年月日时分秒
SELECT SYSDATE();#当前年月日时分秒
SELECT CURDATE();#当前年月日
SELECT CURTIME();#d当前时分秒
SELECT WEEK('2021-4-6 14:58:59');#当前时间是今年的第几周
SELECT YEAR('2021-4-6 14:58:59');#当前时间内的年份
SELECT HOUR('2021-4-6 14:58:59');#当前时间内的小时
now()和curdate()区别 分别运行下面两条数据即可看清
sysdate()返回的是执行之后时间,now()返回的是执行时间,所以在使用的时候一般使用now(),
因为SYSDATE获取当时实时的时间,这有可能导致主库和从库是执行的返回值是不一样的,从而导致数据不一致
SELECT SYSDATE(),SLEEP(3),SYSDATE();
SELECT NOW(),SLEEP(3),NO W();
12.字符串拼接concat
select concat('a','b','c');输出abc
select concat(first_name,last_name) form t_employees;直接输入列名则不需要单引号即可输出合并两列
13.字符串转大小写
lower(str)转小写 upper(str)转大写
select lower('MYSQL'); #转小写
select upper('mysql');#转大写
14.聚合函数 作用是对多条数据的单列进行统计操作,返回统计后的一行结果
语法:select 聚合函数(列名) from 表名;
SUM()求所有行中单列结果的总和
MAX()最大值
MIN()最小值
AVG()平均值
COUNT()总行数
15.select version;#查看当前MySQL版本
16.去重复 distinct
select destinct id from t1;
17.升序和降序
语法:select 字段1 from 表名 order by asc/desc;
ASC(从小到大)和DESC(从大到小) 前面都需要加oder by,多个条件以逗号隔开
18.与java不同java中== 是等于号 mysql中判断等值是=
19.分组查询
(1)
select 列名 from 表名 where 条件 group by 分组根据的列名;
理解为根据哪个列名进行分组查询
注意:如果有where,那么group by必须在where之后
查询各部门,各岗位的总人数(理解:部门对应各岗位有多少人)
select department_id,job_id,count(department_id)
from employees
group by department_id,job_id;
部门下还有各个岗位,比如运营部有销售,客服等属于不同的岗位所以需要加job_id进行分组
一行对应一个人,所以使用count
null是因为岗位job_id存在所以显示了null
(2)分组查询常见问题
语句是正常的,但是不可以这样写!
select department_id,job_id,count(*),first_name
from employees
group by department_id,job_id;
这样写会导致first_name字段只显示其中一条数据,不会显示完整的数据的,所以不能这样写!
总结: 在分组查询中,只能显示分组查询的列和显示聚合函数,不能显示其他列
在分组查询中,只能显示分组查询的数据和聚合函数,不显示其他列(或者显示的只是一部分,不完整的)
(3)分组查询过滤规则
select 列名from 表名 where 条件 group by 分组依据 having 过滤规则
统计80,90,100部门的最高工资
select department_id max(salary)
from t_employees
group by department_id
having departing_id in(80,90,100);
建议把枚举一个一个拼接写 department_id=80 or department_id=90 or deparment_id=100
为什么不能使用and 而使用or 因为and不能用于相同的字段
20.列的别名
AS 语法: 列 AS 列名; select first_name as "姓名" from t1;
21.引号
单引号和双引号都可以对空格进行操作,如不加引号则无法识别空格,会报错(暂时没有其他区别)
21.子查询
(1)一行一列
select 列名 from 表名 where (子查询结果)
查询薪资大于Bruce的员工信息(一行一列查询)
拆分
(1)先查询出Bruce的信息 得出Bruce的薪资为6000
SELECT salary
FROM t_employees
WHERE first_name='Bruce';
(2)查询大于6000薪资的员工信息 这条信息其实是为了好对比查询出的数据共55条
SELECT * FROM t_employees
WHERE salary>6000 ORDER BY salary DESC;
(3)整合 600不能手写的 需要用SQL语句 注意:导入的表格这里存在问题正常情况下是显示55条数据的,语法没有问题!
SELECT * FROM t_employees
WHERE salary>(
SELECT salary
FROM t_employees
WHERE first_name='Bruce') ORDER BY salary DESC;
(2)多行单列 作为枚举查询
select 列名 from 表名 where 列名 in(子查询结果)
当子查询结果集形式为多行单列时,可以使用any或者all关键字
any只需要满足其中一个条件即可显示,all所有条件必须同时满足
注意:多行单列的时候必须使用any或all不然系统会报错
select salary from t_employees where department_id=60)
上述语句可以得出部门编号为60的薪资有9000,6000,4800和4200数据
select * from t_employees
where salary>any(select salary from t_employees where department_id=60);
只要满足大于9000,6000,4800和4200其中任何一个值即可显示数据
反之 要大于最大值才可以显示数据
select * from t_employees
where salary>all(select salary from t_employees where department_id=60);
(3)多行多列 查询结果作为一张表
select 列名 from (子查询结果集) where 条件;
一般的方法是将问题进行拆分,再将多条语句合并
注意:将子查询的结果作为外部查询的一张表,做第二查询,
需要注意的是子查询结果左外临时表的时候,必须为其赋予一个临时的表名,否则系统会报错!
22.表连接查询 https://blog.csdn.net/plg17/article/details/78758593 CSDN有详细介绍
如果区分左右表:写在语句inner join/left join/right join左边的即为左表,写在inner join/left join/right join右边的为右表 例:
select * from a_table a inner join b_table b on a.a_id = b.b_id;

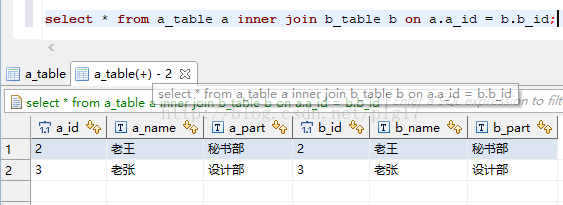
(1)内连接查询 inner join on 查询的是两表内交集的部分
inner join on 两个有相同列的表,比如表1内有部门这个字段,表二内也有一样的部门字段,
那么可以跟据这个列来进行内连接查询
注意:多表连接查询时候不需要符合隔开,写完一句直接在后面添加语句即可
语句:select * from a_table a inner join b_table b on a.a_id = b.b_id;
执行结果:
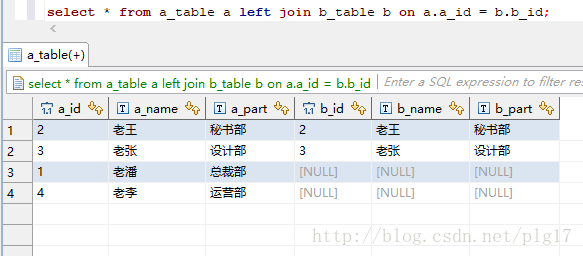
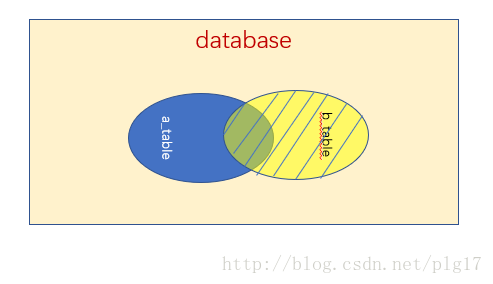
(2)左外连接查询 left join on
left join on 以语句左边的表格为中心,左表全部显示,右表显示交集部分,没有数据的位置以null填充
语句:select * from a_table a left join b_table b on a.a_id = b.b_id;
执行结果:
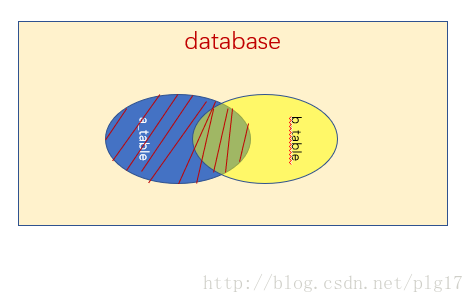
(3)右外连接查询right join on
right join on 以语句右边的表格为中心,右表全部显示,左表显示交集部分,没有数据的位置显示null
语句:select * from a_table a right outer join b_table b on a.a_id = b.b_id;
执行结果:
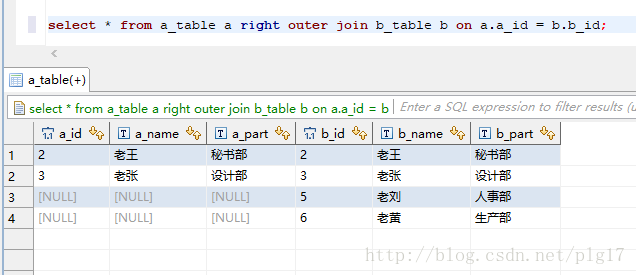
23.库名下可以的数据库名称可以这样使用
比如库db1下有表t1 可以select * from db1.t1; 这样写在使用sql工具的时候可以在点到其他的数据库
的时候,也可以正常执行sql语句
24.表的别名 分别给对应的表格取了一个别名 方便使用
三表连接查询
SELECT * FROM t_employees e
INNER JOIN t_departments d
ON e.employee_id=d.department_id
INNER JOIN t_locations l
ON l.location_id=l.location_id;
和上述写法是一样的 只是分别给对应的表格取了一个别名 方便使用
25.笛卡尔积
多表查询会出现笛卡尔积的情况,例如集合A={a,b} B={0,1,2},在没有连接条件的情况下查询
select * from a,b;
则两个集合的笛卡尔积为:
{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}
简单的说就是容易导致查询结果重复,混乱 所以需要条件来筛选结果
消除笛卡尔积最直接的方法使用:等值连接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号