6.1 集合和映射--集合Set->底层基于二叉搜索树实现
前言:在第5章的系列学习中,已经实现了关于二叉搜索树的相关操作,详情查看第5章即可。在本节中着重学习使用底层是我们已经封装好的二叉搜索树相关操作来实现一个基本的集合(set)这种数据结构。
集合set的特性:
集合Set存储的元素是无序的、不可重复的。为了能达到这种特性就需要寻找可以作为支撑的底层数据结构。
这里选用之前自己实现的二叉搜索树,这是由于该二叉树是不能盛放重复元素的。因此我们可以使用二叉搜索树这种底层来实现集合(set)。
1、集合set相关功能

1.1 add()方法特性
二分搜索树的添加操作add:不能盛放重复元素
2. set应用
典型应用:1.客户统计 2.词汇量统计
3.集合实现
3.1 Set接口定义
/** * 集合的接口 */ public interface Set<E> { void add(E e);//添加 <——<不能添加重复元素 void remove(E e);//移除 int getSize();//获取大小 boolean isEmpty();//是否为空 boolean contains(E e);//是否包含元素 }
3.2 基于二分搜索树实现集合Set
//基于BST二分搜索树实现的集合Set public class BSTSet<E extends Comparable<E>> implements Set<E> {//元素E必须满足可比较的 //基于BST类的对象 private BST<E> bst; //构造函数 public BSTSet() { bst = new BST<>(); } //返回集合大小 @Override public int getSize() { return bst.size(); } //返回集合是否为空 @Override public boolean isEmpty() { return bst.isEmpty(); } //Set添加元素 @Override public void add(E e) { bst.add(e); } //是否包含元素 @Override public boolean contains(E e) { return bst.contains(e); } //移除元素 @Override public void remove(E e) { bst.remove(e); } }
3.3测试:两本名著的词汇量 和不重复的词汇量
public static void main(String[] args) { System.out.println("Pride and Prejudice"); //新建一个ArrayList存放单词 ArrayList<String> words1=new ArrayList<>(); //通过这个方法将书中所以单词存入word1中 FileOperation.readFile("pride-and-prejudice.txt",words1); System.out.println("Total words : "+words1.size()); BSTSet<String> set1=new BSTSet<>(); //增强for循环,定一个字符串word去遍历words //底层的话会把ArrayList words1中的值一个一个的赋值给word for(String word:words1) set1.add(word);//不添加重复元素 System.out.println("Total different words : "+set1.getSize()); System.out.println("-------------------"); System.out.println("Pride and Prejudice"); //新建一个ArrayList存放单词 ArrayList<String> words2=new ArrayList<>(); //通过这个方法将书中所以单词存入word1中 FileOperation.readFile("a-tale-of-two-cities.txt",words2); System.out.println("Total words : "+words2.size()); BSTSet<String> set2=new BSTSet<>(); //增强for循环,定一个字符串word去遍历words //底层的话会把ArrayList words1中的值一个一个的赋值给word for(String word:words2) set2.add(word);//不添加重复元素 System.out.println("Total different words : "+set2.getSize()); }
结果:
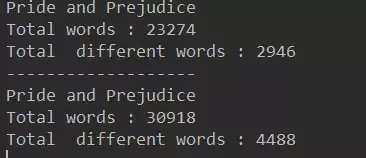
这里需要说明一下就是关于我们统计的单词数只考虑了每个单词组成的不用,并没有对单词的特殊形式做区分。
在下一小节中继续学习【集合和映射--集合Set->底层基于链表实现】。
源码地址 https://github.com/FelixBin/dataStructure/tree/master/src/SetPart
推荐是最好的支持,关注是最大的鼓励。亲爱的朋友,很荣幸在园子里遇到您。
As you wish.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号