部署和使用kibana
背景
上一篇介绍了在阿里云上部署ES(www.cnblogs.com/wenBlog/p/7451696.html),本文将主要介绍ELK的可视化工具Kibana的部署和使用。主要分为三个步骤来实现最终呈现:
1.导入数据到ES;
2.部署kibana并完成配置;
3.使用kibana生成可视化数据。
废话不多说下面直接上步骤了。
部署
1.下载配置kibana
--下载kibana
wget wget https://artifacts.elastic.co/downloads/kibana/kibana-5.1.2-linux-x86_64.tar.gz
--解压
tar xzvf kibana-5.1.2-linux-x86_64.tar.gz
--配置
在conf/kibana.yml文件中进行配置

--将内网IP地址配置到这里,如图。
--启动kibana
bin/kibana
2.导入数据到ES这里写一个版本注意jdbc的版本
--下载 elasticsearch-jdbc 这里测试 wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.4.1/elasticsearch-jdbc-2.3.4.1-dist.zip --解压 elasticsearch-jdbc unzip elasticsearch-jdbc-2.3.4.1-dist.zip
--创建ES索引
curl -XPUT IP地址/mysql --新建一个import_mysql.sh文件,注意json里面配置mysql的地址、账号、密码、语句、ES的IP、端口等
Java -cp "${lib}/*" -Dlog4j.configurationFile=${bin}/log4j2.xml org.xbib.tools.Runner org.xbib.tools.JDBCImporter jdbc_mysql.json
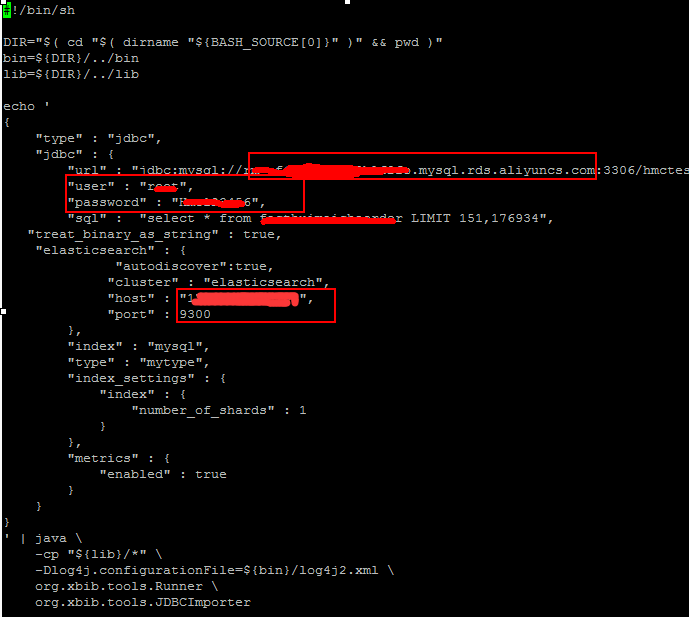
--执行导入 ./import_mysql.sh
使用kibana
1.启动完kibana后,访问ip(外网地址):5601即可看到类似于下面的界面。初次使用时,会让你配置一个默认的index,也就是你至少需要关联一个ES里的Index,可以使用pattern正则匹配。

然后就可以在kibana里添加Index了,如下图所示:

2.Visualize页面的可视化工具能使你用好几种不同的方式展示你数据集的很多方面。
点击Visualize页面开始
3.下一步,我们打算制作一个条形图。点击New Visualization按钮,然后点击Vertical bar chart。选择From a new search,然后选定shakes*模式匹配。你将会看到单个大条形图,因为到现在为止我们还没有定义任何量值。
4.对于Y轴的刻度聚合,选择计量作为Unique
Count的字段。对于X轴的量值,选择Terms聚合和某一字段。对于排序,选择Ascending,Size保持默认值5。让其他参数保持默认值,然后点击Apply
cganges按钮,你的图表应该看起来像下面那样。
5.保存图表的名称为Bar Example。大功告成。
总结
本文完整的记录了配置kibana以及简单使用kibana,需要注意的是kibana端口号5601,使用命令保证该端口不被占用。前后两边文章介绍了ES到kibana的配置和使用。比较详细的记录了整体流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号