
服务不可用排查思路
前言
上周四,服务器突然挂了。SSH都连接不上,日常的小程序后台直接down掉,小程序每日大概3K左右访问量。于是乎就开启了,排查之后。
排查阶段
什么先别说,先把服务恢复再说。重启阿里云服务器,SSH连接。开启nginx,redis,mysql,java服务。一系列操作,先把服务先启动了。
服务器安装了CloudMonitor(云监控),非常建议安装,对排查问题,查看CPU,内存非常的有帮助。
查看CPU,内存如下:



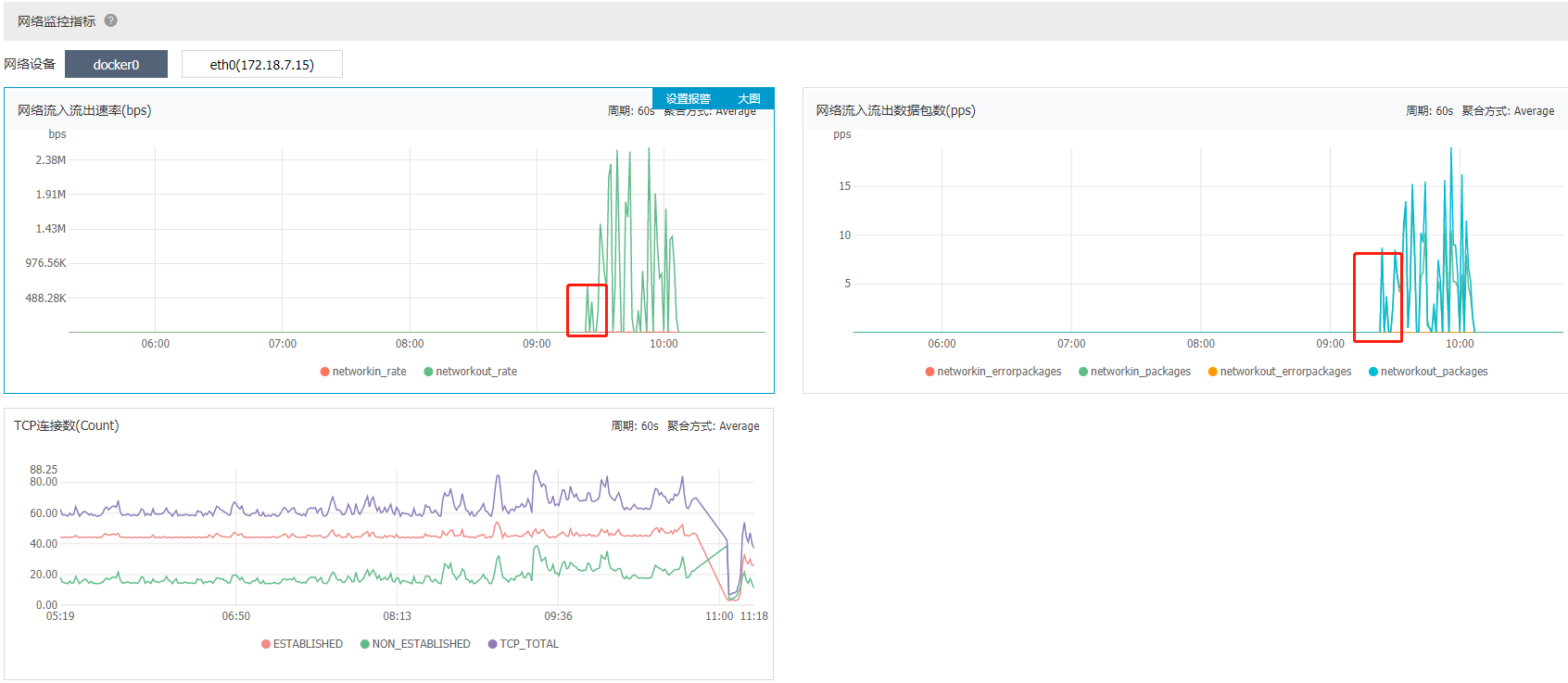
我们先从最后一幅图看起,可以明显的看到9.30左右的时候,网络的流入流出速率立马飙升了。因此初步可以断定,CPU,内存飙升,可能跟网络有关。
9.30分左右的时候,服务器大概运行了以下几个跟网络有关的应用:
- mysql
- redis
- ngxin
- java服务(osc,sign等等)
- docker
很明显前三个是日常的应用,基本上不会有什么问题,首先排除。剩下的就是Java相关的服务和Docker了。
第一个想法是不是Java的访问量突然增大,然后服务器资源不够,然后把服务给打死了。然后去看了Java服务的相关日志,发觉9.30分并无异常,跟平常的访问流量无多大变化。故排除。
那么就是docker服务了。
docker我每天会有一个定时任务,用来刷题的。基本上每天九点多就会start,然后11点stop掉。遂查看docker日志:

可以明显的看到9.23分的时候。docker开启,开始刷题。可以断定就是docker的锅了。此时把docker kill掉,定时任务关掉,至此没在出现过问题了。
问题在现
为确定是否是docker的问题,于是过了几天,我又开启了docker的定时任务。查看服务器资源如下:
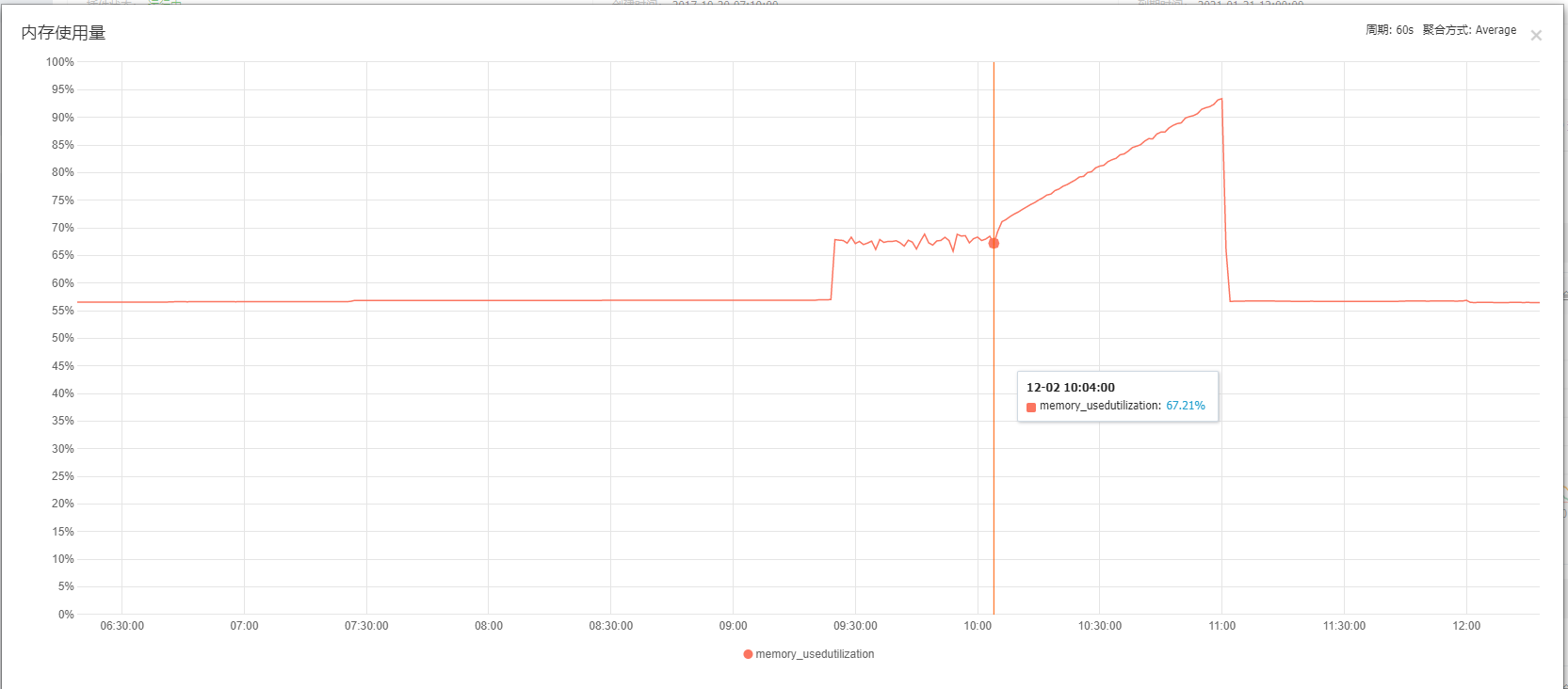
问题重新复现出来了,很明显,这就是docker的锅。至于为什么开启docker的这个服务,内存就飙升,CPU飙升,导致服务器直接down掉。这个原因就要问这个image的作者了。
个人初步猜想,内存泄露了。
我们可以仔细观察下内存的图片。约9.30的时候docker服务启动,内存上升至70%左右,这都是非常的合理的。
在大概10点左右的时候,任务跑完了(通过查看日志)。但服务并没有stop。
从10点开始,内存一路飙升,飙升至95%,最终我kill掉了docker,内存回归正常。
这是很明显的内存泄露,因为此镜像为私人镜像,并且不开源,具体代码无从查起,也是没有办法的了。
不过已向改仓库提了issue。https://github.com/fuck-xuexiqiangguo/docker/issues/20
总结
从这次服务器挂掉,有以下几点感想。
- 日志很重要,无论是什么服务,一定要记得把日志排在首位
- 服务器一定要有监控,并且要有监控预警,超过多少,发短信,电话通知。
- 问题思路排查要有理有据,一步一步来,不能瞎子抓阄似的。
- 服务挂掉,首先要恢复服务,比如重启等操作
这次服务器宕机并没有任何影响,毕竟没啥用户,不过感觉对问题的排查更加深刻了。业务推动技术,这点是毋庸置疑的了。
而且业务上线后,慢慢也会出现很多问题,一个一个解决,也能学习到很多东西。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号