Solr reRankQuery加自定义函数实现搜索二次排序
原来的账号提示我密码太简单,需要重置,重置需要邮箱,但是我想不起当年注册的邮箱是啥了,重新注册一个,把内容搬过来。
最近用到solr排序的复杂排序,系统最开始的排序时重写了文本相关分计算部分,增加新的排序逻辑后性能下降十分明显,考虑到用reRank和自定义函数的方法来解决,实际操作中碰到一些问题,自定义函数参考了http://blog.sina.com.cn/s/blog_65ae97720102vujw.html
然后再rerank测试通过,确实只会对头部指定的docs进行重新计算分数。
首先创建一个maven项目,pom依赖项如下,solr core使用6.6版本
<dependencies>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>6.6.0</version>
<exclusions>
<exclusion>
<groupId>org.restlet.jee</groupId>
<artifactId>org.restlet.ext.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.restlet.jee</groupId>
<artifactId>org.restlet</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.6.0</version>
</dependency>
</dependencies>
项目中增加自己的package,增加两个类文件,分别实现 ValueSourceParser和ValueSource
项目文件结构如下图
首先是继承ValueSourceParser的MyValueSourceParser 类,重写parse方法,return MyScoreSource类的实例。
MyValueSourceParser 类代码如下:
package com.wmf.customfunc;
/**
* Created by wangmf on 2019/7/19.
*/
import org.apache.lucene.queries.function.ValueSource;
import org.apache.solr.schema.SchemaField;
import org.apache.solr.search.FunctionQParser;
import org.apache.solr.search.SyntaxError;
import org.apache.solr.search.ValueSourceParser;
//需要继承ValueSourceParser,重写parse方法
public class MyValueSourceParser extends ValueSourceParser {
public MyValueSourceParser() {
super();
}
@Override
public ValueSource parse(FunctionQParser fp) throws SyntaxError {
// String sortType = fp.parseArg(); //这里是从FunctionQParser取到第一个参数,也就是我们自定义函数里的第一个参数 sortType
// String latitudeStr = fp.parseArg();//第二个参数latitude
// String longitudeStr = fp.parseArg();//第三个参数longitude
//本例没用到参数 //获取三个字段的信息
ValueSource intval1 = getValueSource(fp,"intval1");
ValueSource intval2 = getValueSource(fp,"intval2");
ValueSource floatval1 = getValueSource(fp,"floatval1");
//将参数及需要的文档的值传给自定义的ValueSource方法,打分规则在自定义的ValueSource中定制
MyScoreSource stringFieldSource = new MyScoreSource(intval1,intval2,floatval1);
return stringFieldSource;
}
//该方法是根据字段名,从FunctionQParser得到文档该字段的相关信息
public ValueSource getValueSource(FunctionQParser fp, String arg) {
if (arg == null)
return null;
SchemaField f = fp.getReq().getSchema().getField(arg);
return f.getType().getValueSource(f, fp);
}
}
MyScoreSource类实现评分计算,代码如下
package com.wmf.customfunc;
import java.io.IOException;
import java.util.Map;
import org.apache.lucene.index.LeafReaderContext;
import org.apache.lucene.queries.function.FunctionValues;
import org.apache.lucene.queries.function.ValueSource;
import org.apache.lucene.queries.function.docvalues.FloatDocValues;
/**
* Created by wangmf on 2019/7/19.
*/
public class MyScoreSource extends ValueSource {//需要继承ValueSource ,重写getValues方法
private ValueSource intval1;
private ValueSource intval2;
private ValueSource floatval1;
//通过构造方法的参数传递取得filed中的值
public MyScoreSource(ValueSource intVal1, ValueSource intVal2, ValueSource floatVal1) {
this.intval1 = intVal1;
this.intval2 = intVal2;
this.floatval1 = floatVal1;
}
@Override
public FunctionValues getValues(Map context,
LeafReaderContext readerContext) throws IOException {
final FunctionValues IntValue1 = intval1.getValues(context,readerContext);
final FunctionValues IntValue2 = intval2.getValues(context,readerContext);
final FunctionValues FloatValue1 = floatval1.getValues(context,readerContext);
return new FloatDocValues(this) {
//重写floatVal方法,此处为打分排序规则
@Override
public float floatVal(int doc) {
String strInt1 = IntValue1.strVal(doc);
String strInt2 = IntValue2.strVal(doc);
String strFloat1 = FloatValue1.strVal(doc);
float sc1 = Float.parseFloat(strInt1);
float sc2 = Float.parseFloat(strInt2);
float sc3 = Float.parseFloat(strFloat1);
System.out.println("Int1:" + strInt1 + "," + "Int2:" + strInt2 + "," + "Float1:" + strFloat1);
return sc1 + sc2 + sc3; //返回自己计算出的得分值
}
@Override
public String toString(int doc) {
return name() + '(' + IntValue1.strVal(doc) + ',' + IntValue2.strVal(doc) + ',' + FloatValue1.strVal(doc) + ')';
}
};
}
@Override
public boolean equals(Object o) {
return true;
}
@Override
public int hashCode() {
return 0;
}
@Override
public String description() {
return name();
}
public String name() {
return "Myfunction";
}
}
测试用的逻辑,实际很简单,将三个字段:intval1,intval2,floatval1的值相加作为新的分数,实际业务中逻辑会更复杂,但逻辑都可以在实例new FloatDocValues(this)写,根据不同的返回,重写floatVal方法,或者用其他继承了FloatDocValues类或者DoubleDocValues、StrDocValues等类实现逻辑。
代码完成后打包,将生成的包复制到solr中,如果是在使用solr自带的jetty作为web容器,则将打好的jar包复制到 server/solr-webapp/webapp/WEB-INF/lib/目录下,然后修改对应对应core的solrconfig.xml
修改内容如下:
<valueSourceParser name="myfunc" class="com.wmf.customfunc.MyValueSourceParser" />
name就是我们再调用时需要使用的函数名,通常我们在查询时想要得到函数计算值,可以直接在fl中增加该函数
http://solrserver/solr/core_demo/select?fl=*,_val_:myfunc()&indent=on&q=*:*&wt=json
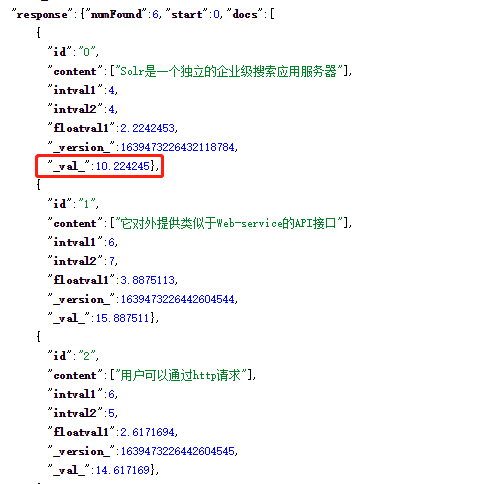
得到结果如下
结合solr的reRankQuery可以实现在文本相关的头部docs中进行排序,注意,在rerank查询时{}中的内容大小写敏感
http://solrserver/solr/core_demo/select?q=*:*&wt=json&sort=intval1 desc&rq={!rerank reRankQuery=$rqq reRankDocs=2 reRankWeight=1.0}&rqq={!func}myfunc()&
fl=*,score,_val_:myfunc()&indent=on
该查询实现:查询所有文档,并按照intval1字段进行倒序排序,再在前面的两个doc,按照我们自定义的函数myfunc计算的分数,重新进行年排序,返回结果如下图

这里的逻辑是在reRankQuery中计算的分数按照reRankWeight的权重和第一次查询的score相加后计算新的分数,计算式只针对reRankDocs的指定的头部数量的doc进行,得到新的分数score。从上图可以看到前面两个doc的score是函数计算的分数*1(权重是1.0)+1(原有的分数)。从第三条开始score只有第一次查询的1.0。从而在进行第二次查询是实现自定义的逻辑。
另外如果要按照计算的分数排序,使用sort={!func}myfunc() desc,进行过滤,应该使用solr的frange命令{!frange l=13}myfunc() 过滤小于13分的doc。
注:除了在reRank中使用外,其他查询、排序、过滤都会在召回的所有doc中进行计算操作,可能对性能影响比较大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号