上周知识回顾
列表的内置方法
列表在调用内置方法的时候不会产生新的值,而是修改自身。
1.统计列表中数据值的个数(len)
list1 = ['jason', 'kevin', 'tony', 'oscar', 'tom', ]
print(len(list1)) # 5
2.在列表尾部追加数据值(.append)
ist1 = ['jason', 'kevin', 'tony', 'oscar', 'tom', ]
list1.append("增加") # 只能在尾部追加元素 无论是一个元素还是一个整体里面有多个元素 都会当成一个整体在尾部追加进去。
print(list1) # ['jason', 'kevin', 'tony', 'oscar', 'tom', '增加']
3.任意位置插入数据值(insert)
# ist1 = ['jason', 'kevin', 'tony', 'oscar', 'tom', ]。
# list1.insert(2,'任意位置') # 可以在任意位置追加元素 无论是一个元素还是一个整体里面有多个元素 都会当成一个整体按照索引位置追加进去
# print(list1) # ['jason', 'kevin', '任意位置', 'tony', 'oscar', 'tom']
# list1.insert(1,["bbb",'aaa']) #
# print(list1) # ['jason', ['bbb', 'aaa'], 'kevin', 'tony', 'oscar', 'tom']
4.扩展列表,推荐使用(extend)
list1 = ['jason', 'kevin', 'tony', 'oscar', 'tom', ]
list2 = [11, 77, 33, 88, 55, 99, 44, 66, ]
# 4.1 俩个列表之间直接相加
print(list2+list1) # [11, 77, 33, 88, 55, 99, 44, 66, 'jason', 'kevin', 'tony', 'oscar', 'tom']
# 4.2 使用for循环方式加上.append 尾部单个追加进去
for i in list2:
list1.append(i)
print(list1) # ['jason', 'kevin', 'tony', 'oscar', 'tom', 11, 77, 33, 88, 55, 99, 44, 66]
# 4.3(推荐使用).extend
list1.extend(list2) # 尾部追加元素 整体也会单个追加进去相当于使用for
print(list1) # ['jason', 'kevin', 'tony', 'oscar', 'tom', 11, 77, 33, 88, 55, 99, 44, 66]
5.查询与修改数据(remove)、(pop)
print(list1)
print(list1[0])
list1[0] = '123'
#5.1 删除数据
# del 通用数据删除
del list1[0] # 直接删除删除那个数据通过索引即可
print(list1) # ['kevin', 'tony', 'oscar', 'tom']
# 5.2 指明道姓删除.remove
list1.remove('tom') # 括号里必须是有这个数据没有直接报错!!!
print(list1) # ['jason', 'kevin', 'tony', 'oscar']
# 5.3 先取出后删除.pop
list1.pop() # 根据索引删除,默认删除末尾的值
print(list1) # ['jason', 'kevin', 'tony', 'oscar']
list1.pop(9) # 超出列表索引直接报错!!!
print(list1) # ['jason', 'kevin', 'oscar']
6.统计某个数据值在列表中出现的次数(count)
list1 = ['jason', 'kevin', 'tony', 'oscar', 'tom', ]
list2 = [11, 77, 33, 88, 55, 99, 44, 66, ]
print(list1.count('tom')) # 1
7.查看列表中某个数据值在列表中的索引(index)
print(list2.index(77)) # 1 必须是列表里有的否则直接报错!!!
8.排序
8.1 升序 .sort
# list2.sort()
# print(list2) # [11, 33, 44, 55, 66, 77, 88, 99]
# 8.2 降序 .sort(reverse=True)
# list2.sort(reverse=True)
# print(list2) # [99, 88, 77, 66, 55, 44, 33, 11]
9.翻转
l1.reverse()# 将列表顺序翻转
10.比较运算
new_1 = [99,11]
new_2 = [11,22,33]
print(new_1>new_2)#True 判断new_1是否大于new_2根据俩个列表之间索引所对应的值来做比较
# 不同数据类型之间默认不能直接做比较
# 字符串中纯字母的是跟据ASCII字符编码表对应的关系来做比较
# 列如A-Z 65-90
# a-z 97-122
可变不可变类型
字符串调用内置方法不是改变本身而是产生了新值而列表调用内置方法是改变自身。
1.可变类型
当一个数据类型它的值改变内存不变说明改变的是自身它是可变类型
不可变类型
当一个数据值改变内存地址一定变了的时候说明它是从本身又产生了一个新值它是不可变类型一旦改变了就不是它本身了相当于又建立了一个新值
元组内置方法
类型转换 能够被for循环的数据类型都可以转换成元组
还有当元组内只有一个数据值的时候一定要在括号内数据值后面加上一个逗号这样能表明它是一给元组类型不然系统会默认放什么数据类型就当作什么数据类型
# t1 = (11, 22, 33, 44, 55, 66)
# 1.索引相关操作
# 2.统计元组内数据值的个数
# print(len(t1))
# 3.查与改
# print(t1[0]) # 可以查
# t1[0] = 222 # 不可以改
"""元组的索引不能改变绑定的地址"""
# t1 = (11, 22, 33, [11, 22])
# t1[-1].append(33)
# print(t1) # (11, 22, 33, [11, 22,
字典的内置方法
类型转换
print(dict([('name','jason')('age',18)]))
print(dict(name='jason','age'=18))
#第一种是以列表套元组的方式
# 第二种是以变量名赋值操作直接定义
#字典一般很少涉及类型转换都是直接定义使用
dict1 = {
'age':18
'name':'jason'
'hobby':['rade','run']
}
#字典的k是对v的描述信息一般都是字符串因为字符串 k其实只要是不可变类型都行一般都是用字符串具有对v极强的描述性
#字典内k:v键值对是无序的 取值是根据k取值的
# 取值操作
# print(info['username']) # 不推荐使用 键不存在会直接报错
# print(info['xxx']) # 不推荐使用 键不存在会直接报错
# print(info.get('username')) # jason
# print(info.get('xxx')) # None
# print(info.get('username', '键不存在返回的值 默认返回None')) # jason
# print(info.get('xxx', '键不存在返回的值 默认返回None')) # 键不存在返回的值 默认返回None
# print(info.get('xxx', 123)) # 123
# print(info.get('xxx')) # None
# 3.统计字典中键值对的个数
# print(len(info))
# 4.修改数据
# info['username'] = 'jasonNB' 键存在则是修改
# print(info)
# 5.新增数据
# info['salary'] = 6 键不存在则是新增
# print(info) # {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'salary': 6}
# 6.删除数据
# 方式1
# del info['username']
# print(info)
# 方式2
# res = info.pop('username')
# print(info, res)
# 方式3
# info.popitem() # 随机删除
# print(info)
# 7.快速获取键 值 键值对数据
# print(info.keys()) # 获取字典所有的k值 结果当成是列表即可dict_keys(['username', 'pwd', 'hobby'])
# print(info.values()) # 获取字典所有的v值 结果当成是列表即可dict_values(['jason', 123, ['read', 'run']])
# print(info.items()) # 获取字典kv键值对数据 组织成列表套元组dict_items([('username', 'jason'), ('pwd', 123), ('hobby', ['read', 'run'])])
# 8.修改字典数据 键存在则是修改 键不存在则是新增
# info.update({'username':'jason123'})
# print(info)
# info.update({'xxx':'jason123'})
# print(info)
# 9.快速构造字典 给的值默认情况下所有的键都用一个
# res = dict.fromkeys([1, 2, 3], None)
# print(res)
# new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) # {'name': [], 'pwd': [], 'hobby': []}
# new_dict['name'] = []
# new_dict['name'].append(123)
# new_dict['pwd'].append(123)
# new_dict['hobby'].append('read')
# print(new_dict)
# res = dict.fromkeys([1, 2, 3], 234234234234234234234)
# print(id(res[1]))
# print(id(res[2]))
# print(id(res[3]))
# 10.键存在则获取键对应的值 键不存在则设置 并返回设置的新值
res = info.setdefault('username', 'jasonNB')
print(res, info)
res1 = info.setdefault('xxx', 'jasonNB')
print(res1, info)
集合内置方法
set()
类型转换
支持for循环的 并且数据必须是不可变类型
1.定义空集合需要使用关键字才可以
2.集合内数据必须是不可变类型(整型 浮点型 字符串 元组 布尔值)
'''去重'''
# s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}
# print(s1) # {1, 2, 3, 4, 5, 12}
#
# l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']
# s2 = set(l1)
# l1 = list(s2)
# print(l1)
'''关系运算'''
# print({1,2,[1,2,3]})
# print({1,2,{'name':'jason'}})
# s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}
# print(s1) # {1, 2, 3, 4, 5, 12}
#
# l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']
# s2 = set(l1)
# l1 = list(s2)
# print(l1)
# 模拟两个人的好友集合
f1 = {'jason', 'tony', 'oscar', 'jerry'}
f2 = {'kevin', 'jerry', 'jason', 'lili'}
# 1.求f1和f2的共同好友
# print(f1 & f2) # {'jason', 'jerry'}
# 2.求f1/f2独有好友
# print(f1 - f2) # {'oscar', 'tony'}
# print(f2 - f1) # {'lili', 'kevin'}
# 3.求f1和f2所有的好友
# print(f1 | f2) # {'jason', 'kevin', 'lili', 'oscar', 'jerry', 'tony'}
# 4.求f1和f2各自独有的好友(排除共同好友)
# print(f1 ^ f2) # {'kevin', 'lili', 'tony', 'oscar'}
# 5.父集 子集
# s1 = {1, 2, 3, 4, 5, 6, 7}
# s2 = {3, 2, 1}
# print(s1 > s2) # s1是否是s2的父集 s2是不是s1的子集
# print(s1 < s2)
垃圾回收机制
垃圾指的是我们在开发程序中所产生的一些没有用的数据
这些没有用的数据需要我们不定时的去清理为了便于我们不在这些小事上浪费太多精力
就有了我们所说的垃圾回收机制
垃圾回收机制分为三种
1.引用计数
当数据身上的引用计数不为0时表示这个数据还有用 不会被回收。
当数据身上的引用计数为0时表示这个数据就是垃圾数据会被垃圾回收机制回收
X = 10 数据值10的当前引用计数为1
Y= X 数据值10 的当前引用计数为2
del X 数据值10身上的引用计数为1
del Y 当数据值10 身上没有任何绑定关系它的的引用计数为0 就会被当垃圾回收掉
引用计数还时有缺陷的 当俩个数据互相循环引用的时候引用计数就不能实现清除数据了
这个时候就需要用到这个标记清除了。
2.标记清除
专门解决循环引用上的问题,将内存张程序所产生的数据值全部检查一遍
是否存在循环引用打上标记之后一次清楚。
循环引用
l1 = [111,] 当前引用计数为1
l2 = [333,] 当前引用计数为1
l1.append(l2) 当前引用计数为2
l2.append(l1) 当前引用计数为2
del l1 解除变量名l1与列表的绑定关系 列表引用计数为1
del l2 解除变量名l2与列表的绑定关系 列表引用计数为1
这个时候我们用不到它,它身上的引用计数为1 也清除不了它这个时候就需要用到标记清除了
3.分代回收
当标记清除每隔一段时间就需要将所有的数据排查一遍,资源消耗过大为了减轻垃圾回收机制的资源损耗就开发这分代回收
字符编码简介
- 只有文本文件才有字符编码的概念
- 计算机内部存取数据的本质是二进制就是一些0101的数字
- 为了能让我们在使用计算机的时候可以显示各国的文字而不是一串我们看不懂的二进制
- 人类就研发了一种字符能够与计算机的0101相互转换的关系。
- 转换关系也不能够随便改应该有统一的方式于是就有了字符编码表
- 记录了人类的字符与计算机数字的对应关系
字符编码发展史
-
计算机时美国人发明的,美国人用的时英文字母。美国人需要让计算机识别英文字符
就研发出了对应的ASCII码表记录了英文字母与数字的对应关系。
英文所有的字符加起来不超过127个(2的七次方)但是美国人考虑到后续可能
还会需要增加新的字符所以加了一位以备将来能够用到。(2的八次方)
1bytes来储存字符
A-Z 对应 65-90
a-z 对应 97-122
此时呢计算机不能识别其它文字只能识别英文
-
后续各个国家也用到了计算机但是计算机目前只有一种ASCII码中的英文字符对应着计算机数字的转换关系其他国家也相继研发了各国独有的编码表与计算机数字相对应。
中国
需要让计算机识别中文开发了一套中文的编码表
GBK码:内部记录了中文字符、英文字符与数字的对应关系
中文比较多我们就预算2bytes起步用于储存中文(遇到生僻字使用更多字节)
在2个bytes基础上预备1个bytes以备后续增加
韩国
需要让计算机识别韩文 需要开发一套韩文的编码表
Euc_kr码:内部记录了韩文字符、英文字符与数字的对应关系日本
需要让计算机识别日文 需要开发一套日文的编码表
shift_JIS码:内部记录了日文字符、英文字符与数字的对应关系此时各国的计算机都只识别各自国家的文字无法直接交互,如果出现交互就会出现乱码的情况
-
为了能够让各个国家的计算机能够交互就有人开发出了一种万国码
unicode:万国码 ,兼容万国字符
它的需求时所有字符都需要2bytes起步来储存
这样不同国家的字符不一样根据2bytes可能会拖慢计算机的效率
为了解决这样的问题utf家族针对unicode的优化版》》》utf8
英文还是采用1bytes
其他统一采用3bytes
内存使用unicode 硬盘使用utf8
字符编码实操
字符编码只有字符串才可以参与编码解码,其它数据类型需要先转换成字符串才能参与。4
-
解决乱码的措施
当初什么以什么编码村的就以什么编码解或者一个一个试
-
编码与解码
编码
将人类的字符按照指定的编码转换成计算机可以识别的数字
解码
将计算机能够识别的数字按照人类指定的编码转换成人类可以读懂的字符
# 编码 s1 = 'today这是一串字符' res = s1.encode('gbk') print(res,type(res)) # b'today\xd5\xe2\xca\xc7\xd2\xbb\xb4\xae\xd7\xd6\xb7\xfb' <class 'bytes'> # 在python中bytes类型的数据都可以看成是二进制数据 #解码 res.decode('gbk') print(res,type(res)) # b'today\xd5\xe2\xca\xc7\xd2\xbb\xb4\xae\xd7\xd6\xb7\xfb' <class 'bytes' -
解释器层面
python2默认的编码是ASCII码
# 使用的时候 1. 文件头 # coding:utf8 2.定义字符串需要在字符串前面加上u为什么要这么做
因为python2实在字符编码之前研发出来的只能做出补救措施
后续python3默认的编码是utf8码
文件操作简介
-
文件操作
通过编写代码自动操作文件的读写
-
什么是文件
双击文件图标是从硬盘加载数据到内存
写文件之后保存其实就是将内存中的数据刷大硬盘
文件其实就是操作系统暴漏给用户操作计算机硬盘的快捷方式之一
-
如何代码操作文件
open(文件的路径,读写模式,字符编码)
方式1
f= open()
f.close
方式2
with open()as 变量名:
子代码结束后自动调用close()方法
-
针对文件路径需要注意,可能存在特殊含义(字母与撬棍的组合)
在字符串的前面加字母r即可取消特殊含义。
文件的简介
什么是文件
文件其实是操作系统暴漏给用户操作计算机硬盘的快捷方式。
文件的操作
通过编写代码自动操作文件的读写模式。
使用关键字open()括号内部写入,需要打开文件的路径字符串+r默认读取模式+参数指定字符编码。open前面用个变量名接收。
俩种方式
# 方式1:
f = open('a.txt','r',encoding='utf8')
f.read() # 读取文件中所有内容
f.close # 关闭文件
# 方式2:
with open('a.txt','r',encoding='utf8') as f:
f.read()
# 方式2不需要执行关闭文件步骤with语法帮助你来管理。
#当路径中有特殊符号的时候可能造成转义我们需要在路径字符串前面加r来取消特殊含义。
# 列如:
with open(r'a.txt','r',encoding='utf8')as f;
f.read()
# 在路径前面加个r俩种方式都可以用。
文件的操作模式
with语法支持一次性打开多个文件
with open(r'a.txt','rt',encoding='uft8')as f,with open(r'b.txt','rt',encoding='uft8')as f
f.read
# 在没有想好子代码改写什么的时候可以使用 pass 补全python语法 pass不会执行操作只是简单的占位也不会报错!
"""通常情况下英语单词的结尾如果加上了able表示具备该单词描述的能力
readable 具备读取内容的能力
writable 具备填写内容的能力"""
文件操作的俩种模式
t模式(文本模式) b模式(二进制模式)
-
t 文本模式
文件操作的默认模式
rt、wt、at、后面的t可以不写系统默认t模式,该模式只能操作文本文件,必须指定encoding=字符编码,读写都是以字符串为单位的。
r只读模式,使用该模式打开的文件只具备读取的能力不能进行写入操作
# r模式情况下文件路径必须是存在的如果不存在直接报错!!! with open(r'a.txt','r',encoding='uft8')as f: f.read() # read读取功能w只写模式,使用该模式打开的文件只具备写入内容的功能不具备其它操作,默认模式下该写入的内容必须是字符串形式。
with open(r'a.txt','w',encoding='utf8')as f1: f.write() # 括号内写入内容 字符串格式 """ 该模式下文件路径如果不存在则在你当前目录下新创文件 如果填入存在的文件则直接覆盖该文件内容也会清空。 """a尾部追加模式,使用该模式操作文件只具备尾部写入功能不具备其它能力。
with open(r'a.txt','a',encoding='utf8')as f3: f3.write() """ 改模式下的文件路径如果不存在则会新增存在的话则会在当前文件里尾部写入 一行一行的形式添加不做换行模式直到一直写满一行才进行下一行 """ -
b 二进制模式
可以操作所有类型的模式
rb、wb、ab。这种模式必须自己指定不能省略要全部写上
该模式下能操作所有类型的文件不需要指定encoding参数,读写都是以bytes为单位的。
# rb 模式 使用该模式打开的文件只能读取内容 不具备其他操作 #r模式情况下文件路径如果不存在则直接报错 with open(r'a.txt','r',encoding='uft8')as f: f.read.() # wb 模式 使用该模式打开的文件只能写入内容 不具备其他操作。 # 该模式下文件路径不存在则在你目前目录下新创文件 # 如果填入存在的文件则直接覆盖改文件内容也会清空 with open(r'a.txt','rb',encoding='uft8')as f: f.write.() # ab 模式 使用该模式操作文件只具备尾部写入能力不具备其他能力 # 改模式下的文件路径如果不存在则会新增存在的话则会在当前文件里尾部写入 # 一行一行的形式添加不做换行模式直到一直写满一行才进行下一行 with open(r'a.txt','at',encoding='utf8')as f: f.write()
文件的诸多操作方法
raed()一次性读取文件内容并且光标会停留在末尾继续读则为空
当文件数据较大时不推荐一次性读取 可以使用for循环
for line in f:
print(line)
# 文件对象支持for循环
readlines() 按照行的方式读取所有内容并组织成列表返回
# readable ()判断当前文件是否可读
# weitable ()判断当前文件是否可写
# write() 填写文件内容
# writelines()支持填写容器类型(内部可以存放多个数据值的数据类型)多个数据值
# flush()将内存中的文件数据立即刷到硬盘相当于主动按住CTRL+s快捷键
文件的光标移动
- read()方法
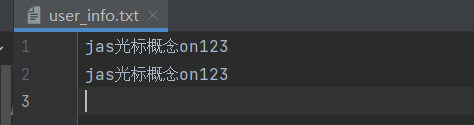
with open(r'user_info.txt', 'r', encoding='utf8')as write1:
# 1.自己定义读取几个字符的文件内容
# 这里是以字符为单位的。
# 在read括号里输入想要读取的字符的数量
a = write1.read(3)
print(a) # jas
# 这个时候的光标在第三个字符位置停留接着读就等于从第三个字符按照指定数量读取下去
b = write1.read(6)
print(b) # 光标概念on
-
查看光标 tell功能
tell功能可以用来查看此时光标的位置在这个文件的第几个字节处这里数量是以字节为单位的。
with open(r'user_info.txt', 'r', encoding='utf8')as write1: print(write1.tell()) -
代码控制光标移动
seek功能
seek(offset,whence)
offset 控制光标移动的位移量(以字节为单位)
whence是seek功能的模式(以字节为单位)
0 基于文件开头来控制光标跳过多少个字节来读取文件剩下内容。
1 基于光标当前所在位置跳过多少个字节来读取剩下文件的内容
2 基于文件的末尾来控制光标跳过多少字节来读取文件内容
1和2只能在二进制模式下使用 0 则无所谓没有要求。
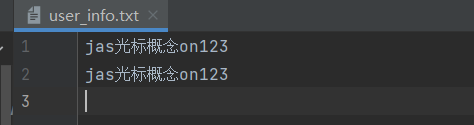
# 0 模式 示例: # 0 基于文件开头跳过多少个字节来读取文件剩下内容。 with open(r'user_info.txt', 'r', encoding='utf8')as write1: a = write1.read(2) # ja 读取文件中的二个字符 print(a) # ja 打印读取的内容 print(write1.tell()) # 3 查看光标此时所处的位置 write1.seek(6, 0) # 可以理解为第一位相当于控制光标从哪里开始的位置 print(write1.read()) # 概念on123 # 这个时候读取出来的就是定义好光标位置之后的字符了 print(write1.tell()) #44 此时读完光标是在第44个字符也就是文件末尾 # 1 模式 示例: with open(r'user_info.txt', 'rb')as write1: # 表示6个字节一个英文一个字节一个中文3个字节# a = write1.read(6) print(a) # b'jas\xe5\x85\x89' # 我们的文件是字符模式如果需要打印原来的字符还需要做一下编码转换的操作 print(a.decode('utf8')) # jas光 # 此时我们的光标停留在光的后面 write1.seek(6,1) # 此操作相当于在当前光标停留处在跳过六个字节来读取剩余的文件内容 print(write1.read()) # b'\xe5\xbf\xb5on123\r\njas\xe5\x85\x89\xe6\xa0\x87\xe6\xa6\x82\xe5\xbf\xb5on123\r\n' # 也是需要做转换的 print(write1.read().decode('utf8')) # 念on123 # jas光标概念on123 # 2 模式 示例: with open(r'user_info.txt', 'rb') as write1: write1.seek(-10,2) # # 念on123 从文件的末尾取10个字节的二进制其中换行符占了2个字节 print(write1.read().decode('utf8')) write1.seek(-4,2) # 23 print(write1.read().decode('utf8')) -
2
文件的数据修改
机械硬盘储存数据的原理
1.数据的修改 其实是把修改后的数据直接覆盖掉原本的数据其实就是覆盖写
2.数据的删除 其实就是把这个数据从占有态改为自由态等着其他数据来覆盖它。
修改数据的方式
-
覆盖写 先读取文件内容到内存在内存中完成修改操作之后
保存下来在用W模式将其覆盖写入with open(r'demo.txt','r',encoding='utf8') as f: data = f.read() new_data = data.replace('DSB','NB') with open(r'demo.txt','w',encoding='utf8') as f1: f1.write(new_data) # 优点:硬盘只占用一块空间 # 缺点:数据量较大的时候会造成内存溢出 -
重命名
先读取文件内容到内存在内存中完成修改
保存到另外一个文件中
再将原文件删除将新文件重新命名为原文件。import os with open('demo.txt', 'r', encoding='utf8') as read_f, \ open('.demo.txt.swap', 'w', encoding='utf8') as wrife_f: for line in read_f: wrife_f.write(line.replace('NB', 'SB')) os.remove('demo.txt') # 删除文件 os.rename('.demo.txt.swap', 'demo.txt') # 重命名文件 #优点:不会造成内存溢出 # 缺点:可能会在短暂的时间内需要占用硬盘俩个地方的空间也可能直接再内存中操作不会刷到硬盘。
函数的简介
1.循环
函数是带有名字的代码块,用于完成具体的工作,
有时候程序中需要多次执行同一种操作,如果每次需要的时候都写同样的代码
程序就会显得很长又很繁琐,可读性也差。 那这种情况就可以用函数将这一项任务写成函数体
在需要的时候直接调用函数即可, 这样以来解决了代码的重复性和可读性
l1 = [1, 2, 3, 4, 5, 6]
print(len(l1)) # 不允许使用len 完成列表数据值个数统计
# 自定义统计方法
def my_len():
value_count = 0
for i in l1:
value_count += 1
print(value_count)
"""
我们自己瞎写的缺陷
1.只能统计某个固定的数据类型里面的数据值个数
2.没有产生新的值(返回值)
"""
"""
1.循环
在相同的位置反复执行相同的代码
2.函数
在不同的位置反复执行相同的代码
"""
print(len(l1))
print(my_len())
函数的介绍
函数的本质
函数的本质就是一种工具
提前定义好可以反复使用
函数的语法结构
关键字def 函数名my_len 括号() 冒号:
"""函数注释 对这个函数功能的解释"""
函数体代码
关键字return
def my_len():
pass
return
# pass 表示补全语法结构不做任何操作!!
- 关键字def>>>: 定义函数必须要有它。
- 函数名my_len >>>:相当于变量名 而且在命名的时候尽量做到见名知意
- 括号()>>>:这个括号必须要有。它里面可以写入参数(个数不限)参数也可以不写
- 冒号:>>>: 这个必须要写。同时带有冒号的代码也表示这段代码是可以拥有子代码的。
- 注释>>>: 写上对这个函数的功能及用法可以写简单一点也可以写详细一点
- 函数体代码:你的函数能不能运行或者功能强不强大都取决于它
- 返回值return>>>:控制函数的返回值它可以写也可以不写return后面加上什么就返回什么多个数据是以元组的方式返回
函数的定义与调用
-
函数必须先定义后调用
定义函数的代码必须要在调用函数的代码之前先运行。
相当于你的工具必须要先造出来才能使用。
-
定义函数需使用关键字def,调用函数使用函数名加括号,
括号内的参数根据定义函数的情况来考虑添加或不添加。
-
函数在定义的时候只检测函数体代码语法不会执行函数体代码
只有在调用阶段使用函数名调用才会执行函数体代码。
-
函数名是什么?
函数名相当于变量名与变量名不同的是
它绑定的是一块内存地址里面存放的是函数体代码,要想运行就需要调用函数名加括号。
-
定义阶段除外函数名加括号执行优先级最高。
函数的分类
- 内置函数
python中已经设定封装好的函数,可以根据关键名直接调用
内置函数可以调用数据类型的内置函数需要根据数据类型点的方式才可以调用
相当于数据类型独有的一些内置方法
-
自定义函数
-
空函数
函数体代码使用pass顶替暂时没有功能
主要用于前期的项目搭建构造功能
def my_def(): pass -
无参函数
函数定义阶段括号内没有填写参数
无参函数直接函数名加括号即可直接调用
def my_def(): print('hello word') -
有参函数
函数定义阶段括好内填写参数
有参函数调用时需要函数名加括号并给数据值
def my_def(a,b): print('hello word')
-
函数的返回值
使用关键字return
返回值就是调用函数之后产生的结果可有可无
获取函数返回值的方式的固定的变量名 = 函数()
有则获取返回值 没有默认返回None
-
函数体代码没有return关键字
示例:
def func(): print("12312") res = func() # 12331 res用于接收返回值 print(res) # None # 默认返回None -
函数体代码有return关键字
return 后面不写 是返回None
示例:
def func(): print('1234') return res = func() # 1234 print(res) # None -
函数体代码有return关键字后面加数据值
return后面写什么返回的就是什么
如果是数据值就返回数据值如果是变量则返回变量所对应的数据值
示例:
def func(): print('123') return 666 res = func() # 123 print(res) # 666 -
函数体代码有return关键字并且后面跟了很多数据值逗号隔开
默认情况下自动组成元组返回
示例:
def func(): print('123') return 1,2,3,4 res = func() # 123 print(res) # (1, 2, 3, 4) -
函数体代码遇到return关键字会立刻结束函数体代码的运行.
示例:
def func(): print('123') return 1,2,3,4 print('456') # 这个步骤不会被执行到 func() # 123 # 相当于for循环中的break结束。
函数的参数
函数的参数分为俩大类
-
形式参数
函数下定义阶段括号内可填入的参数简称为“形参”
-
实际参数1
函数在调用阶段括号内可填入的参数简称为”实参“
-
形参与实参的关系
形参相当于变量名,实参相当于数据值。
在函数调用阶段形参会临时与实参进行绑定函数运行结束后立即解除绑定。
位置参数
-
位置形参
在函数定义阶段括号内从左往右依次填写的变量名称之为位置形参
-
位置实参
在函数调用阶段函数名括号内从左往右的依次填写的数据值称之为位置实参
实参可以时数据值也可以时绑定了数据值的变量名
给位置形参传值时个数必须一致,过多过少都不行。
关键字参数
在函数调用阶段括号内什么等于什么的形式传值称关键字传值。
-
等于指定给形参传值,这样打破了位置传值的限制
-
位置实参必须在关键字实参的前面
-
同以形参在一次调用中只能传一次
无论是形参还是实参,都遵循简单的在前复杂的在后面的规律。
示例:
def func(a,b): print(a,b) func(1,2) # 1,2 func(b=1,a=2) # 2 1 func(b=1,2) # 报错!!! func(2,b=1) # 2 1 func(666,a=1) # 报错!!!
默认值形参
在函数定义的阶段括号内以什么等于什么的形式填写的形参称之为默认形参
示例:
def register(name, age, gender='male'):
print(f"""
-------------info-----------
name:{name}
age:{age}
gender:{gender}
----------------------------
""")
register('jason',18) # 不填写则默认使用形参的值
register('oscar',28) # 不填写则默认使用形参的值
register('lili',18,'female') # 填写则根据实参中的数据
在函数定义阶段就给形参绑定值后续调用阶段如果不写可以不传
自动默认使用定义之前绑定的值.调用阶段不传值就是使用默认的
如果有传值则使用传入的值还需要遵循前面结的规律(简单填在左边,复杂填在右边)
可变长参数
可以打破形参与实参的限制任意传值。
示例1:
*号在形参中的作用
接收多余的位置参数并组织成元组的形式赋值给*后面的变量名
def func(*x): # 阔号内输入星号后面跟上变量名
print(x)
func(1,2,3,4)
示例2:
**在形参的作用
接收多余的关键字参数并组成字典的形式赋值给**后面的变量名
def func(**y):
print(y)
func() # {} 返回空字典
func(name='jason') # {'name': 'jason'}
func(name='jason',age=18) # {'name': 'jason', 'age': 18}
func(name='jason',age=18,hobby='read') # {'name': 'jason', 'age': 18, 'hobby': 'read'}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号