

基于LLM的裁判文书合规化审查——数据标注与整理
一.git_lfs使用
简介
Git LFS 是 Github 开发的一个 Git 的扩展,用于实现 Git 对大文件的支持
1.安装
下载位置,选择相应的版本进行下载
安装时选择合适的位置,一路next
2.使用
Git LFS(Large File Storage)是一个 Git 扩展,用于管理大型文件,如图像、音频、视频等。它可以帮助你有效地管理和版本控制大型文件,而不会使 Git 仓库变得过于庞大。
以下是使用 Git LFS 的基本步骤:
-
安装 Git LFS: 如果你还没有安装 Git LFS,首先需要安装。你可以在 Git LFS 官方网站 上找到适用于你操作系统的安装说明。
-
初始化 Git LFS: 进入到你的 Git 仓库目录,然后运行以下命令来初始化 Git LFS:
git lfs install -
追踪大型文件: 选择你需要使用 Git LFS 管理的大型文件,并使用
git lfs track命令追踪它们。例如,如果你想追踪所有的.mp4文件,你可以运行:git lfs track "*.mp4"这将在
.gitattributes文件中添加一个记录,告诉 Git LFS 要跟踪.mp4文件。 -
将大型文件添加到仓库并提交: 将你的大型文件添加到 Git 仓库,并提交更改。在此过程中,Git LFS 会自动替换大型文件的内容,并将它们存储在 Git LFS 服务器上。
git add . git commit -m "Add large files tracked by Git LFS" -
推送到远程仓库: 推送你的更改到远程仓库。
git push origin masterGit LFS 会自动将大型文件上传到 LFS 服务器,并在提交时将文件指针替换为 LFS 中文件的引用。
-
其他命令: 除了上述的基本命令之外,Git LFS 还提供了其他一些命令,用于查看跟踪的文件、锁定文件以进行编辑等。你可以通过运行
git lfs help命令来查看所有可用的命令和选项。
通过使用 Git LFS,你可以更轻松地管理和版本控制大型文件,而不会影响到 Git 仓库的性能和体积。
二. LLM部署简介
部署大语言模型(LLM)可以分为几个关键步骤,包括环境准备、模型加载和优化、API接口设置、安全和高可用性保障、以及持续监控和管理。以下是详细的步骤指南:
1. 准备环境
硬件选择
- 云服务:选择适合运行高性能计算实例的云平台,如 AWS、Google Cloud、Azure 等。
- 本地服务器:如果有条件,可以选择高性能本地服务器,确保有足够的 GPU 资源。
软件环境
- 操作系统:通常使用 Linux(如 Ubuntu)。(Linux的安装相对简便)
- Python 和包管理工具:确保安装了 Python 以及
pip或conda。
2. 安装必要的软件
安装深度学习框架
选择 PyTorch 或 TensorFlow:
pip install torch torchvision torchaudio # PyTorch
# OR
pip install tensorflow # TensorFlow
安装 Hugging Face Transformers 库
Hugging Face Transformers 是一个广泛使用的模型库:
pip install transformers
3. 加载和优化模型
加载预训练模型
使用 Hugging Face Transformers 库加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt-3.5-turbo" # 替换为你使用的模型名称
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
优化模型
考虑使用混合精度训练、模型裁剪等技术优化模型性能:
from transformers import pipeline
generator = pipeline('text-generation', model=model, tokenizer=tokenizer)
4. 设置API接口
使用 Flask 或 FastAPI
创建一个简单的 REST API 来与模型交互:
from fastapi import FastAPI, Request
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
text: str
@app.post("/generate/")
async def generate_text(item: Item):
inputs = tokenizer(item.text, return_tensors="pt")
outputs = model.generate(inputs.input_ids, max_length=50)
return {"generated_text": tokenizer.decode(outputs[0], skip_special_tokens=True)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
5. 确保安全和高可用性
安全措施
- 身份验证和授权:实现 API 密钥、OAuth 等机制。
- HTTPS:使用 SSL/TLS 证书确保通信安全。
高可用性
- 负载均衡:在云平台上使用负载均衡器分配流量。
- 自动扩展:根据流量自动调整实例数量。
6. 部署和监控
使用 Docker 容器化
使用 Dockerfile 创建 Docker 镜像:
FROM python:3.8
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
CI/CD 自动化部署
使用 GitHub Actions、GitLab CI 等工具自动化部署流程。
监控和日志
- 监控工具:使用 Prometheus 和 Grafana 监控系统性能。
- 日志系统:配置集中式日志系统(如 ELK stack)。
示例代码
以下是一个完整的 FastAPI 示例代码:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import AutoModelForCausalLM, AutoTokenizer
app = FastAPI()
model_name = "gpt-3.5-turbo"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
class Item(BaseModel):
text: str
@app.post("/generate/")
async def generate_text(item: Item):
inputs = tokenizer(item.text, return_tensors="pt")
outputs = model.generate(inputs.input_ids, max_length=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"generated_text": generated_text}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
通过这些步骤,你可以成功地部署一个大语言模型,确保其在生产环境中稳定、高效地运行。根据具体需求,可以进一步优化和扩展这些步骤。
7.LLM文件架构
大型语言模型(LLM)在分发和部署时,通常包含多个文件和资源,以确保模型能够正常运行并达到预期的效果。以下是LLM常见的文件和资源:
-
模型文件:
- 这些文件包含了预训练和微调后的模型权重。
- 通常是二进制文件,文件扩展名可能是
.bin、.pt(用于PyTorch)或.h5(用于TensorFlow)。 - 例如,
pytorch_model.bin是Hugging Face Transformers库中常见的模型文件名。
-
配置文件:
- 配置文件包含模型的架构信息,如层数、隐藏单元数、自注意力头数等。
- 这些信息通常存储在一个 JSON 文件中,文件名如
config.json。 - 配置文件确保加载模型时能够正确构建其架构。
-
词汇表文件:
- 词汇表文件包含模型使用的词汇表,用于将文本输入转换为模型可以处理的数字表示。
- 常见的词汇表文件名为
vocab.txt、merges.txt或vocab.json,取决于模型的分词方式(如BERT、GPT-2、BPE等)。
-
分词器文件:
- 分词器文件定义了如何将输入文本分割成模型可以处理的单词或子词。
- 这包括词汇表和其他必要的信息,通常以
tokenizer.json或tokenizer_config.json形式存在。
-
特殊标记文件:
- 包含特殊标记(如
[CLS]、[SEP]、[PAD])的信息。 - 通常与词汇表文件一起存储。
- 包含特殊标记(如
-
训练超参数文件:
- 包含微调过程中使用的超参数,如学习率、批量大小、训练轮次等。
- 通常存储在 JSON 文件中,如
training_args.json。
-
README或使用说明:
- 文档文件,提供模型的基本信息、使用指南、引用信息等。
- 通常是一个
README.md文件。
示例:BERT模型文件结构
以下是一个预训练BERT模型文件结构的示例:
bert_model_directory/
│
├── config.json # 模型配置文件
├── pytorch_model.bin # 预训练模型权重文件
├── vocab.txt # 词汇表文件
├── tokenizer_config.json # 分词器配置文件
├── special_tokens_map.json # 特殊标记文件
├── README.md # 使用说明文件
示例:Hugging Face Transformers 加载预训练模型
使用 Hugging Face Transformers 库加载预训练模型和相关文件的示例:
from transformers import BertTokenizer, BertModel
# 指定模型路径
model_path = "path/to/bert_model_directory"
# 加载分词器和模型
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
# 使用模型进行推理
input_text = "Hello, world!"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model(**inputs)
print(outputs)
文件说明
config.json:定义模型架构,包括层数、隐藏层大小、自注意力头数等。pytorch_model.bin:包含模型的预训练权重。vocab.txt:包含模型的词汇表,用于将输入文本转换为模型可以理解的数字表示。tokenizer_config.json:定义分词器的配置和特殊标记信息。special_tokens_map.json:列出分词器使用的特殊标记及其对应的词汇表索引。README.md:提供模型的基本信息和使用指南。
通过包含这些文件,LLM能够被正确加载和使用,确保其在不同任务和应用场景下的表现。
8.文件简介
当然,我会解释每个 Python 文件的作用:
api_test.py:用于测试 API 接口的文件,包含了对项目中提供的 API 进行测试的代码。api_demo.py:可能是一个演示或示例文件,用于展示项目中的 API 如何使用的示例代码。cli_wo_history.py:包含命令行界面 (CLI) 的代码,用于在没有历史记录的情况下与用户交互。export_model.py:用于导出模型的文件,包含了将训练完成的模型导出为可用于推理或部署的格式的代码。train_ppo.py:包含了使用 PPO (Proximal Policy Optimization) 算法进行训练的代码,可能用于强化学习等任务。train_pt.py:包含了使用 PyTorch 进行训练的代码,可能是针对 PyTorch 框架的训练脚本。train_rm.py:包含了使用 RM (Risk Minimization) 算法进行训练的代码,可能用于风险敏感的模型训练。train_sft.py:包含了使用 SFT (Softmax Temporature) 算法进行训练的代码,可能用于模型的温度调节和训练。web_demo.py:可能是一个包含 Web 演示的文件,用于在 Web 界面上展示项目功能的代码。
接下来是 utils 文件夹中的文件:
check.py:包含了一些检查函数,用于验证数据或其他输入的有效性。common.py:包含了一些通用的函数或类,可能被项目中的其他模块或文件频繁使用。config.py:包含了配置信息,可能用于管理项目的配置参数。data_collator.py:可能是一个数据收集器,用于在训练过程中对数据进行处理和准备。other.py:包含了一些其他的辅助函数或类,可能没有明确的归类。pairwise.py:可能是一个用于处理成对数据的文件,例如计算成对数据之间的相似度或差异度。peft_trainer.py:可能是一个用于训练 PEFT (Policy and Environment Focused Training) 的文件,用于强化学习相关的训练。ppo.py:可能是一个包含 PPO (Proximal Policy Optimization) 相关代码的文件,用于强化学习任务的训练。seq2seq.py:可能是一个包含序列到序列 (seq2seq) 模型相关代码的文件,用于序列生成或翻译等任务。template.py:可能是一个模板文件,用于创建新的功能模块或文件时作为参考或基础。__init__.py:用于将该文件夹标记为 Python 包的初始化文件。
三. 数据提取与标注
在对模型进行训练之前我们要尽可能的完成数据标注的任务。
首先要建立合适的标注体系:我们将带结构的实体信息抽取过程转化为了实体关系联合抽取任务,并根据实际需要指定了单种实体多种关系的标注,使其符合CasRel的使用范围,并简化的关系体系,使用软件doccano进行了标注。
标注结果如下:
![img]()
![点击并拖拽以移动]() 编辑doccano的安装以及使用
编辑doccano的安装以及使用
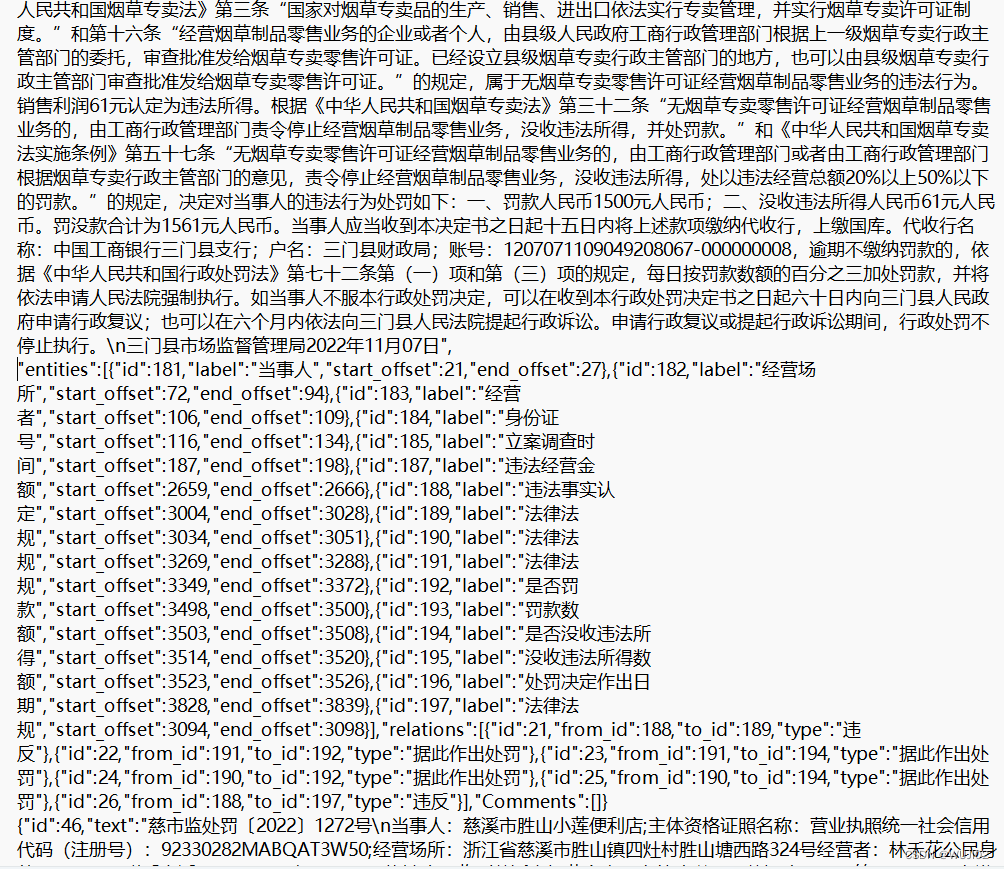
 编辑doccano的安装以及使用
编辑doccano的安装以及使用Doccano 是一个开源的文本标注工具,可以帮助你进行各种文本分类、序列标注和实体识别任务。以下是安装 Doccano 的步骤:
一. 使用 pip 安装
-
创建虚拟环境(可选,但推荐):
python -m venv venv source venv/bin/activate # 如果你使用的是 Windows,则运行 venv\Scripts\activate -
安装 Doccano:
pip install doccano -
初始化数据库:
doccano init -
创建超级用户:
doccano createuser --username admin --password password --email admin@example.com -
运行 Doccano:
doccano webserver --port 8000 -
访问 Doccano:在浏览器中打开
http://localhost:8000以访问 Doccano。
额外配置
根据你的需求,你可以进一步配置 Doccano,例如设置数据库、配置 HTTPS 等。详细的配置选项和高级设置可以参考 Doccano 的官方文档和 GitHub 仓库的 README 文件。
如果在安装或使用过程中遇到任何问题,可以参考 Doccano 的 GitHub 问题页面或社区讨论来寻求帮助。
二. 使用doccano
安装完 Doccano 之后,具体的使用步骤如下:
1. 登录 Doccano
- 打开浏览器,访问
http://localhost(如果使用 Docker 安装)或http://localhost:8000(如果使用 pip 安装)。 - 使用你在创建超级用户时设置的用户名和密码登录。
2. 创建项目
- 登录后,你会看到一个欢迎页面。点击右上角的 "Create Project" 按钮。
- 填写项目名称和描述,并选择项目类型(文本分类、序列标注、实体识别等)。
- 点击 "Create" 按钮创建项目。
3. 导入数据
- 进入你刚创建的项目。
- 点击页面左侧的 "Upload Data" 按钮。
- 选择要导入的文件。Doccano 支持多种文件格式,如 CSV、JSON 等。
- 点击 "Upload" 按钮导入数据。
4. 开始标注
-
数据导入完成后,点击左侧的 "Examples" 菜单。
-
你会看到数据列表。点击任意一条数据进入标注页面。
-
根据项目类型进行标注:
- 文本分类:选择一个或多个类别。
- 序列标注:选择文本片段并分配标签。
- 实体识别:标记实体并分配标签。 -
完成标注后,点击 "Save" 按钮保存。
5. 管理标签
- 在项目页面,点击左侧的 "Label" 菜单。
- 你可以在这里创建、编辑或删除标签。
- 点击 "Create Label" 按钮,输入标签名称和颜色,点击 "Save" 按钮保存。
6. 导出数据
- 当你完成标注任务后,可以将标注的数据导出。
- 在项目页面,点击左侧的 "Export Data" 按钮。
- 选择导出的文件格式,然后点击 "Export" 按钮。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号