ElasticSearch的搜索相关操作
1、基本介绍
Elasticsearch 的查询是基于 JSON 风格的 DSL (Domain Specific Language)来实现的。
常见的查询类型包括:
- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:match、multi_match
- 精确查询:根据精确词条值查找数据,一般查找不分词的字段,例如keyword、数值、日期、boolean等类型字段。例如:ids、range、term
- 地理(geo)查询:根据经纬度查询,经纬度不分词。例如:geo_distance、geo_bounding_box
- 复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:bool、function_score
下面查询以以下数据为例:
#POST / shopping / _doc / 1001
{
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
#POST / shopping / _doc / 1002
{
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
#POST / shopping / _doc / 1003
{
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
#POST / shopping / _doc / 1004
{
"name": "zhangsan1",
"nickname": "zhangsan",
"sex": "女",
"age": 50
}
#POST / shopping / _doc / 1005
{
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
2、查询所有文档数据(match_all)
查找所有文档内容,也可以这样,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON请求体,如下:
{
"query": {
"match_all": {}
}
}
# "query":这里的 query 代表一个查询对象,里面可以有不同的查询属性
# "match_all":查询类型,例如:match_all(代表查询所有), match,term , range 等等
# {查询条件}:查询条件会根据类型的不同,写法也有差异
响应结果:

结果说明如下:
{
"took【查询花费时间,单位毫秒】" : 1116,
"timed_out【是否超时】" : false,
"_shards【分片信息】" : {
"total【总数】" : 1,
"successful【成功】" : 1,
"skipped【忽略】" : 0,
"failed【失败】" : 0
},
"hits【搜索命中结果】" : {
"total"【搜索条件匹配的文档总数】: {
"value"【总命中计数的值】: 5,
"relation"【计数规则】: "eq" # eq 表示计数准确, gte 表示计数不准确
},
"max_score【匹配度分值】" : 1.0,
"hits【命中结果集合】" : [
。。。
}
]
}
}
3、精准查询
3.1、单关键字单值精准查询(term)
term 查询用于执行精确匹配,精确查询不会对查询条件进行分词,它会查找指定字段中与查询值完全匹配的文档。在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping/_search
{
"query": {
"term": {
"name": {
"value": "zhangsan"
}
}
}
}
查询结果:
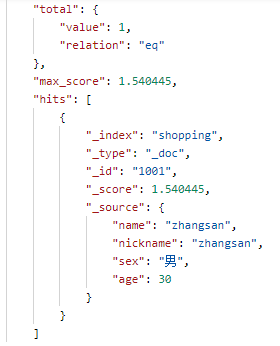
term 查询不会分词,如果此时查询条件是 "zhang" 或者 "san",此时就无法查出数据,因为没有 name 为 "zhang" 或 "san" 的数据。
(terms 只适合not anynized 即未做分词的数据,映射类型为 text(即会自动分词)的数据可能会被分词了,用精准查询反而可能查不出来。)
3.2、单关键字多值精准查询(terms)
terms 查询和 term 查询一样,但它允许你指定一个字段对多个关键字值进行匹配。如果该字段包含了多个关键字中的任何一个值,那么这个文档满足条件,类似于 mysql 的 in。
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping/_search,json 请求体如下:
{ "query": { "terms": { "name": ["zhangsan","lisi"] } }}
响应结果:
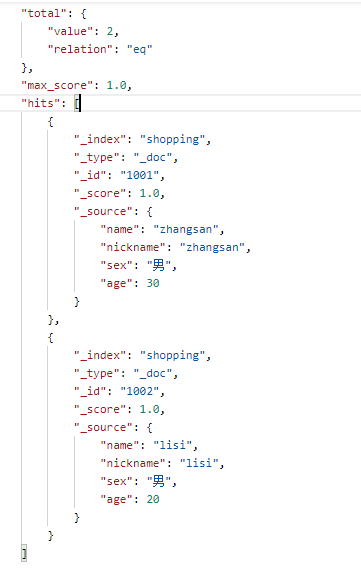
4、分词匹配查询(模糊查询)
4.1、单字段分词匹配(match)
match 匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系。
match查询属于高层查询,会根据你查询的字段的类型不一致,采用不同的查询方式。
- 如果查询的是日期或者数值的字段,他会自动将你的字符串查询内容转换成日期或者数值对待;
- 如果查询的内容是一个不能被分词的字段(keyword),match查询不会对你的指定查询关键字进行分词;
- 如果查询的内容是一个可以分词的字段(text),match会将你指定的查询内容根据一定的方式去分词,然后去分词库中匹配指定的内容。
总而言之:match查询,实际底层就是多个term查询,将多个term查询的结果汇集到一起返回给你。
向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping/_search,请求体为 json 格式,内容如下:
{
"query": {
"match": {
"name":"zhangsan"
}
}
}
响应结果如下:

4.2、多字段分词匹配查询(multi_match)
multi_match 与 match 类似,不同的是multi_match针对多个field进行检索,多个field对应一个查询的关键字。多字段匹配查询,实际上是 OR 的关系,即只要该文档中有一个字段匹配到了关键字,就能被查询出来。
向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping/_search,请求为 json 格式,内容如下:
{
"query": {
"multi_match": {
"query": "zhangsan",
"fields": ["name","nickname"]
}
}
}
响应结果如下:
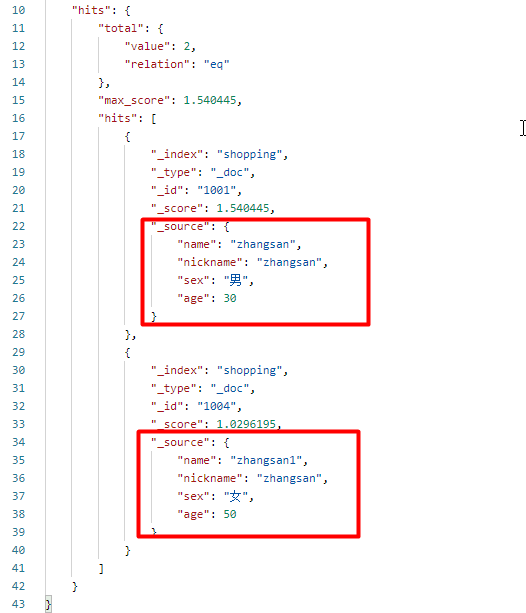
4.3、短语分词匹配查询(match_phrase)
match_phrase 查询是一种用于匹配短语的查询方式,它会将查询字符串分解成单词,然后按照顺序匹配文档中的单词,只有目标文档需要包含分词后的所有词,且目标文档中单词顺序与查询字符串中的单词顺序完全一致时才会匹配成功。
match_phrase 与match 都会进行分词,但不同的是,match查询只需要匹配查询中的一个或多个单词即可,而且不需要考虑单词的顺序。例如,如果查询是“quick brown fox”,match查询将匹配包含“quick”、“brown”或“fox”的文档,且不管它们的顺序如何。相比之下,match_phrase查询只会匹配包含完全短语“quick brown fox”的文档。
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match":{
"title" : "修改后"
}
}
}
响应结果:
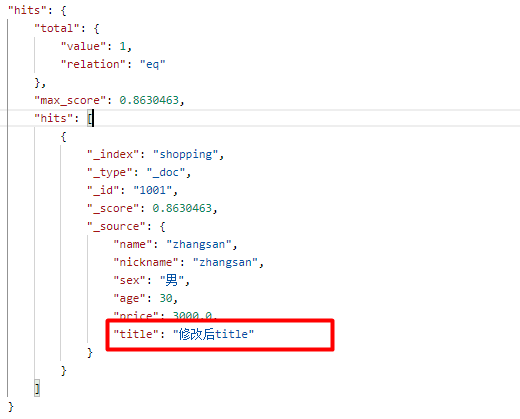
5、模糊查询
ES 支持多种模糊查询,包括Wildcard查询、Fuzzy查询、Regexp查询和Match查询(match 查询实际上也是一种模糊查询)。这些查询可以用于执行模糊匹配、拼写纠错、范围查询等操作。
5.1、Wildcard 查询(通配符)
Wildcard 查询是一种基于通配符的查询,它使用单个字符(?)代表一个字符,使用星号(*)代表零个或多个字符。Wildcard 查询可用于对单个词执行模糊匹配,也可以用于对短语进行模糊匹配。它可以在搜索中用于查找某些词汇的变体或拼写错误的单词。
例如,以下查询将匹配包含任何以“elasti”开头的文档:
GET /my_index/_search
{
"query": {
"wildcard": {
"title": "elasti*"
}
}
}
5.2、Fuzzy 查询(相似单词)
Fuzzy 查询是一种模糊查询,可以用于查询包含与搜索字词相似的字词的文档,它可以用于拼写纠错等操作。
Fuzzy 查询使用编辑距离算法计算文本之间的相似度,编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
- 更改字符(box → fox)
- 删除字符(black → lack)
- 插入字符(sic → sick)
- 转置两个相邻字符(act → cat)
为了找到相似的术语,fuzzy 在查询时会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展,然后再查询并返回每个扩展的完全匹配。
以下是一个使用 Fuzzy 查询的示例:
GET /my_index/_search
{
"query": {
"fuzzy": {
"title": {
"value": "elasticsearch",
"fuzziness": "AUTO"
}
}
}
}
在上面的示例中,查询将返回所有与 "elasticsearch" 相似的文档。Fuzziness 参数可以指定编辑距离的最大值,它可以是一个整数,一般可不指定即为 "AUTO" 值,表示 Elasticsearch 将自动根据术语的长度计算最佳的编辑距离值。
5.3、Regexp 查询
Regexp 查询是一种基于正则表达式的查询,它可以用于在文本中查找匹配指定正则表达式的单词或短语。Regexp 查询非常灵活,但由于它需要对所有文档进行扫描,因此可能会影响性能。
以下是一个使用 Regexp 查询的示例,在下面的示例中,查询将匹配所有以 "elasticsearch" 开头的单词或短语的文档。
GET /my_index/_search
{
"query": {
"regexp": {
"title": "elasticsearch.*"
}
}
}
6、多条件查询之must(相当于and)
`bool`把各种其它查询通过`must`(必须 )、`must_not`(必须不)、`should`(应该)的方式进行组合。
假设想找出小米牌子,且价格为3999元的。(must相当于数据库的and),在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"bool":{
"must":[{
"match":{
"category":"小米"
}
},{
"match":{
"price":3999.00
}
}]
}
}
}
7、多条件查询之should(相当于or)
假设想找出小米或华为的牌子。(should相当于数据库的||),在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"bool":{
"should":[{
"match":{
"category":"小米"
}
},{
"match":{
"category":"华为"
}
}]
},
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
8、范围查询(range)
range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符:

假设想找出小米或华为的牌子,且价格大于2000元的手机。在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"bool":{
"should":[{
"match":{
"category":"小米"
}
},{
"match":{
"category":"华为"
}
}],
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
}
9、分页查询(from、size)
向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_all":{}
},
"from": 2, //码数索引,从0开始。如2,即表示从第3条开始,查询size条
"size":2
}
10、查询排序(sort)
如果你想通过排序查出价格最高的手机,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_all":{}
},
"sort":{
"price":{
"order":"desc"
}
}
}
11、高亮查询(highlight)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_phrase":{
"category" : "为"
}
},
"highlight":{
"fields":{
"category":{}//<----高亮这字段
}
}
}
返回结果如下:
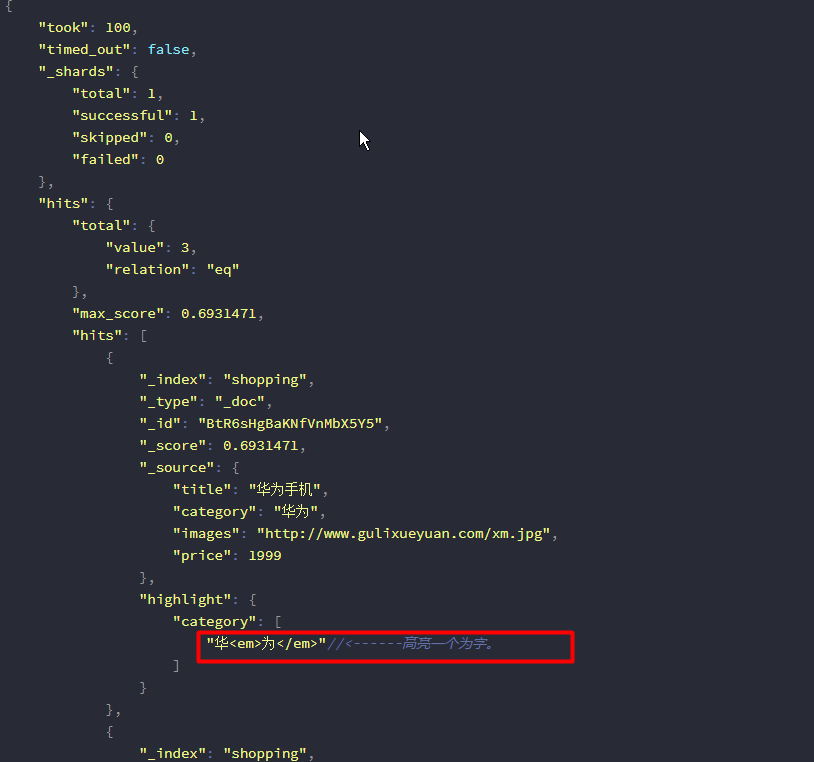
12、聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
12.1、取最大值(max)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "aggs": { "max_age": { "max": { "field": "age" } } }, "size": 0 }
返回结果如下:

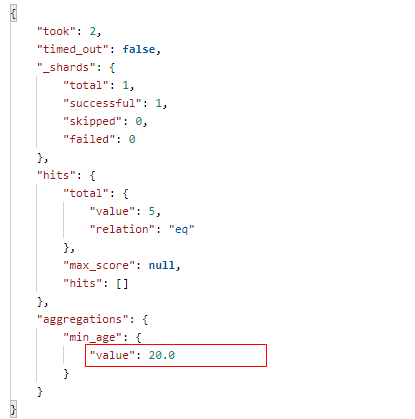
12.2、取最小值(min)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "aggs": { "min_age": { "min": { "field": "age" } } }, "size": 0 }
返回结果如下:
12.3、对字段值求和(min)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "aggs": { "sum_age": { "sum": { "field": "age" } } }, "size": 0 }
返回结果如下:

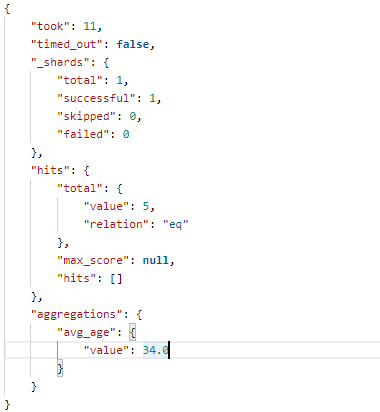
12.4、对字段值取平均值(avg)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "aggs": { "avg_age": { "avg": { "field": "age" } } }, "size": 0 }
返回结果如下:
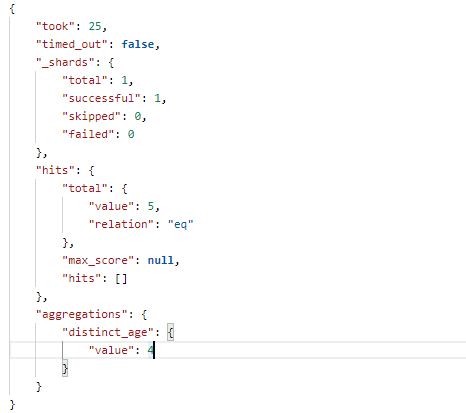
12.5、对字段去重后取数量(distinct)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "aggs": { "distinct_age": { "cardinality": { "field": "age" } } }, "size": 0 }
返回结果如下:
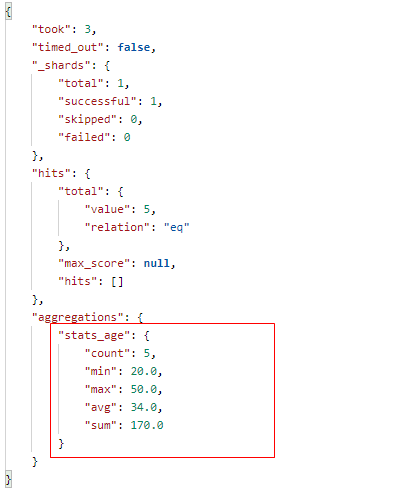
12.6、State 聚合(包含count,max,min,avg 和 sum)
State 聚合会一次性返回指定字段的count,max,min,avg 和 sum五个指标的数据。
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "aggs": { "stats_age": { "stats": { "field": "age" } } }, "size": 0 }
返回结果如下:
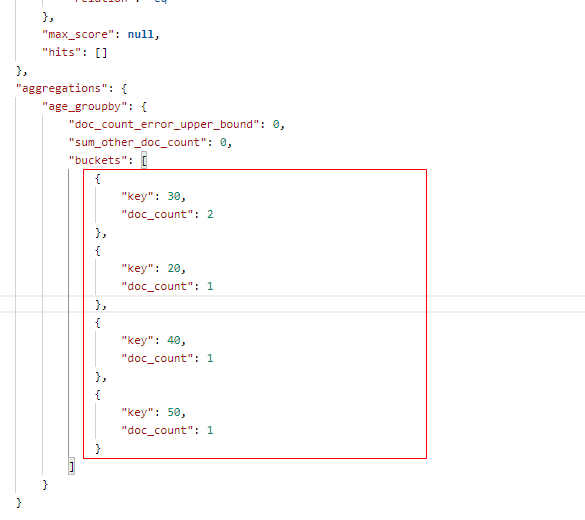
12.7、分组求数量(group by)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
在 terms 分组下再进行聚合:
{ "aggs": { "age_groupby": { "terms": { "field": "age" } } }, "size": 0 }
返回结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号