RCNN
Scene understanding
- Image classification
- Object detection
- Semantic segmentation
- Instance segmentation
1. Image classification
goals: the task of object classification requires binary labels indication whether objects are present in an image.(对目标是否出现在图片给出判别,yes or no)
2. object detection
goals:detecting an object entails both stating that an object belonging to a specified class is present, and localizing it in the image.The location of an object is typically represented by a bounding box.(对目标属于什么类别进行判断,进行目标的定位)
3. Semantic scene labeling
goals:the task of labeling semantic objects in a scene requires that each pixel of an image be labeled as belonging to a category, such as sky, chair, steet,etc. In contrast to the detection task, individual instances of objects do not need to be segmented.(要求对图片的像素进行分类,是属于天空、街道等等,需要进行目标检测任务,但是不需要进行分割任务)
4. Instance segment
实例分割是物体检测+语义分割的综合体。相对物体检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割可以标注出图上同一物体的不同个体(羊1,羊2,羊3...)
经典目标检测算法
- RCNN
- Fast RCNN
- Faster RCNN
- Mask RCNN
1. RCNN
R-CNN: Region Proposal + CNN + Category-specific Linears SVMs
RCNN算法分为4个步骤
- 一张图生成1k~2K个候选区域
- 对每一个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM分类器,判断属于的类别
- 使用回归器精细修正候选框的位置
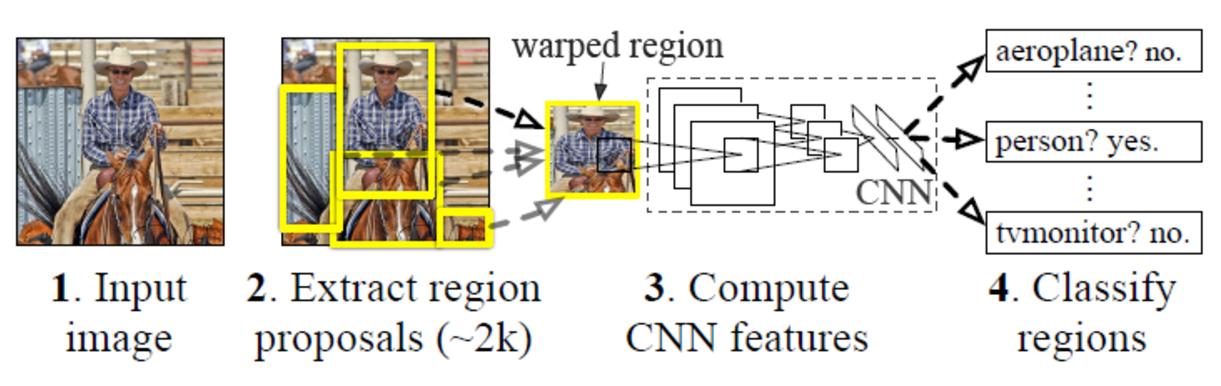
wraped region:包裹的区域
RCNN思想:输入一张图片。提取区域,建议大约2k个区域。然后依次将这些区域送入CNN,进行区域目标区域的分类,和区域框bbox的线性回归。bbox(就是每个区域region矩形框的位置)
论文概要与背景知识整理
backgound
在当时,用 CNN 做 Object Detection 与 Single-label Image Classification 之间的 Gap,或者说这个问题 challenging 的地方一共有两处:
- 一个就是之前没有过用 CNN 做 Object Detection 的工作。不同于 Image Classification,Object Detection 要求 localizing objects within an image. 这个 Location 信息要怎么给出?在当时流行的 CNN架构AlexNet ,只被用来做图像分类任务。
- 另外一个就是,labeled data for detection is scarce. AlexNet 在 Single-label Image Classification 上取得成功,是因为 ImageNet 正好有上千万幅标注好的分类图像,但是对于 Object Detection,当时最大的 VOC dataset 可不足以支撑训练其那么多的神经网络参数。
abstract 摘要
论文成果,在PASCAL VOC数据集上,mAP达到53.3%,相比VOC 2012的结果增加30%。主要有两个关键思想:一是可以将高性能的CNN网络应用于自底而上(从背景到前景)的region proposals,以便进行目标检测和定位;二是当有标签的数据很少时,用监督预训练(supervised pre—training)作为一个辅助任务,然后对特别区域进行微调,可以显著提高模型表现力。
introduction
bbox(bounding box)的定位location 是一个回归问题。
可以选择滑动窗口 to localizing objects within an image.为了保持图像高分辨率,CNN一般只有两层convolution and pooling layers. 在本文中,尝试使用sliding-window approach, 但是随着网络的加深,(5个convolution layers),会有很大的receptive fields(感受野 195 * 195 pixels),strides(32 * 32) in the image。这使得滑动窗口的精确定位变得很困难。
本文为了解决CNN网络的定位问题,采用了“recognition using regions”方法。we use a simple technique(affine image warping) to compute a fixed-size CNN input from each region proposal, regardless of the region's shape.
本文的第二个问题:有标签的数据很少,不足以支持CNN的训练。传统方法是使用无监督的预训练,然后接下来的使用无监督的微调(fine-tuning)。
本文的第二个贡献:在一个大的数据集上进行supervised pre-training, followed by domian special fine-tuning on a small dataset, is an effective paradigm(一个领域主流的理念、方法、行事套路) for learning high-capacity CNNs when data is scarce.
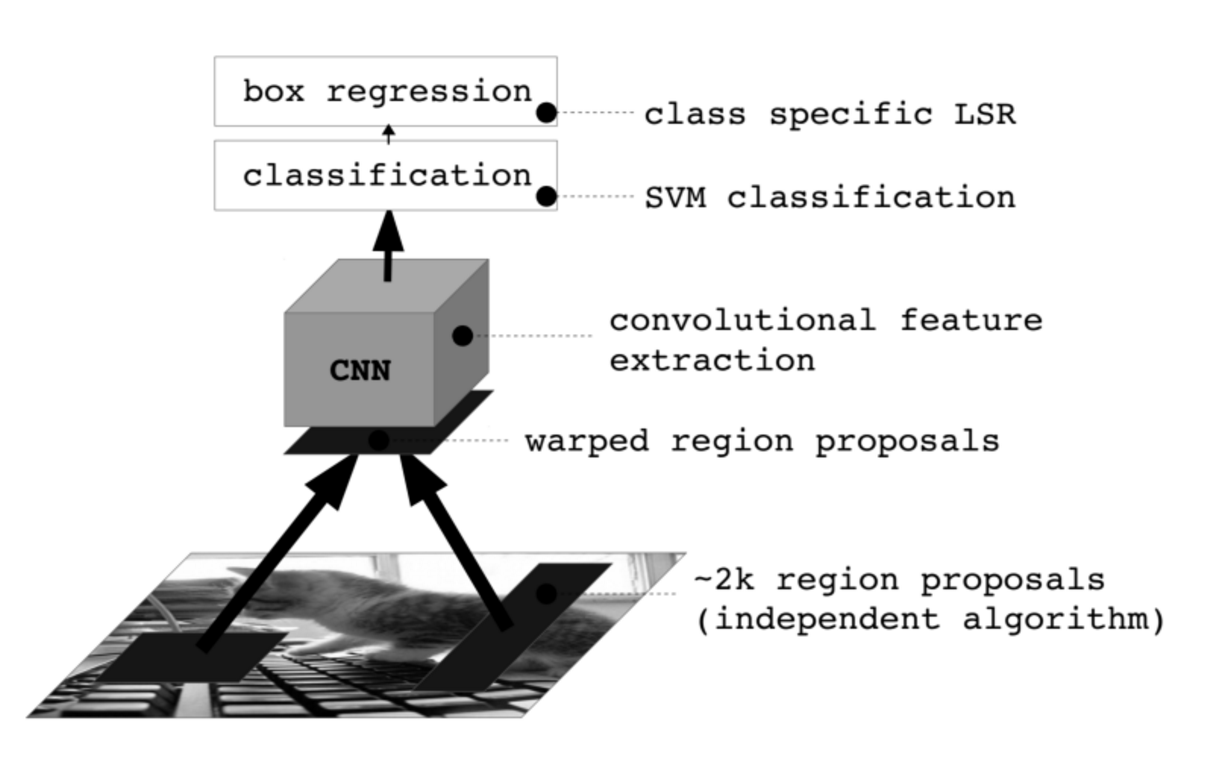
Object detection with R-CNN
目标检测主要有三个模块组成。
第一个生成单一类的目标区域。第二是对于each region,CNN网络提取固定长度(fixed-length)特征向量.第三个是线性分类器SVM.
2.1 模块设计
test-time detection
在测试图片上,提取大约2000 region proposals。wraps each proposal and forward propagate it through the CNN。对于每一类,我们使用SVM进行训练,
all parameters are shared across all categories.在分类中,所有的CNN参数是共享的。也就是说分类任务使用的是同一个CNN网络。
2.2 Model
R-CNN = Region Proposal + CNN + Category-specific Linear SVMs + Non-Maximum Suppression + Bounding Box Regression
- The first generates category-independent region proposals.
- The second module is a large convolutional neural network that extracts a fixed-length feature vector from each region.
- The third module is a set of class-specific linear SVMs.
Module 1:Region Proposal
Region Proposal 用 Selective Search 实现,选这个文章里到没有说是有什么优点采选 SS,而是为了跟其他已有的方法对比,他们用了 SS。所以完全可以用其他 Region Proposal 方法,比如 BING 之类的。
目前我能理解的 detection 的思路其实就是 region classification,确定了哪些 region 里面有什么类的 object 也就完成了 detection,至于怎么产生这些 region,可以用 sliding-window,也可以用 region proposal,其实我觉得 sliding-window 就是一种特别简化的 region proposal 嘛。
Module 2:Feature Extraction
CNN 就是用来抽取特征的,输出是 softmax,但这个只是在训练 CNN fine-tunning 的阶段用,最分类还是用的 SVM.
CNN 对输入的要求是必须都是固定大小的,但是 Region Proposal method 产生的 region 每个都各不相同,怎么把这不规则的 region 输入需要固定大小输入的 CNN,这是怎么解决的呢?Regardless of the size or aspect ratio of the candidate region, we warp all pixels in a tight bounding box around it to the required size.
Module 3: Classification
SVM 用来分类。
Module 4: Non-Maximum Suppression
Given all scored regions in an image, we apply a greedy non-maximum suppression (for each class independently) that rejects a region if it has an intersection-over-union (IoU) overlap with a higher scoring selected region larger than a learned threshold.
去除重复的 Proposal,所以 R-CNN 这里是有大量的冗余计算的,先产生大量的 Proposal,然后最后再剔除掉绝大部分,如果一开始就可以产生少量高质量的 Proposal 就好了,这就是后面改进工作(Faster R-CNN)的 Motivation 了。
Module 5:Bounding Box Regression
Inspired by the bounding box regression employed in DPM [15], we train a linear regression model to predict a new detection window given the pool 5 features for a selective search region proposal.
Conclusion
We achieved this performance through two insights. The first is to apply highh-capacity convolutional neural networks to bottom-up region proposals in order to localize and segment objects.The second is a paredigm for training large CNNs when labeled training data is scarce. We show that it is highly effective to pre-train the network with supervision——for a auxiliary task with abundant data(image classification) and then to fine-tune the network for the target task where data is scarce(detection).
问题一:如何生成候选区域,依据什么规则?
候选区域的生成
使用了Selective Search1方法从一张图像生成约2000-3000个候选区域。Selective Search如下:
- 使用Efficient GraphBased Image Segmentation中的方法来得到region
- 得到所有region之间两两的相似度
- 合并最像的两个region
- 重新计算新合并region与其他region的相似度
- 重复上述过程直到整张图片都聚合成一个大的region
- 使用一种随机的计分方式给每个region打分,按照分数进行ranking,取出top k的子集,就是selective search的结果
相似度的考虑可以结合多种策略
策略多样化(Diversification Strategies)
- 颜色(颜色直方图)相似度
- 纹理(梯度直方图)相似度
- 大小相似度
- 吻合(fit)相似度
- 最后把上述相似度按照不同的权重结合到一起
问题二:候选区域的尺寸不一,如何处理?
答:regardless of the size or aspect ratio of the candidate region, we warp(相当于python中的resize操作) all pixels in a tight bounding box around it to the required size.
问题三:使用的CNN网络模型是什么?
答:对于 pre-training: discriminatively pre-trained the CNN on a large auxiliary dataset (ILSVRC 2012) with image-level annotations,就是 pretrained AlexNet。
问题四:分类和回归任务是分开做的,还是同时进行的?
- 对于 fine-tunning: Domain-specific fine-tuning on VOC
- 这个 VOC 是 VOC Detection,并不是 Classification,
- 注意的是,这里是把 Object Region 和 Background Region 输入 CNN,并不是整张图像,而且每个 Region Proposal 都是被 resize 到 227 × 227 大小,为了符合 AlexNet 对输入的要求(因为 fully-connected layer 的要求)。所以只要把 AlexNet 最后分类的 1000 类改成 VOC 的 21 类就可以了,网络结构不用变,因为 R-CNN 背后的思想是 Object Detection by Region Proposal Classification,所以 Classification Network 可以直接拿来用。
- 构造 Batch 的时候,mini-batch size 是 128,32 个 positive window,从每类里面均匀分布随机采样;96 个 Background window。之所以背景样本比 Object 样本多很多,因为实际情况就是这样的。
对于 Classification: 对于每一个 category,肯定是要构建 positive 和 negative 两类啦
对于完全是 背景 or 完全含有目标的 Proposal,很容易判断是 positive or Negative
对于只包含部分的 Proposal,是算 IOU,阈值是 0.3,这是作者做了网格搜索验证后的结果,后面的研究似乎也都沿用了 0.3 这个值。
问题:在有标签数据很少时,传统方法先unsupervised pre-training, followed by domian-specific fine-tune的概念?
答:无监督的预训练不能帮助我们寻找到更好的初始化权重。
无监督的预训练并不能降低训练集的误差,预先训练的模型比随机初始化的模型产生更低的测试成本。它的优点似乎是更好的泛化,而不仅仅是更好的优化过程。
无参数的预训练会带来类似于正则化的效用,是某种特殊的先验分布带来的正则化(此处甚是懵逼),这种效用会随着模型的复杂性的增大而增大。
问题:为什么要用SVM,直接用softmax分类器不好吗?
suppliment里面提到,用softmax效果降低4个百分点。原因有下:
- the definition of positive examples used in fine-tuning does not emphasize precise localization
- the softmax classifier was trained on randomly sampled negative examples rather than on the subset of “hard negatives” used for SVM training.
非极大抑制(Non-Maximum Suppression)
目标检测中,NMS被用在后期的物体边界框去除。
NMS 对检测得到的全部boxes进行局部的最大搜索,以搜索某邻域范围内的最大值,从而滤出一部分 boxes,提升最终的检测精度。
简而言之,找出score比较region,其中需要考虑不同region的一个重叠问题。
- 输入:检测到的Boxes(同一个物体可能被检测到很多Boxes,每个box均有分类score)
- 输出:最优的box
- 过程:去除冗余的重叠 Boxes,对全部的 Boxes 进行迭代-遍历-消除.
- 将所有框的得分排序,选中最高分及其对应的框;
- 遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,则将框删除;
- 从未处理的框中继续选一个得分最高的,重复上述过程.
假设从一个图像中得到了2000 region proposals,通过在CNN之后我们会得到2000×4096的一个特征矩阵,然后通过N的SVM来判断每一个region属于N的类的scores。其中,SVM的权重矩阵大小为4096×N,最后得到2000*N的一个score矩阵(其中,N为类别的数量)。
Non-Maximum Suppression就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的bounding box。首先,NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中。接下来,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box。然后重复上面的过程,直至候选bounding box为空。最终,检测了bounding box的过程中有两个阈值,一个就是IoU,另一个是在过程之后,从候选的bounding box中剔除score小于阈值的bounding box。需要注意的是:Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N次。
例如:
假设某物体检测到 4 个 Boxes,每个 Box 分别对应一个类别 Score,根据 Score 从小到大排列依次为,(B1, S1), (B2, S2), (B3, S3), (B4, S4). S4 > S3 > S2 > S1.
- Step 1. 根据Score 大小,从 Box B4 框开始;
- Step 2. 分别计算 B1, B2, B3 与 B4 的重叠程度 IoU,判断是否大于预设定的阈值;如果大于设定阈值,则舍弃该 Box;同时标记保留的 Box. 假设 B3 与 B4 的阈值超过设定阈值,则舍弃 B3,标记 B4 为要保留的 Box;
- Step 3. 从剩余的 Boxes 中 B1, B2 中选取 Score 最大的 B2, 然后计算 B2 与 剩余的 B1 的重叠程度 IoU;如果大于设定阈值,同样丢弃该 Box;同时标记保留的 Box.
重复以上过程,直到找到全部的保留 Boxes.
Fine-tuning过程
通过对imageNet上训练出来的模型(如CaffeNet、VGGNet、ResNet)进行微调,然后应用到我们自己的数据集上。因为ImageNet数以百万计带标签的数据,使得VGGnet、ResNet等预训练模型具有具有非常强大的泛化能力。通常我们只需要对预训练模型的后几层进行微调,然后应用到我们的数据上,就能得到很好的结果。
简而言之,通过在预训练模型上进行Fine-tuning,可以使得在目标任务达到很高的performance,而且使用相对少的数据量。
经验:在层数较深的情况下,由于deep learning本身的特性,在越高层形成的特征越抽象,而前面的卷积层则是颜色和边缘这些比较泛化的特征,所以在fine-tuning时,可以将前几层conv层的learning_rate设置为0,而后几层conv层不建议置为0,否则会对performance影响太大。
目前最强大的模型是ResNet,很多视觉任务通过fine-tuning ResNet可以得到很好的performance。
fine-tuning和迁移学习的区别?
举个例子,假设今天老板给你一个新的数据集,让你做一下图片分类,这个数据集是关于Flowers的。问题是,数据集中flower的类别很少,数据集中的数据也不多,你发现从零训练开始训练CNN的效果很差,很容易过拟合。怎么办呢,于是你想到了使用Transfer Learning,用别人已经训练好的Imagenet的模型来做。
做的方法有很多:
- 把Alexnet里卷积层最后一层输出的特征拿出来,然后直接用SVM分类。这是Transfer Learning,因为你用到了Alexnet中已经学到了的“知识”。
- 把Vggnet卷积层最后的输出拿出来,用贝叶斯分类器分类。思想基本同上。
- 甚至你可以把Alexnet、Vggnet的输出拿出来进行组合,自己设计一个分类器分类。这个过程中你不仅用了Alexnet的“知识”,也用了Vggnet的“知识”。
- 最后,你也可以直接使用fine-tune这种方法,在Alexnet的基础上,重新加上全连接层,再去训练网络。
综上,Transfer Learning关心的问题是:什么是“知识”以及如何更好地运用之前得到的“知识”。这可以有很多方法和手段。而fine-tune只是其中的一种手段。
Region Proposal 方法之 Selective Search

如何判断哪些region属于同一个物体?这个问题找不到一个统计的答案。
有些图片可以通过颜色来区分物体,而有些通过纹理区分,还有一些既不是颜色相近,也是不纹理相似。
所以需要结合多种策略,才有可能找打图片中的物体。
Multiscale

在上面两张图片, selective search 展示了不同scale 的必要性。在左边的图片,我们发现目标有不同的scales。在右边的图片,我们必须找到不同的scale,因为女孩包含在tv中。
由于物体之间存在层级关系,所以Selective Search用到了Multiscale的思想。从上图看出,Select Search在不同尺度下能够找到不同的物体。
注意,这里说的不同尺度,不是指通过对原图片进行缩放,或者改变窗口大小的意思,而是,通过分割的方法将图片分成很多个region,并且用合并(grouping)的方法将region聚合成大的region,重复该过程直到整张图片变成一个最大的region。这个过程就能够生成multiscale的region了,而且,也符合了上面“物体之间可能具有层级关系”的假设。
Selective Search方法简介
- 使用Efficient GraphBased Image Segmentation中的方法来得到region
- 得到所有region之间两两的相似度
- 合并最像的两个region
- 重新计算新合并region与其他region的相似度
- 重复上述过程直到整张图片都聚合成一个大的region
- 使用一种随机的计分方式给每个region打分,按照分数进行ranking,取出top k的子集,就是selective search的结果
ps:(efficient GraphBased Image Segmentation)留着后面再看吧,需要补的知识有点多,丧脸!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号