MySQL-索引分类及使用索引
1、什么是索引?
索引:存储引擎用于快速找到记录的一种数据结构,默认使用B-Tree索引。索引是存储引擎层中实现。简单理解为:排好序的快速查找数据结构
索引的目的:提高数据查询的效率,优化查询性能,就像书的目录一样。
优势:提高检索效率,降低IO成本;排好序的表,降低CPU的消耗
劣势:索引实际也是一张表,该表保存了主键与索引字段,并指向实体表的记录,占用空间;降低更新表的速度(改数据表本身,也需要修改索引);花时间研究建立最优秀的索引
索引的常见模型:哈希表、有序数组、搜索树。
InnoDB的索引模型:在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB使用的是B+Tree 索引模型,所以数据都是存储在B+Tree树中的。
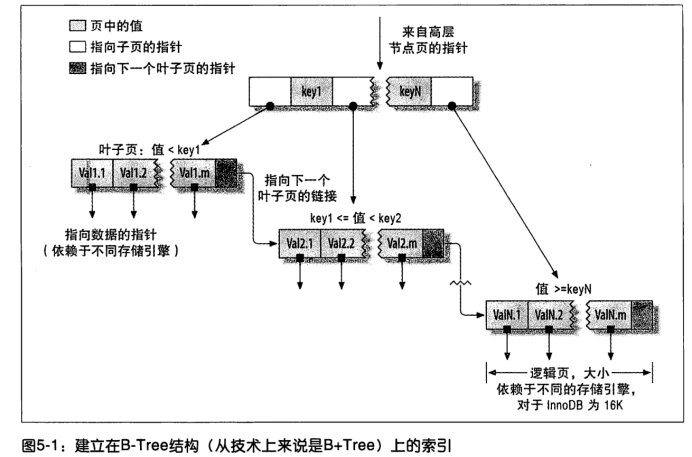
B-Tree索引通常意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同。
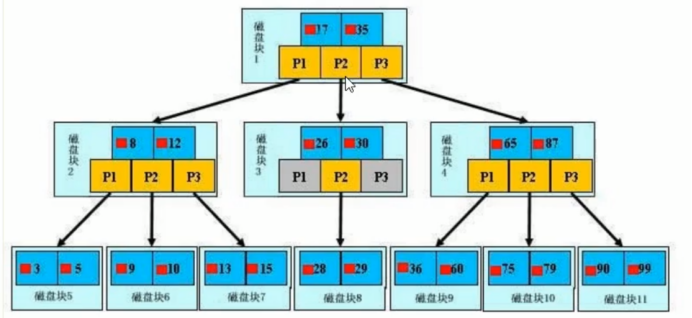
检索原理:
【如图】
一颗B+树,主要分为3个基本模块:磁盘块、数据项、指针。
真实的数据存在于叶子节点,非叶子节点不存储真实的数据,只存储指引搜索方向的数据项。
【查找过程】
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分法查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相对磁盘),可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO.
Ps:3层的B+树可以表示上百万的数据。
前提:假设一张表,有10W条数据,其中有一条数据是nickname=‘css’,查询这条数据sql:select * from table_award where nickname='css'
没有索引:mysql全表扫描及扫描10W条数据找这条数据。
有索引: 建立nickname字段索引,mysql只需要扫描这条nickname='css'的数据
1.1 索引分类
索引主要包含5个部分:主索引、唯一索引、普通索引、全文索引、复合索引、单字段索引。其中主索引指主键自动的为主索引。
1.2 索引语法
建立索引:
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON tbl_name (col_name [(length)] [ASC | DESC] , …..);
ALTER TABLE table_name ADD INDEX [index_name] (index_col_name,...)
删除索引
DROP INDEX index_name ON tbl_name;
ALTER TABLE table_name DROP INDEX index_name;
查询索引:
SHOW INDEX FROM table_name;
SHOW KEYS FROM table_name;
DESC table_Name;
索引的分类、语法用文字的形式看起来已经麻木了,可以参考图文:索引分类为5个部分,索引操作语法3种(新增、删除、查询)。

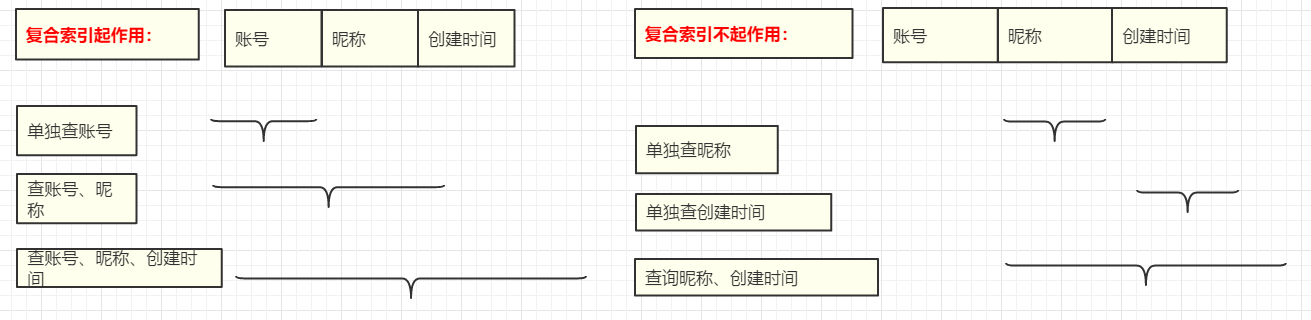
1.3 使用索引
提高性能优化的索引:覆盖索引、最左前缀索引、索引下推。
覆盖索引:可以减少树的搜索次数,显著提高查询性能。
使用索引,查看匹配度, 查询要使用索引最重要的条件是查询条件中需要使用索引。
MATCH (col1,col2,...) AGAINST (expr).
Ex:select match(col_name) against(‘poverty’)from news;
下列几种情况下有可能使用到索引:
1,对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。
2,对于使用like的查询,后面如果是常量并且只有%不在第一个字符,索引才可能被使用。
3,如果使用column_name is null将使用索引
下列几种情况不适合建立索引:
1,表记录太小
2,经常增删改的表
3,数据重复且分布平均的表字段
4,如果条件中有or,即使其中有条件有索引也不会使用。
5,对于多列索引,不是使用的第一部分,则不会使用索引。
6,like查询是以%开头
7,如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。
8,如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
下列几种情况适合添加索引:
1,主键自动建立唯一索引
2,频繁作为查询条件的字段应该建立索引
3,查询中与其他表关联的字段,外键关系建立索引
4,频繁更新的字段不适合创建索引-更新表的同时,同步更新索引
5,Where条件里用不到的字段不创建索引
6,单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
7,查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
8,查询中统计或者分组字段
索引失效:
1、全值匹配
2、最佳左前缀法则
3、不在索引列上做任何操作
4、存储引擎不能使用索引中范围条件右边的列
5、尽量使用覆盖索引,减少select *
6、mysql在使用不等于的时候无法使用索引会导致全表索引
7、Is null,is not null也无法使用索引
8、Like以通配符开头(‘%abc...’)mysql索引失效会变成全表扫描的操作
9、字符串不加单引号索引失效少用or,用它来连接时会索引失效
1.4 查看索引的使用情况
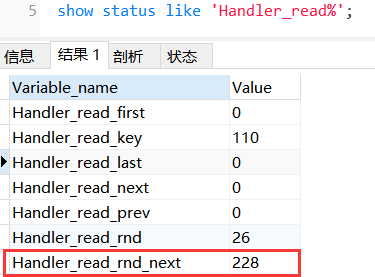
查看索引的使用情况
show status like ‘Handler_read%’;
大家可以注意:
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询低效。这是因为我们前面没有加索引的时候,做过多次查询的原因.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号