
MapReduce诞生于搜索领域,主要解决的是海量数据处理扩展性差的问题。
- MapReduce将复杂的,运行大规模集群上的并行计算过程高度地抽象两个函数:Map和Reduce
- MapReduce采用“分而治之”策略,将一个分布式文件系统中的大规模数据集,分成许多独立的分片。这些分片可以被多个Map任务并行处理。
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,原因是,移动数据需要大量的网络传输开销
- MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave,Master上运行JobTracker,Slave运行TaskTracker
- Hadoop框架是用JAVA来写的,但是,MapReduce应用程序则不一定要用Java来写。
MapReduce作业运行流程
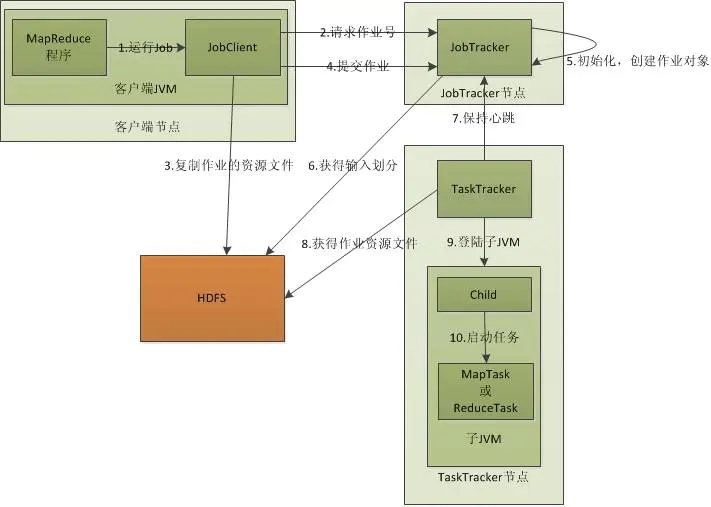
MR框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的不同的从节点上。主节点监视它们的执行情况,并重新执行之前失败的任务。从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接受到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。JobTracker可以运行于集群中的任意一台计算机上。TaskTracker负责执行任务,它必须运行在DataNode上,DataNode既是数据存储节点,也是计算节点。JobTracker将map任务和reduce任务分发给空闲的TaskTracker,这些任务并行运行,并监控任务运行的情况。如果JobTracker出了故障,JobTracker会把任务转交给另一个空闲的TaskTracker重新运行。
HDFS和MR共同组成Hadoop分布式系统体系结构的核心。HDFS在集群上实现了分布式文件系统,MR在集群上实现了分布式计算和任务处理。HDFS在MR任务处理过程中提供了文件操作和存储等支持,MR在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成分布式集群的主要任务。
———————
作者:张晓天a
链接:https://www.jianshu.com/p/9351f2514f75
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:张晓天a
链接:https://www.jianshu.com/p/9351f2514f75
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号