上周内容回顾
正则表达式
简介
首先正则表达式不属于任何一门编程语言,是一个独立的学科,作用于数据的筛选与查找及校验。
正则表达式本质上就是使用一些符号的组合产生一些特殊的含义,然后去字符串中筛选符合条件的数据。
正则表达式线上测试网址:http://tool.chinaz.com/regex/
正则表达式之字符组
字符组在没有被量词修饰的情况下一次只会针对一个数据值,其中在中括号内编写的多个数据值彼此之间都是或的关系。
字符组表格
| [0-9] | 匹配从0到9之间的任意数字,包括0和9 |
|---|---|
| [A-Z] | 匹配从大写字母A到Z之间的任意字母包括A和Z |
| [a-z] | 匹配从小写字母a到z之间的任意字母包括a和z |
如[0-9a-zA-Z],数字、小写字母、大写字母,这种组合也是可以的。
正则表达式之特殊符号
特殊符号在没有量词修饰的情况下一个特殊符号一次只会针对一个数据值。
特殊符号表格
| 特殊符号 | 作用 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母、数字、下划线 |
| \W | 匹配非字母、数字、下划线 |
| \d | 匹配数字 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| a|b | 匹配字符a或b |
| () | 给正则表达式分组,不影响正则表达式的匹配 |
| [] | 匹配字符组中的字符 |
| [^] | 匹配处理字符组中字符的索引字符 |
正则表达式之量词
在正则表达式量词中所有的量词默认都是贪婪匹配,量词不能单独使用,必须跟在表达式后面,并且只能影响紧挨着坐标的那一个。
量词符号表格
| 量词符号 | 作用 |
|---|---|
| * | 重复零次或者多次,默认尽可能多。 |
| + | 重复一次或者多次,默认尽可能多。 |
| ? | 重复零次或者一次,默认就一次 |
| 重复n次 | |
| 重复n次或者更多次 | |
| 重复n到m次 |
贪婪匹配、非贪婪匹配
贪婪匹配与非贪婪匹配简单概括。
所有的量词默认都是贪婪匹配,但如果量词的后面紧跟一个问号,那么就会变成非贪婪匹配。
我们在使用贪婪匹配或者非贪婪匹配的时候一般都是用 . * 或 . * ?的方式。
如下示例:
# 待匹配的文本
<script>alert(123)</script>
<.*> # 贪婪匹配
# 上述正则匹配出来的内容是 <script>alert(123)</script>
<.*?> # 非贪婪匹配
# 上述正则匹配出来的内容是:<script> </script>
正则表达式之取消转义
正则表达式中取消斜杠与字母的特殊含义需要在斜杠的前面在加一个斜杠用来表示取消其特殊含义
其中每个斜杠只能取消一个斜杠的特殊含义。
示例:
\n
# 取消上述的特殊含义则是 \\n
\\n
# 如果是多个则需要继续累加斜杠如 \\\\n
# 在python中则有更加简单的方法
r'\n' 或 r'\\n'
正则表达式常见方式
编写校验用户手机号的正则
0?(13|14|15|17|18|19)[0-9]{9}
编写校验用户身份证的正则
\d{17}[\d|x]|\d{15}
编写校验用户邮箱的正则
\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}
编写校验用户qq号的正则
[1-9]([0-9]{5,11})
编写校验数字或者小数的正则
'^\d+\d$|^\d+\.\d+\d$'
"""
常见的正则百度查找即可 我们需要做到的时候能够看到别人写的
能够完成基础的修改即可
"""
模块
re模块
在python中如果想要使用正则表达式re模块是其中选择之一
re.findall
findall通过正则表达式筛选出文本中所有符合条件的数据
res = re.findall('a', 'jason oscar aaa')
print(res) # ['a', 'a', 'a', 'a', 'a'] 列表
re.finditer
fiditer与findall作用一致,不过其结果会处理正迭代器对象,用于节省内存
res = re.finditer('a', 'jason oscar aaa')
print(res) # <callable_iterator object at 0x000002514D4F5C70>
re.search
search通过正则表达式匹配到一个符合条件的内容就会结束
res = re.search('a', 'jason oscar aaa')
print(res) # <re.Match object; span=(1, 2), match='a'>
print(res.group()) # a
re.match
match通过正则表达式从头开始匹配,如果开头已经符合了那么后面就不会再匹配了。
res = re.match('a', 'jason oscar aaa')
print(res) # None
re.compile
compile能够提前准备号正则,之后可以反复使用,减少代码重复。
obj = re.compile('a')
print(re.findall(obj,'asjd21hj13123j'))
print(re.findall(obj,'fdh3jh45jhqjha'))
print(re.findall(obj,'asdasdadadasda'))
分组
使用括号将需要匹配的数据中其中需要单独区分的数据括起来,起到分组的作用
findall针对分株的正则表达式匹配到的结果优先展示。
如下示例:
# 分组前
res = re.findall('abc','abcabcabcabc')
print(res) # ['abc', 'abc', 'abc', 'abc']
# 分组后
res = re.findall('a(b)c','abcabcabcabc'
print(res) # ['b', 'b', 'b', 'b']
别名
别名是可以再括号内针对需要匹配的数据取别名的方式,便于后期调用。
在需要起别名的数据用?P+别名的方式给其取别名便于调用。
如下示例:
res = re.search('a(?P<id>b)(?P<name>c)','abcabcabcabc')
print(res.group())
print(res.group(1))
print(res.group('id'))
print(res.group('name'))
openpyxl模块
openpyxl模块属于第三方模块,主要用于操作excel表格,也是pandas模块底层操作表格的模块。
在python中能够操作excel表格的模块有很多,openpyxl属于近几年流行的模块。
openpyxl针对03版本之间的excel文件兼容性不好,xlwt、xlrd也可以操作excel表格
兼容所有版本的excel文件,但是使用方法没有openpyxl简单。
-
excel版本问题
03版本之前,excel文件的后缀名是 .xls
03版本之后,excel文件的后缀名是 .xlsx
如果是苹果电脑excel文件的后缀名则是 . csv
-
下载模块
因为openpyxl属于第三方模块,解释器中没有的需要在解释器中利用pip下载
下载方式,如在计算机命令窗口输入 pip3.8 install openpyxl
openpyxl实操
创建excel文件,如下
1.创建excel文件
from openpyxl import Workbook # 导入模块
wb = Workbook() # 创建excel文件
wb1 = wb.create_sheet('成绩表')
wb2 = wb.create_sheet('财务表')
wb3 = wb.create_sheet('校花表', 0)
wb1.title = '舔狗表' # 支持二次修改
wb1.sheet_properties.tabColor = "1072BA" # 修改工作簿颜色
wb.save(r'111.xlsx') # 保存文件
2.写入数据
# 第一种写入方式
wb1['A1'] = '叙利亚悍匪'
wb1['D2'] = '慢男'
# 第二种写入方式
wb1.cell(row=3, column=2, value='老六慢走')
# 第三种写入方式(批量写入)
wb1.append(['username','password','age','gender','hobby'])
wb1.append(['jason1',123,18,'male','read'])
wb1.append(['jason2',123,18,'male','read'])
wb1.append(['jason3',123,18,'male','read'])
wb1.append(['jason4',123,18,'male','read'])
wb1.append(['jason4',123,18,'male',None])
wb1.append([None,123,18,'male',''])
wb1['F11'] = '=sum(B5:B10)'
openpyxl模块读取数据
其实openpyxl并不擅长读取数据,还有一些模块在他原有的基础上优化了读取方式。
代码实操:
from openpyxl import load_workbook # 导入模块
wb = load_workbook(r'111.xlsx',data_only=True)
print(wb.sheetnames) # 查看excel文件中所有的工作簿名称 ['信息表']
wb1 = wb['信息表']
print(wb1.max_row) # 查看工作簿中共有多少行
print(wb1.max_column) # 查看工作簿中共有多少列
print(wb1['A1'].value) # 根据表格中的A1对应的位置取值 取出工作簿中位置所对应的数据
print(wb1.cell(row=2,column=2).value) # 第二种取值方式 根据具体位置数据所在的多少行多少列取值
# 循环取值1 循环取出表格中所有数据
for i in wb1.rows: # 循环取出每行
print([j.value for j in i]) # 循环将每行中的数据打印出来结果是列表形式
"""
[0, '姓名', '年龄', '性别']
[1, 'jason', 27, '男']
[2, 'mmm', 25, '男']
[3, 'lili', 24, '女']
[4, 'kkk', 48, '男']
[5, 'lll', 58, '男']
"""
# 循环取值2 循环取出表格中所有数据
for j in wb1.columns: # 循环取出每列
print([i.value for i in j])
"""
['姓名', 'jason', 'mmm', 'lili', 'kkk', 'lll']
['年龄', 27, 25, 24, 48, 58]
['性别', '男', '男', '女', '男', '男']
"""
random随机模块
random.random
random返回0到1之间随机的小数。
import random
print(random.random()) # 0.06719751436154253
random.randint
randint是返回1到6之间的随机整数,包括1和6
import random
print(random.randint(1,6))
random.choice
chouce随机抽取其数据集内其中一个数据值。
import random
print(random.choice(['特等奖','一等奖','二等奖','三等奖' '谢谢惠顾',])) # 随机抽取一个
random.sample
sample随机抽取数据值,可以自定义抽取数量。
import random
print(random.sample(['特等奖','一等奖','二等奖','三等奖' '谢谢惠顾',],3)) # 随机抽取三个
random.shuffle
shuffle随机打乱列表中的位置
import random
l1=['特等奖','一等奖','二等奖','三等奖', '谢谢惠顾',]
random.shuffle(l1)
print(l1) # ['特等奖', '一等奖', '谢谢惠顾', '二等奖', '三等奖']
笔试题
需求:编写python代码,产生五位随机验证码(数字、大写字母、小写字母)
code = '' # 定义全局变量用于存储所有的验证码
import random
for i in range(5):
# 每次循环都应该产生 数字 小写字母 大写字母
random_int = str(random.randint(0, 9)) # 随机产生一个数字
random_lower = chr(random.randint(97, 122)) # 随机产生一个小写字母
random_upper = chr(random.randint(65, 90)) # 随机产生一个大写字母
# 从上述三个数据值中随机挑选一个作为验证码的一位数据
temp = random.choice([random_int, random_lower, random_upper])
code += temp # 拼接字符串
print(code) # BxhHu
# 也可以封装成函数形式
def get_code(n):
code = '' # 定义全局变量用于存储所有的验证码
# 编写python代码 产生五位随机验证码(数字、小写字母、大写字母)
for i in range(n):
# 每次循环都应该产生 数字 小写字母 大写字母
random_int = str(random.randint(0, 9)) # 随机产生一个数字
random_lower = chr(random.randint(97, 122)) # 随机产生一个小写字母
random_upper = chr(random.randint(65, 90)) # 随机产生一个大写字母
# 从上述三个数据值中随机挑选一个作为验证码的一位数据
temp = random.choice([random_int, random_lower, random_upper])
code += temp # 拼接字符串
return code
res = get_code(4)
print(res)
res1 = get_code(10)
print(res1
hashlin加密模块
加密
加密就是将明文数据(可以看懂的数据)经过处理后变成密文数据(看不懂的数据)的过程
加密可以让敏感的数据不会轻易泄露,一般情况下如果是一串没有规则的数字、符号、字母的组合一般都是加密之后的结果。
加密算法
就是对明文数据采用加密策略,不同的加密算法复杂度不一样,得出的结果长短也不一样。
通常情况下加密之后的结果越长,说明采用的加密算法越复杂,常见的加密算法:md5、sha系列、hmac、base64。
代码实战
import hashlib
md5 = hashlib.md5() # 选择md5加密算法作为数据的加密策略
md5.update(b'aaa') # 往里面添加明文数据 数据必须是bytes类型
print(md5.hexdigest()) # 打印加密之后的结果 47bce5c74f589f4867dbd57e9ca9f808
加密模块之补充
-
加密之后的结果一般情况下不能反解密,所谓的反解密很多时候其实是偷换概念。
提前假设别人的密码是什么,然后用各种算法算出对应的密文,之后构造对应关系然后比对密文最终映射明文。
-
只要明文数据是一样的那么采用相同的算法得出的密文肯定一样
代码操作验证
import hashlib md5 = hashlib.md5() # 选择md5加密算法作为数据的加密策略 md5.update(b'aaa') # 往里面添加明文数据 数据必须是bytes类 md5.update(b'bbb') md5.update(b'ccc') print(md5.hexdigest()) # d1aaf4767a3c10a473407a4e47b02da6 md5.update(b'aaabbbccc') print(md5.hexdigest()) # d7f2f48c64921d5563d800529c7835c9
加盐处理
加盐处理指的是在加密的过程中在添加一些干扰项,增加密文的复杂度。
如下:
import hashlib
md5 = hashlib.md5()
# 示例1 加盐处理之前
md5.update(b'aaa') # 47bce5c74f589f4867dbd57e9ca9f808
print(md5.hexdigest())
# 示例2 加盐处理之后
md5.update('干扰项'.encode('utf8'))
# 在加密真正的明文之前先加入一个干扰项
md5.update(b'aaa')
print(md5.hexdigest()) # 93c9fb7d2e93ec6b7eff252194b678e9
动态加盐
动态加盐指的是每次在加密之前涉资的干扰项,每次度会不同
可能是每次获取当前时间或者是截取用户明的一段,这个相对于固定加盐处理更加复杂些。
加密实际应用常见
-
用户密码注册加密
用户注册密码后将其密码加密后存入数据库。
用户登录时将其密码加密后用来比对数据库中的密文密码是否一致,一致后可登录。
-
文件安全校验
正规的软件程序写完之后做一个加密处理,写入文件中,网站提供软件,文件记忆该软件对应的密文。
用户下载完成后不会直接运行,而是对下载的内容做加密操作,然后比对跟文件中的密文做对比是否一致。
如果一致表示该软件没有被修改果,不一致可能在基于网络传输的时候被不法分子截取,植入果病毒。
-
大文件加密
当一个程序文件过大,比如文件有100G,一般情况下读取100G内容直接全部加密速度太慢。
我们可以换个方式,不对100G中全部内容加密,而是采用截取的方式一部分一部分的加密比如每隔500M读取30bytes用于加密。
subprocess远程命令模块
subprocess模块用于模拟计算机命令窗口
代码操作:
cmd = input('请输入您的指令>>>:').strip()
sub = subprocess.Popen(cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
# stdout执行命令之后正确的返回结果
print(sub.stdout.read().decode('gbk'))
# stderr执行命令报错之后的返回结果
print(sub.stderr.read().decode('gbk'))
logging日志模块
日志就是类是于历史记录,也就是为了记录事物发生的事实。
日志的等级
首先使用日志要先了解它,其中日志可以简单的分为五个级别。
import logging
logging.debug('debug等级') # 10
logging.info('info等级') # 20
logging.warning('warning等级') # 默认从warning级别开始记录日志 30
logging.error('error等级') # 40
logging.critical('critical等级') # 50
日志的基本使用
import logging
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR )
logging.error('记录日志')
日志模块的组成部分
import logging
# 1.日志的产生(准备原材料) logger对象
logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) format对象
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('CV真的好开心')
"""
我们在记录日志的时候 不需要向上述一样全部自己写 过于繁琐
所以该模块提供了固定的配置字典直接调用即可
"""
日志配置字典
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# logger1 = logging.getLogger('购物车记录')
# logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
# logger1 = logging.getLogger('注册记录')
# logger1.debug('jason注册成功')
logger1 = logging.getLogger('日志记录')
logger1.debug('记录了事情')
实列
# 按照软件开发目录规范编写使用
日志字典数据应该放在哪个py文件内
字典数据是日志模块固定的配置 写完一次之后几乎都不需要动
它属于配置文件
"""配置文件中变量名推荐全大写"""
该案例能够带你搞明白软件开发目录规范中所有py文件的真正作用
def get_logger(msg):
# 记录日志
logging.config.dictConfig(settings.LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger(msg)
# logger1.debug(f'{username}注册成功') # 这里让用户自己写更好
return logger1
第三方模块的下载
第三方模块的下载首先需要用到python解释器中的pip工具,其中第三方模块必须先下载才可以导入使用。
借助于pip工具将第三方模块下载好,在操作系统中cmd命令窗口,输入下载命令: pip3.8 install 模块名,下载。
常见的下载报错
有些模块在下载使用之前需要提前配置好指定的环境,具体需要结合情况,如有遇到浏览器搜索即可
在下载模块中可能会因为某些原因导致下载失败,以下列举常见的简单报错信息
-
pip工具版本过低
pip工具版本过低,直接俄拷贝信息提示里面的更新命令即可
python38 -m pip install --upgrade pip
-
网络波动问题
网络波动报错,在最底层有个关键字 Read timed out
只需要重新下载即可,多次尝试下载,或切换一个稳定一点的网络下载。
-
模块版本
其中模块也是有版本的列如:pip3.8 install django == 1.11.11
-
下载速度慢
pip工具默认是从国外的第三方模块仓库中下载模块,所以速度很慢,我们可以试着切换下载地址(源地址)
在我们国内也有着提供第三方模块下载的地址,从上面下载速度上会快一点。
如: pip3.8 install 模块名 -i (源地址, 国内的下载地址)
其中浏览器上就可以搜索到国内的下载地址, 如下:
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
简单的下载流程
其中pyCharm也提供第三方模块下载,下列在pyCharm中简单介绍下载第三方模块方式
-
在pycharm中使用快捷键 Ctrl+Alt+S 打开设置窗口
找到project:文件名,在点击python interpreter 找到pip点击进去
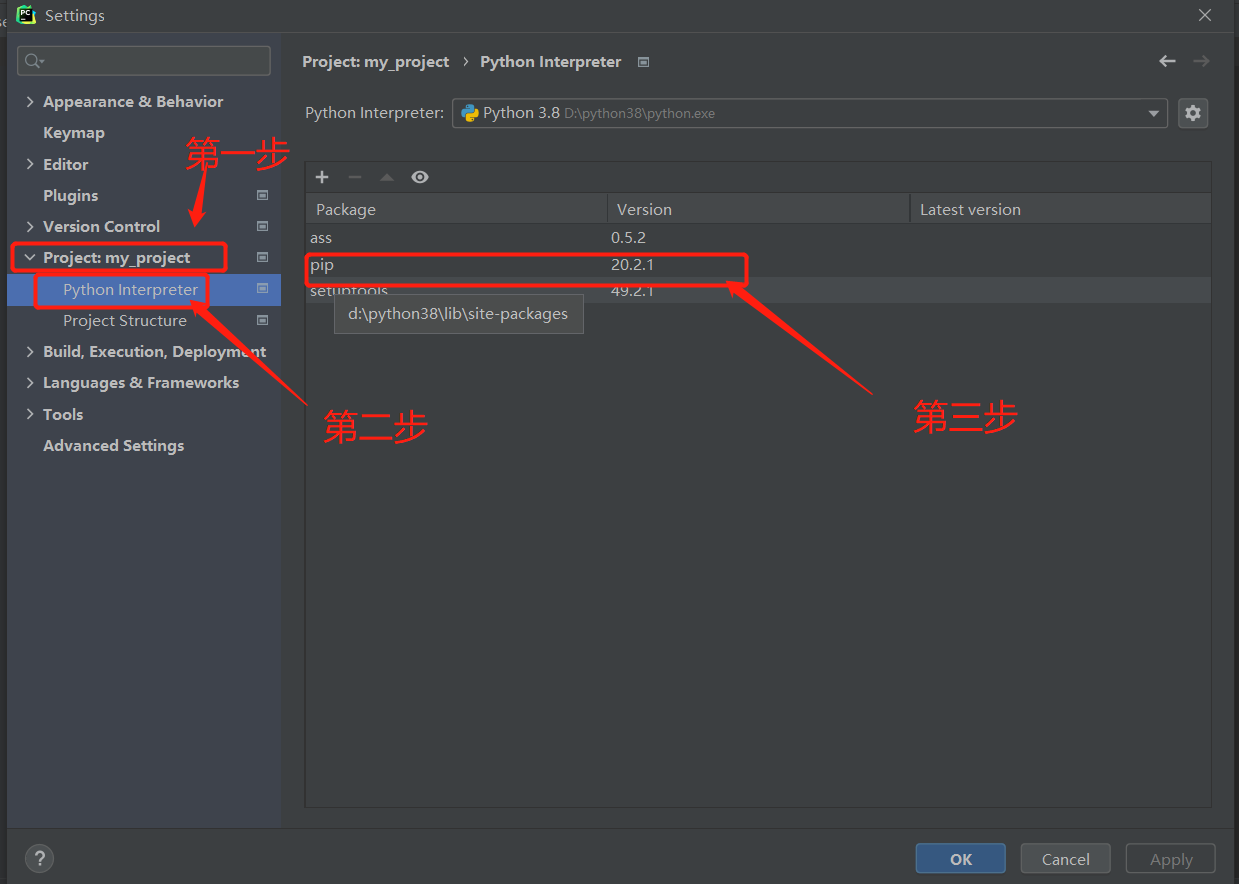
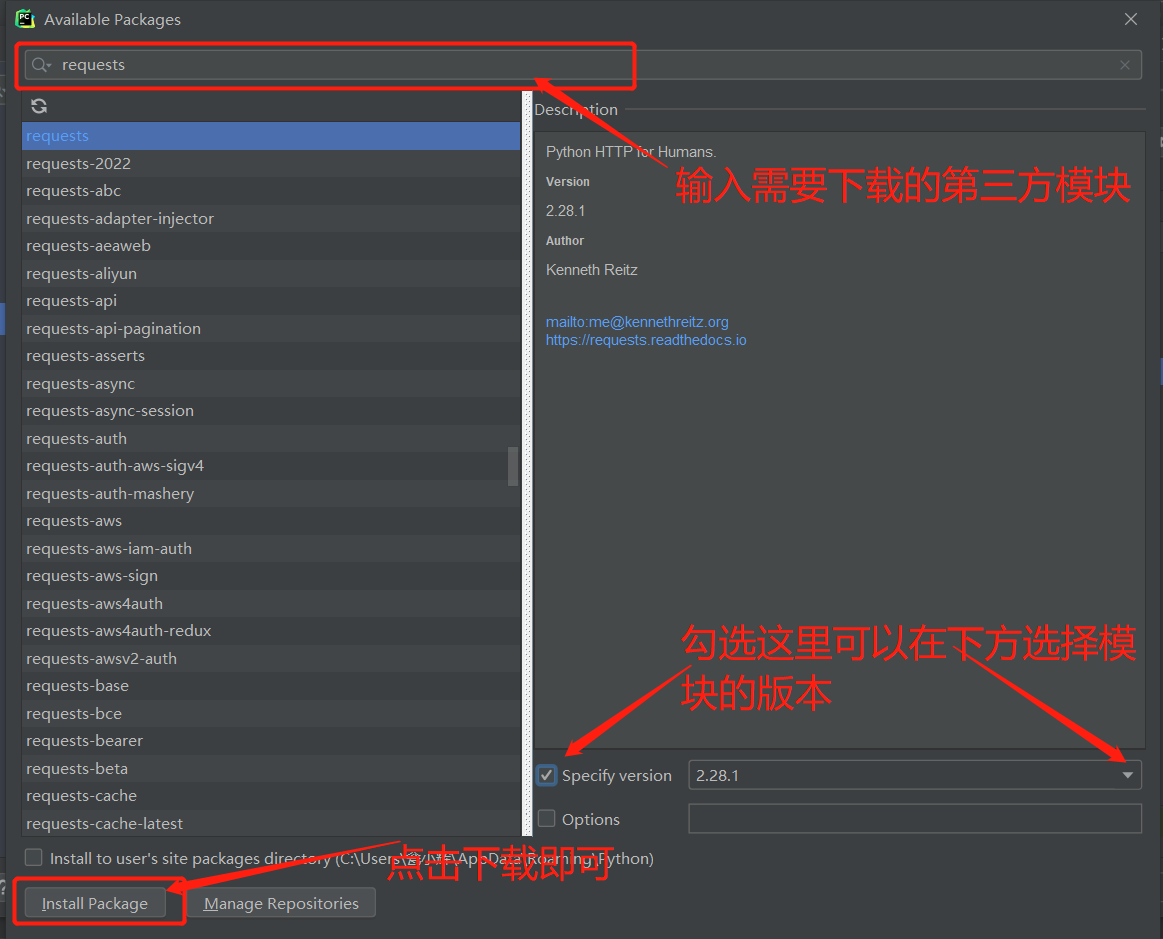
-
在下方输入需要下载的模块名点击左下角install package下载即可,
也可在右下方specify version勾选,选着对应支持的模块版本下载。
网络爬虫
简介
互联网是将全世界的计算机链接到一起组成的网络,目的是将接入互联网的计算机上面的数据彼此共享。
其中上网的本质是基于互联网访问别人计算机上面的资源。
有些计算机存在的意义就是为了让别人访问,这种类型的计算机我们也称之为服务器
网络爬虫的本质
可以简单的理解为,就是模拟计算机浏览器朝目标网址发送请求爬取所需要的数据回去并筛选。
只要是浏览器可以访问到的数据网络爬虫理论上是都已爬取的。
爬虫实战
实战示例1
import requests
# 朝目标地址发送网络请求获取响应数据(相当于在浏览器地址栏中输入网址并回车)
# res = requests.get('http://www.redbull.com.cn/about/branch')
# print(res.content) # 获取bytes类型的数据
# print(res.text) # 获取解码之后的数据
# 为了避免每次执行程序都要发送网络请求 也可以提前保存页面数据到文件
# with open(r'hn.html','wb') as f:
# f.write(res.content)
import re
# 读取页面数据
with open(r'hn.html', 'r', encoding='utf8') as f:
data = f.read()
# 研究目标数据的特征 编写正则筛选
# 1.获取所有的分公司名称
company_name_list = re.findall('<h2>(.*?)</h2>', data)
# print(res)
# 2.获取所有的分公司地址
company_addr_list = re.findall("<p class='mapIco'>(.*?)</p>", data)
# print(company_addr_list)
# 3.获取所有的分公司邮箱
company_email_list = re.findall("<p class='mailIco'>(.*?)</p>", data)
# print(company_email_list)
# 4.获取所有的分公司电话
company_phone_list = re.findall("<p class='telIco'>(.*?)</p>", data)
# print(company_phone_list)
# 5.将上述四个列表中的数据按照位置整合
res = zip(company_name_list, company_addr_list, company_email_list, company_phone_list)
# 6.处理数据(展示 保存 excel)
for i in res: # ('红牛杭州分公司', '杭州市上城区庆春路29号远洋大厦11楼A座', '310009', '0571-87045279/7792')
print("""
公司名称:%s
公司地址:%s
公司邮箱:%s
公司电话:%s
""" % i)
实战示例2
import requests
import re
for numb in range(101):
lj_website = 'https://sh.lianjia.com/ershoufang/pg%s/' % numb
lj_data = requests.get(lj_website)
with open(r'lj_secondhand.html', 'ab') as f:
f.write(lj_data.content)
res1 = time.time()
print(res1-res)
with open(r'lj_secondhand.html', 'r', encoding='utf8') as f:
lj_data = f.read()
list1 = re.findall(
'<a class="" href=".*?" target="_blank" data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',
lj_data
)
list2 = re.findall('href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>', lj_data)
list3 = re.findall(' - <a href=".*?" target="_blank">(.*?)</a>', lj_data)
list4 = re.findall('<span class="houseIcon"></span>(.*?)</div>', lj_data)
list41 = []
list42 = []
list43 = []
for i in list4: # # 2室2厅 | 96.46平米 | 南 北 | 精装 | 中楼层(共6层) | 2007年建 | 板楼
i = i.strip()
i = i.split(' | ')
list41.append(i[0]+','+i[1]+','+i[2],)
list42.append(i[3]+','+i[4])
if 7 == len(i):
list43.append(i[5]+','+i[6])
else:
list43.append(i[5])
print(list43)
print(len(list43))
list5 = re.findall(
'<div class="followInfo"><span class="starIcon"></span>(.*?)</div>',
lj_data
)
list6 = re.findall(
'<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span><i>万</i></div>',
lj_data
) # 共计数据3030 爬取3029条少了一条...
list7 = re.findall(
'<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div>',
lj_data
)
import pandas
d = {
'房屋标题': list1,
'小区名称': list2,
'所在街道': list3,
'户型,面积,朝向': list41,
'状况,楼层': list42,
'建造年份,楼栋状况': list43,
'其他信息': list5,
'房屋总价': list6,
'房屋单价': list7,
}
df = pandas.DataFrame(d)
df.to_excel(r'333.xlsx')
项目开发流程
1.需求分析
明确项目的主体功能(到底要写什么东西 实现什么功能)
问产品经理 问客户
参与人员
产品经理 开发经理 架构师
技术人员主要职责
引导客户提出一些比较合理 比较容易实现的需求
2.架构设计
明确项目的核心技术点
项目使用的编程语言
项目使用的框架
项目使用的数据库
参与人员
架构师
3.分组开发
明确每个组每个人写哪些功能
参与人员
架构师 开发经理
普通的程序员
4.提交测试
自己测试、测试小姐姐测试
参与人员
普通的程序员
测试小姐姐
5.交付上线
参与人员
运维工程师
可以交给客户也可以帮客户维护(定期收钱)
大公司好
大公司你相当于是一颗螺丝钉 干的活儿非常的明确 只干很小的一部分
但是对自己的履历很有优势 将来跳槽方便
小公司好
小公司你相当于是全能超人 什么事都自己干 短期内提示非常大
但是会非常的类 一个人干好几个人的活儿
项目需求分析
# 主题是带大家快速入门python直至开发一个ATM+购物车系统,ATM的实现类似于银行自助提款机核心业务,购物车的实现类似于淘宝商城购物系统。
# 该项目的核心不仅在于引领初学者快速入门python项目开发,更是站在项目架构的角度教你如何在程序开发之初合理且优雅地设计程序的架构,从而极大地提升程序的开发效率与可扩展性
"""
- 额度15000或自定义
- 支持多账户登录
- 可以查看账户余额
- 可以提现(可自定义手续费比例)
- 提供还款接口
- 支持账户间转账
- 记录每月日常消费流水
- 实现购物商城,买东西加入购物车,调用信用卡接口结账
- 提供管理接口,包括添加账户、用户额度,冻结账户等
- ATM记录操作日志
- 用户认证功能
"""
从需求中提炼出项目的核心功能
1.用户注册
2.用户登录
3.查看余额
4.账户提现
5.充值功能
6.转账功能
7.查看账单
8.购物车功能
9.管理员功能
从功能中再提炼出核心技术点
1.python核心语法
2.python诸多模块
3.装饰器
架构设计
"""
编写代码的改进历程
1.直接写在一个文件 采用面条版堆积
2.将有些具体的功能 采用函数封装
上述两个阶段类似于小公司 一个员工身兼数职
3.将不同的功能拆分到不同的文件
上述阶段类似于大公司 工具职责划分部门 每个员工只干该岗位的具体事宜
ps:拆分的目的是为了更好的管理资源和代码 提升程序的扩展性
"""
项目架构(重要)
百度
以用户登录为例
1.浏览器页面获取用户名和密码
2.基于网络将用户名和密码发送给百度服务端
3.服务端去数据库中校验用户数据
三层架构
浏览器、服务端、数据库
淘宝
以购买商品为例
1.浏览器页面展示商品总价
2.基于网络将购买商品的操作发送给服务端做核心校验
3.之后操作相应数据库完成数据修改
三层架构
浏览器、服务端、数据库
三层架构
用户层
数据展示 数据获取
cmd窗口可以充当用户层
将来可以替换成浏览器或者app
核心逻辑层
业务逻辑
某个py文件充当逻辑层
将来可以替换成软件开发目录规范或者现成的框架
数据层
数据的增删改查
json文件充当数据库
将来可以替换成数据库程序
项目目录搭建
core
src.py 充当第一层
interface 充当第二层
user_interface.py 根据业务逻辑的不同再次拆分便于后期维护管理
bank_interface.py
shop_interface.py
admin_interface.py
第三层 后续通过代码动态创建 或者直接创建db
面向对象
编程思想
面向过程编程
过程其实就是流程,面向过程其实就是在执行一系列的流程,
面向过程编程相当于让你给出问题的具体的解决方案
面向对象编程
面向对象编程,核心就是 对象
对象其实就是一个容器,里面将数据和功能绑定到了一起,面向对象编程相当于让你创造一些书屋之后就不用你管了。
类与对象
类与对象的概念
对象:数据和功能的结合体,对象用于记录多个对象不同数据和功能。
类:多个对象相同数据和功能的结合体,类主要用于记录多个对象相同的数据和功能。
在面向对象编程中,类仅仅用于节省代码,对象才是核心。
类与对象的创建
在编程世界里必须是现有类才能够产生对象,面向对象编程的本质就是将数据和功能绑定在一起。
但是为了突出面向对象编程的形式python特地开发了一套语法,专门用于面向对象编程的操作。
创建类的语法结构
代码示例
class Student:
# 对象的公共数据
# 对象的公共方法
"""
1.class 是创建类的关键字
2.Student 是类的名字
类的命名跟变量名相似,并且为了便于取出类名的首字母推荐大写。
3.类体代码
公共的数据、功能的方法
其中类体代码在类定义阶段就会执行!!!
"""
查看名称空间的方法
使用类名句点的方式点出双下dict打印出类名称空间的名字, 可以讲里面数据看成一个字典形式组成的
print(Student.__dict__)
# 使用字典的取值方式获取名字
print(Student.__dict__.get('choice_course'))
"""
在面向对象编程中,想要获取名称空间中的名字,可以采用句点符。
"""
类实列化产生对象
如下:
class Student: # 定义类的关键字class 类的名称 Student
# 构造方法,传入name、age、course三个参数
def __init__(self, name, age, course):
self.name = name
self.age = age
self.course = course
school = '清华大学'
# 实例方法1
def get_name(self): # 通过对象里面的方法访问name的属性
return "姓名:%s" % self.name
# 实例方法2
def get_age(self): # 通过对象里面的方法访问age的属性
return r"年龄:%s" % self.age
# 实例方法3
def get_course(self): # 通过对象里面的方法访问course的属性
return "最高成绩%s" % max(self.course)
# Student 这个类实例化了一个对象 jason
stu1 = Student('jason', 28, [66, 87, 100])
print(stu1.school)
print(stu1.get_name())
print(stu1.get_age())
print(stu1.get_course())
"""
公共的数据:
清华大学
独有的数据:
姓名:小明
年龄:28
最高成绩100
我们习惯将类或者对象句点符后面的东西称为属性名或者方法名
"""
对象的独有数据
# 学生类
class Student:
# 学生对象公共的数据
school = '清华大学'
# 学生对象公共的方法
def choice_course(self):
print('正在选课')
"""
推导思路
直接利用__dict__方法朝字典添加键值对
"""
obj1 = Student()
obj1.__dict__['name'] = 'jason' # 等价于 obj1.name = 'jason'
obj1.__dict__['age'] = 18 # 等价于 obj1.age = 18
obj1.__dict__['gender'] = 'male'
print(obj1.name)
print(obj1.age)
print(obj1.gender)
print(obj1.school)
obj2 = Student()
obj2.__dict__['name'] = 'kevin'
obj2.__dict__['age'] = 28
obj2.__dict__['gender'] = 'female'
print(obj2.name)
print(obj2.age)
print(obj2.gender)
print(obj2.school)
"""
推导思路2
将添加独有数据的代码封装成函数
"""
def init(obj,name,age,gender):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
obj.__dict__['gender'] = gender
stu1 = Student()
stu2 = Student()
init(stu1,'jason',18,'male')
init(stu2, 'kevin',28,'female')
print(stu1.__dict__)
print(stu2.__dict__)
"""
推导思路3:
init函数是专用给学生对象创建独有的数据,
其他对象不能调用>>>:面向对象思想 将数据和功能整合到一起
将函数封装到学生类中 这样只有学生类产生的对象才有资格访问
"""
class Student:
"""
1.先产生一个空对象
2.自动调用类里面的__init__方法 将产生的空对象当成第一个参数传入
3.将产生的对象返回出去
"""
def __init__(self, name, age, gender):
self.name = name # obj.__dict__['name'] = name
self.age = age # obj.__dict__['age'] = age
self.gender = gender # obj.__dict__['gender'] = gender
# 左右两边的名字虽然一样 但是意思不一样 左边的其实是字典的键 右边的其实是实参
# 学生对象公共的数据
school = '清华大学'
# 学生对象公共的方法
def choice_course(self):
print('正在选课')
# stu1 = Student()
# print(stu1.__dict__)
# Student.init(stu1, 'jason', 18, 'male')
# print(stu1.__dict__)
# print(stu1.name)
stu1 = Student('jason', 18, 'male')
print(stu1)
stu2 = Student('kevin', 28, 'female')
print(stu2)
对象的独有功能
针对对象独有的功能我们无法真正实现,定义在类里面的方法原则上是公共的方法。
但其本质上是那个对象调用属于那个对象独有的功能。
如下:
# 首先定义一个类
class Student:
# 在类中定义的数据属于公共的数据,在类中定义的函数属于公共方法
school = '清华大学'
# 让对象拥有独有的数据
def __init__(self, name):
self.name = name
# 定义在类中的函数,我们称之为方法
def choice_course(self):
print('%s正在选课' % self.name)
stu = Student('jason')
stu1 = Student('jack')
# 1.在全局给对象独自添加一个功能。
def func():
print("我在全局")
# 2.将功能添加给对象
stu.func = func
# 3.但是如果在全局也不是独有的
stu.func()
# 谁调用类中的方法就属于谁的独有的功能
stu.choice_course() # jason正在选课
stu1.choice_course() # jack正在选课
"""
因此python解释器在针对这类问题添加了一个非常哇塞的特性
定义在类中的函数默认是绑定给对象的(相当于是对象独有的方法)
"""
动静态方法
动静态方法是专门针对在类体代码中编写的函数
绑定给对象的方法
直接在类体代码中编写即可,对象调用会自动将对象当作第一个参数传入,类调用则有几个形参就需要传几个实参。
class Student:
# 在类中定义的数据属于公关的数据,在类中定义的函数属于公共方法
school = '清华大学'
# 定义在类中的函数,我们称之为方法
def choice_course(self):
print('正在选课')
stu = Student()
"""
对象在调用类中的方法,会自动将对象当作第一个参数传入
后面需要几个参数,在根据数量传入即可
"""
stu.choice_course() # jason正在选课
# 类在调用类中的方法,里面需要几个参数则传入几个参数
Student.choice_course(111)
绑定给类的方法
在类体代码中方法上面加入装饰器@classmethod
类调用会自动将类当作第一个参数传入,对象调用会自动将产生对象的类当作参数传入。
示例:
class Student:
# 在类中定义的数据属于公关的数据,在类中定义的函数属于公共方法
school = '清华大学'
@classmethod # 绑定给类的方法
def choice_course(cls): # cls用于接收类
print('正在选课')
stu = Student()
Student.choice_course() # 相当于 Student.choice_course(Student)
stu.choice_course() # stu.choice_course(Student)
静态方法
在类体代码中方法上面加入装饰器@staticmethod,无论谁来调用都必须按照普普通通的函数传参方式。
class Student:
# 在类中定义的数据属于公关的数据,在类中定义的函数属于公共方法
school = '清华大学'
@staticmethod # 静态方法
def choice_course(a,b): # 普通的函数传承
print('正在选课')
stu1 = Student()
Student(111,222)
stu1.sleep(1, 2)
面向对象三大特性
面向对象有着三大特性分别是继承、封装、多态。
继承
继承的含义
在现实生活中,继承用来秒速人与人之间的资源关系,如我们常说的子承父业,继承家产上面的(儿子拥有了父亲所有的资源)
在编程世界里,继承其实就是用来秒速类与类之间数据的关系,比如类A继承了类B (拥有了类B里面所有的数据和功能)
继承的目的
继承的目的就是为了节省代码编写,其中可以继承一个也可以继承多个。
继承的操作
class 类名(被继承的类名):
pass
定义类的时候类名后加括号 括号内填入需要继承的类名,我们将被继承的类 也就是括号内的类称之为>>>: 父类、基类、超类。
将继承类的类称之为>>>: 子类、派生类。
平常我们最常称呼的就是父类、子类。
示例:
class Fatherclass1:
def Father1(self):
print("this Father1号")
class Fatherclass2:
def Father2(self):
print("this Father2号")
class Fatherclass3:
def father3(self):
print("my Father3号")
# 括号内可以填写一个父类,也可以填写多个父类
class Subclass(Fatherclass1, Fatherclass2, Fatherclass3):
print("my Sub_class ")
"""
目前掌握从左到右查找每个父类中的属性即可
"""
继承的本质
当多个类中有同样的数据或者功能,为了避免重复劳动将多个类其中相同的数据和功能抽出来创建一个新的父类。
让其它需要使用它里面功能和数据的类去继承它,白嫖父类其中的数据和功能。
抽象: 将多个类相同的数据或者功能抽取出来形成一个基类
继承: 从上往下白嫖各个基类中的数据和功能
对象: 数据和功能的结合体
类: 多个对象相同的数据和功能的结合体
父类: 多个类相同的数据和功能的结合体
综上所述,一切都是为了节省代码。
名字的查找顺序
- 在不继承的情况下名字的查找顺序
先从对象自身查找,没有的话再去产生该对象的类中查找 对象>>>类
class Student:
school = '清华大学'
def choice_course(self):
print('正在选课')
# 1.产生一个空对象
stu1 = Student()
# 2.对象查找school
print(stu1.school) # 清华大学
"""
自身名称空间没有,会去产生对象的类中查找
在创建对象的类中找到了school>>>: 清华大学
"""
# 3.对象在自身的名称空间内产生了一个新的 school
stu1.school = '北京大学'
# 4.对象查找school
print(stu1.school) # 北京大学
"""
先从对象自身的名称空间查找school
此时的对象自身的名称空间已经有了新school
那么第一个找的是对象自身的名称空间,找到了school>>>:北京大学
"""
# 5.类在查找school 找的是类中的school>>>:清华大学
print(Student.school) # 清华大学
- 单继承的情况下名字的查找顺序
先从对象自身查找,然后是产生该对象的类,然后是一个个父类 对象>>>类>>>父类
# 示例1
class A:
name = 'from A'
pass
class B(A):
name = 'from B'
pass
class C(B):
name = 'from C'
pass
class MyClass(C):
name = 'from MyClass'
pass
obj = MyClass()
# 查找名字name
print(obj.name)
"""
1.先从对象自身查找,对象自身没有
2.再去产生对象的类中查找,如果有则找到。
3.如果没有,再去看产生对象的类中有没有继承父类,如果有则去父类中查找
4.父类中如果有则找到,如果没有再看父类有没有继承类如果有则取其继承的类中查找
5.依次类推知道找到这个名字
列如:
对象>>>类>>>父类>>>父类的父类>>>......
"""
# 示例2
# 定义一个类A1
class A1:
# A1的方法1
def func1(self):
print('from A1 func1')
# A1的方法2
def func2(self):
print('from A1 func2')
self.func1() # obj.func1()
# 定义一个类MyClass,又继承了父类A1
class MyClass(A1):
# MyClass的方法1
def func1(self):
print('from MyClass func1')
# 2.MyClass产生一个空对象
obj = MyClass()
# 对象查找func2
obj.func2()
"""
1.先从对象自身查找,对象自身没有
2.再去产生对象的类 MyClass中查找,产生对象的类 MyClass中也没有
3.再去产生对象的类 MyClass继承的父类A1中查找
4.父类A1中有func2,执行父类A1中的func2,此时的func2中又调用了func1
5.那么又开始从对象自身查找func1,对象自身没有
6.再去产生对象的类 MyClass中查找,产生对象的类 MyClass中有func1,执行func1。
*****
只要涉及到对象查找名字 几乎要回到最开始的位置依次查找
"""
-
多继承的情况下名字的查找顺序
也可以使用类点mro()方法查看该类产生的对象名字的查找顺序
如果涉及到对象查找名字,那么几乎都是 对象>>>类>>>父类......
-
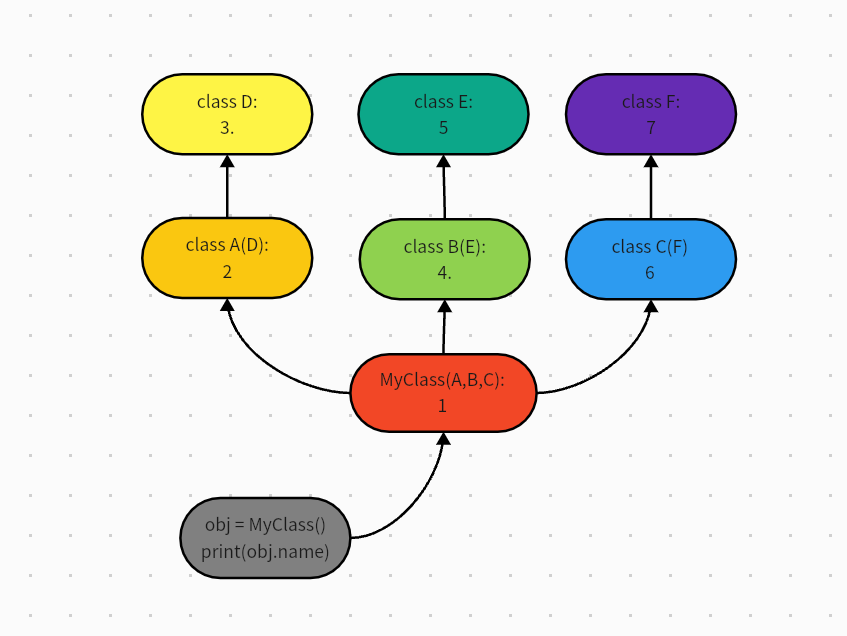
1 非菱形继承(最后不会归总到一个我们之定义的类上)
深度优先(每个分支都走到低)
# 示例1
class F():
name = 'from F'
class E():
pass
class D():
pass
class C(F):
pass
class B(E):
pass
class A(D):
pass
class MyClass(A,B,C):
pass
obj = MyClass()
# 查找名字name
print(obj.name) # 'from F'
-
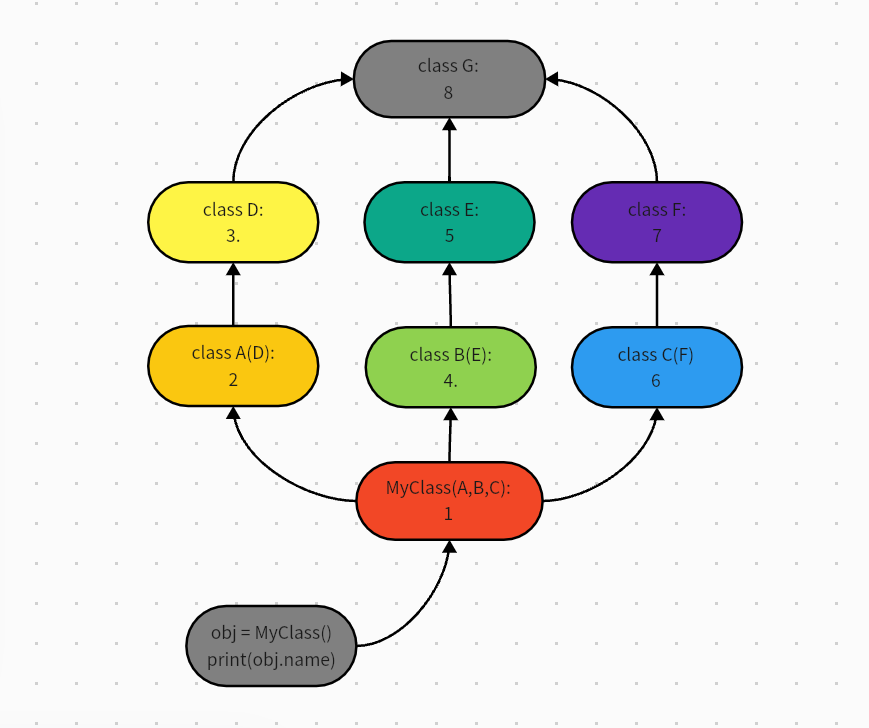
2非菱形继承(最后归总到一个我们中定义的类上)
广度优先(前面几个分支都不会走最后一个类,最后一个分支才会走)
# 示例1
class G():
name = 'from G'
class F(G):
pass'
class E(G):
pass
class D(G):
pass
class C(F):
pass
class B(E):
pass
class A(D):
pass
class MyClass(A,B,C):
pass
obj = MyClass()
# 查找名字name
print(obj.name) # 'fro
封装
什么是封装
封装其实就是将数据或功能隐藏起来(包装起来)
-
隐藏的目的不是让客服无法使用,而是在类的内部给被隐藏的数据开设其他的接口,让用户使用接口才可以去使用,我们在接口中添加一些额外的操作
必须在类定义阶段使用 双下划线开头的名字都是隐藏属性的后续类和对象都无法直接调用
-
其实在python中也不是真正意义上的限制任何代码。
隐藏属性如果真的需要访问,也是可以访问到的只不过访问的方式需要改变一下
可以通过 __ 类名 __ 变量名的方式访问到隐藏的数据或者功能,但这样做就是去了隐藏的意义
class Student(object): __school = '清华大学' def __init__(self, name, age): self.__name = name self.__age = age # 专门开设一个访问学生数据的通道(接口) def check_info(self): print(""" 学生姓名:%s 学生年龄:%s """ % (self.__name, self.__age)) # 专门开设一个修改学生数据的通道(接口) def set_info(self,name,age): if len(name) == 0: print('用户名不能为空') return if not isinstance(age,int): print('年龄必须是数字') return self.__name = name self.__age = age stu1 = Student('jason', 18) # 正常访问是访问不到的,会直接报错 # print(stu1.__school) # 可以通过 _类名__变量名的方式访问 # print(stu1._Student__school) # 清华大学 """ 但是上述方式是不对的,直接失去了隐藏的意义干脆不隐藏得了 """ # 正常方式 通过特定的接口来访问 print(stu1.check_info()) """ 学生姓名:jason 学生年龄:18 """ # 我们编写python很多时候都是大家墨守成规的东西 不需要真正的限制 class A: _school = '清华大学' def _choice_course(self): pass """ 如果看到别人在类体代码中变量名是以 _ 开头的,我们就要知道,这是个隐藏属性的数据 那么我们在调用的时候就需要,特定开设的接口通过接口来访问它 """
多态
什么是多态
多态其实指的就是一种事物的多种形态
如:水有液态、气态、固态 。动物有猫科动物、犬科动物等...
# 示例1:
class Animal(object):
def spark(self):
pass
class Cat(Animal):
def spark(self):
print('喵喵喵')
class Dog(Animal):
def spark(self):
print('汪汪汪')
class Pig(Animal):
def spark(self):
print('哼哼哼')
"""
一种事物,有多种形态,但是有相同的功能。
如上述代码中描述的动物虽然是不同形态的,但是它们有着相同的功能,那么也应该有相同的功能名字
这样的话 以后我无论拿到哪个具体的动物 都不需要管到底是谁 直接调用相同的功能即可
"""
# 示例2:
# python也提供了一种强制性的操作(了解即可) 应该是自觉遵守
import abc
# 指定metaclass属性将类设置为抽象类,抽象类本身只是用来约束子类的,不能被实例化
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod # 该装饰器限制子类必须定义有一个名为talk的方法
def talk(self): # 抽象方法中无需实现具体的功能
pass
class Person(Animal): # 但凡继承Animal的子类都必须遵循Animal规定的标准
def talk(self):
pass
def run(self):
pass
obj = Person()
"""
鸭子类型>>>:只要你长得像鸭子 走路像鸭子 说话像鸭子 那么你就是鸭子
"""
class Teacher:
def run(self):
pass
def eat(self):
pass
class Student:
def run(self):
pass
def eat(self):
pass
"""
操作系统
linux系统:一切皆文件
只要你能读数据 能写数据 那么你就是文件
内存
硬盘
class Txt: #Txt类有两个与文件类型同名的方法,即read和write
def read(self):
pass
def write(self):
pass
class Disk: #Disk类也有两个与文件类型同名的方法:read和write
def read(self):
pass
def write(self):
pass
class Memory: #Memory类也有两个与文件类型同名的方法:read和write
def read(self):
pass
def write(self):
pass
python:
一切皆对象
只要你有数据 有功能 那么你就是对象
文件名 文件对象
模块名 模块对象
"""
property伪装属性
可以简单的理解为,就是将方法伪装成一个数据。伪装之前的方法需要加括号才能调用伪装周不需要加括号就可以调用。
将其伪装调用方法就像是在调用一个数据一样伪装方法只针对无参方法,。
基本使用方法上面加上装饰器@property
示例:
计算体质的方法,体质指数(BMI)=体重(kg)÷身高^2(m)
class Person:
def __init__(self, name, weight, height):
self.name = name
self.weight = weight
self.height = height
# 伪装之前
def BMI(self):
return self.weight / (self.height ** 2)
# 伪装之后
@property
def BMI(self):
return self.weight / (self.height ** 2)
# 调用方法BMI需要加括号才能调用
p1 = Person('jason', 78, 1.83)
res = p1.BMI()
print(res) # 23.291229956104985
# 直接以访问数据的方式可以直接调用方法
p2 = Person('tomy', 65, 1.75)
print(p2.BMI) # 21.224489795918366
示例2
使用property保证了属性访问的一致性,并且property还提供了设置和删除属性的方法
使用@name.setter设置属性和用@name.deleter删除属性
class Foo:
def __init__(self, val):
self.__NAME = val # 将属性隐藏起来
@property
def name(self):
return self.__NAME
@name.setter
def name(self, value):
if not isinstance(value, str): # 在设定值之前进行类型检查
raise TypeError('%s must be str' % value)
self.__NAME = value # 通过类型检查后,将值value存放到真实的位置self.__NAME
@name.deleter
def name(self):
raise PermissionError('Can not delete')
obj = Foo('jason')
# print(obj.name)
# obj.name = 666
# print(obj.name)
del obj.name
面向对象之反射
什么是反射
反射就是通过字符串来操作对象的数据和方法。
反射四种方法
hasattr 判断对象是否含有某和字符串对应的属性
getattr 判断对象字符串对应的属性
setattr 根据字符串给对象设置属性
delattr 根据字符串给对象删除属性
示例:
class Student(object):
school = '清华大学'
def choice_course(self)
print("选课")
stu = Student()
# 1.需求:判断用户提供的名字在不在对象可以使用的范围内
target_name = input('请输入您想要核查的名字>>>:').strip()
"""
接收用户输入得到的是字符串,而对象中存在的是名字
两者虽然只差了引号 但是本质是完全不一样的
可以,使用反射方法进行判断
"""
# 判断对象stu和产生对象的类中是否含有用户提供的target_name对应的属性
if hasattr(stu,target_name):
# 如果对象中含有对应的名字,则获取名字的数据或方法。
res = getattr(stu,target_name)
# 判断获取的名字是否可以加括号调用。
if callable(res)
# 条件成立,则表明拿到的是方法,加括号调用即可
res()
# 条件不成立,则表明拿到的是数据,直接打印即可
else:
print(res)
else:
print("你所提供的名字,对象中没有")
print(stu.__dict__)
stu.name = 'jason'
stu.age = 18
print(stu.__dict__)
# 根据字符串给对象设置属性
setattr(stu,'gender','male')
setattr(stu,'hobby','read')
print(stu.__dict__)
del stu.name
print(stu.__dict__)
# 根据字符串给对象删除属性
delattr(stu, 'age')
print(stu.__dict__)
"""
以后只要在需求中看到了关键字
....对象....字符串
那么肯定需要使用反射
"""
反射实际案例1
class FtpServer:
def serve_forever(self):
while True:
# 让用户按照规定的参数输入,后获取用户输出的命令数据
inp = input('input your cmd>>: ').strip()
# 按照规定好的参数进行切割,切割成俩部分赋值给左边的名字
cmd, file = inp.split()
if hasattr(self, cmd): # 根据用户输入的cmd,判断对象self有无对应的方法属性
func = getattr(self, cmd) # 根据字符串cmd,获取对象self对应的方法属性
func(file)
def get(self, file):
print('Downloading %s...' % file)
def put(self, file):
print('Uploading %s...' % file)
obj = FtpServer()
obj.serve_foreve
反射实际案例2
1.加载配置文件纯大写的配置
# 配置文件加载:获取配置文件中所有大写的配置 小写的直接忽略 组织成字典
import settings
new_dict = {}
# print(dir(settings)) # dir获取括号中对象可以调用的名字
# ['AGE', 'INFO', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'desc', 'name']
for i in dir(settings):
if i.isupper(): # 如果名字是纯大写 那么获取该大写名字对应的值 'AGE' 'INFO'
v = getattr(settings, i)
new_dict[i] = v
print(new_dict)
2.模拟操作系统cmd终端执行用户命令
class WinCmd(object):
def dir(self):
print('dir获取当前目录下所有的文件名称')
def ls(self):
print('ls获取当前路径下所有的文件名称')
def ipconfig(self):
print('ipconfig获取当前计算机的网卡信息')
obj = WinCmd()
while True:
cmd = input('请输入您的命令>>>:')
if hasattr(obj, cmd):
cmd_name = getattr(obj, cmd)
cmd_name()
else:
print('%s 不是内部或外部命令,也不是可运行的程序或批处理文件' % cmd)
面向对象之魔法方法
面向对象中双下方法也有一些人称之为是魔法方法。
有些双下方法不需要调用,到达某个条件会自动触发
class MyClass(object):
def __init__(self, name):
"""实例化对象的时候自动触发"""
# print('__init__方法')
# pass
self.name = name
def __str__(self):
"""
对象被执行打印操作的时候会自动触发
该方法必须返回一个字符串
返回什么字符串打印对象之后就展示什么字符串
"""
# print('__str__方法')
# print('这是类:%s 产生的一个对象')
# return '对象:%s'%self
return '对象:%s'%self.name
def __call__(self, *args, **kwargs):
"""对象加括号调用 自动触发该方法"""
print('__call__方法')
print(args)
print(kwargs)
def __getattr__(self, item):
"""当对象获取一个不存在的属性名 自动触发
该方法返回什么 对象获取不存在的属性名就会得到什么
形参item就是对象想要获取的不存在的属性名
"""
print('__getattr__', item)
return '您想要获取的属性名:%s不存在'%item
def __setattr__(self, key, value):
"""对象操作属性值的时候自动触发>>>: 对象.属性名=属性值"""
# print("__setattr__")
# print(key)
# print(value)
super().__setattr__(key, value)
def __del__(self):
"""对象在被删除(主动 被动)的时候自动触发"""
# print('__del__')
pass
def __getattribute__(self, item):
"""对象获取属性的时候自动触发 无论这个属性存不存在
当类中既有__getattr__又有__getattribute__的时候 只会走后者
"""
# print('__getattribute__')
# return super(MyClass, self).__getattribute__(item) 复杂写法
return super().__getattribute__(item) # 简便写法
def __enter__(self):
"""对象被with语法执行的时候自动触发 该方法返回什么 as关键字后面的变量名就能得到什么"""
print('__enter__')
def __exit__(self, exc_type, exc_val, exc_tb):
"""对象被with语法执行并运行完with子代码之后 自动触发"""
print('__exit__')
魔法方法笔试题
"""补全以下代码 执行之后不报错"""
class Context:
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
pass
def do_something(self):
pass
with Context() as f:
f.do_something()
元类
简介
# s1 = '哈哈哈 今天下午终于可以敲代码了!!!'
# l2 = [60, 80, 100, 120, 150, 200]
# d = {'name': '死给我看', 'age': 18}
# print(type(s1)) # <class 'str'>
# print(type(l2)) # <class 'list'>
# print(type(d)) # <class 'dict'>
"""
基础阶段我们使用type来查找数据的数据类型
但是学了面向对象之后 发现查看的不是数据类型 而是数据所属的类
我们定义的数据类型 其实本质还是通过各个类产生了对象
class str:
pass
h = 'hello' str('hello')
我们也可以理解为type用于查看产生当前对象的类是谁
"""
class MyClass:
pass
obj = MyClass()
print(type(obj)) # 查看产生对象obj的类:<class '__main__.MyClass'>
print(type(MyClass)) # 查看产生对象MyClass的类:<class 'type'>
"""
通过上述推导 得出结论 自定义的类都是由type类产生的
我们将产生类的类称之为 '元类'
"""
产生类的俩种方式
1.class关键字
class MyClass:
pass
2.利用元类type
type(类名,类的父类,类的名称空间)
"""
学习元类其实就是掌握了类的产生过程 我们就可以在类的产生过程中高度定制化类的行为
eg:
类名必须首字母大写
上述需求就需要使用元类来控制类的产生过程 在过程中校验
"""
元类的基本使用
class MyMetaClass(type):
pass
"""只有继承了type的类才可以称之为是元类"""
class MyClass(metaclass=MyMetaClass):
pass
"""如果想要切换产生类的元类不能使用继承 必须使用关键字metaclass声明"""
'''
思考
类中的__init__用于实例化对象
元类中__init__用于实例化类
'''
class MyMetaClass(type):
def __init__(self,what, bases=None, dict=None):
# print('别晕')
# print('what', what) 类名
# print('bases', bases) 类的父类
# print('dict', dict) 类的名称空间
if not what.istitle():
# print('首字母必须大写 你会不会写python 面向对象学过吗 lowB')
raise Exception('首字母必须大写 你会不会写python 面向对象学过吗 lowB')
super().__init__(what, bases, dict)
"""只有继承了type的类才可以称之为是元类"""
# class Myclass(metaclass=MyMetaClass):
# pass
"""如果想要切换产生类的元类不能使用继承 必须使用关键字metaclass声明"""
class aaa(metaclass=MyMetaClass):
pass
元类的进阶
"""元类不单单可以控制类的产生过程 其实也可以控制对象的!!!"""
1.对象加括号执行产生该对象类里面的双下call
2.类加括号执行产生该类的元类里面的双下call
class MyMetaClass(type):
def __call__(self, *args, **kwargs):
print('__call__')
if args:
raise Exception('必须用关键字参数传参')
super().__call__(*args, **kwargs)
class MyClass(metaclass=MyMetaClass):
def __init__(self, name, age):
self.name = name
self.age = age
print('__init__')
# 需求:实例化对象 所有的参数都必须采用关键字参数的形式
obj = MyClass('jason', 18)
# obj = MyClass(name='jason', age=18)
总结
"""
如果我们想高度定制对象的产生过程
可以操作元类里面的__call__
如果我们想高度定制类的产生过程
可以操作元类里面的__init__
"""
双下new方法
"""
类产生对象的步骤
1.产生一个空对象
2.自动触发__init__方法实例化对象
3.返回实例化好的对象
"""
__new__方法专门用于产生空对象 骨架
__init__方法专门用于给对象添加属性 血肉
经典类与新式类
经典类
不继承object或其子类的类(上面都不继承)
新式类
继承了object或其子类的类
版本区别
在python3中所有的类默认都会继承object,也就意味着python3中只有新式类。
在python2中没有经典类和新式类,由于经典类没有核心功能所以到了python3中直接被砍掉了。
示例:
# python2中的经典类和新式类
# 经典类
class MyClass:
pass
# 新式类
class MyClass(object):
pass
# python3中的类默认都是新式类
class MyClass: # 不加括号不写object也会被默认为此操作(object)
pass
"""
以后我们在定义类的时候,如果没有想要继承的父类
一般推荐一下写法
class MyClass(object):
pass
其目的是为了兼容python2
"""
派生类
子类中定义类与父类一摸一样的方法并且扩展了该功能>>>:派生
class Person(object):
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Teacher(Person):
def __init__(self, name, age, gender, salary):
# 使用super 专门用于子类调用父类的方法
super.__init__(name,age,gender)
# 自己在添加需要补充的数据
self.salary = salary
"""
当一个子类继承了一个父类,子类中需要使用了父类的功能。
但又觉得父类中的功能不够全面,又在其功能上做一些扩展,这就就叫做派生
"""
派生的实战演练
# 1.需求将下列字典序列化。
# time_dict = {'time1': datetime.datetime.today(),
# 'time2': datetime.date.today()}
# print(time_dict)
# {'time1': datetime.datetime(2022, 7, 28, 14, 33, 20, 481094),
# 'time2': datetime.date(2022, 7, 28)}
# res = json.dumps(time_dict) # 报错
"""
如果直接将其序列化会报错,报错如下:
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type datetime is not JSON serializable
首先下列是可以被序列化的类型,但我们的字典中的value值不在能够被序列化的类型中
是不能够直接被序列化的,能够被序列化的必须里里外外都符合下列条件才能够被序列化。
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
"""
# 解决方式1:手动将不符合数据类型要求的数据转成符合要求的
time_dict = {
't1': str(datetime.datetime.today()),
't2': str(datetime.date.today())
}
res = json.dumps(time_dict)
print(res)
# 解决方式2:利用派生方法
time_dict = {
't1': (datetime.datetime.today()),
't2': (datetime.date.today())
}
"""
class JSONEncoder:
pass
dumps(obj,cls=None):
if cls == None:
cls = JSONEncoder
return cls(...) # JSONEncoder()
查看JSONEncoder源码发现序列化报错是有default方法触发的
raise TypeError(f'Object of type {o.__class__.__name__} '
f'is not JSON serializable')
我们如果想要避免报错 那么肯定需要对default方法做修改(派生)
"""
# 定义一个类,继承父类json.JSONEncoder
class Myjsondecoder(json.JSONEncoder):
# 创建一个和父类同样的功能
def default(self, o):
# 做上面做出扩展,判断被序列化的对象是否为datetime类型
if isinstance(o, datetime.datetime):
# 如果是将对象转为字符串格式的时间
return o.strftime('%Y-%m-%d %H %M %S')
# 判断被序列化的对象是否为datetime类型
if isinstance(o, datetime.date):
# 如果是将对象转为字符串格式的时间
return o.strftime('%Y-%m-%d')
# 对象如果是可以序列化的类型,则不做任何操作,让其直接序列化即可。
return super().default(o)
#
res = json.dumps(time_dict, cls=Myjsondecoder)
print(res) # {"time1": "2022-07-28 14 56 34", "time2": "2022-07-28"}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号