爬取网易云音乐评论并使用词云展示
最近听到一首很喜欢的歌,许薇的《我以为》,评论也很有趣,遂有想爬取该歌曲下的所有评论并用词云工具展示。
我们使用chrome开发者工具,发现歌曲的评论都隐藏在以 R_SO_4 开头的 XHR 文件中
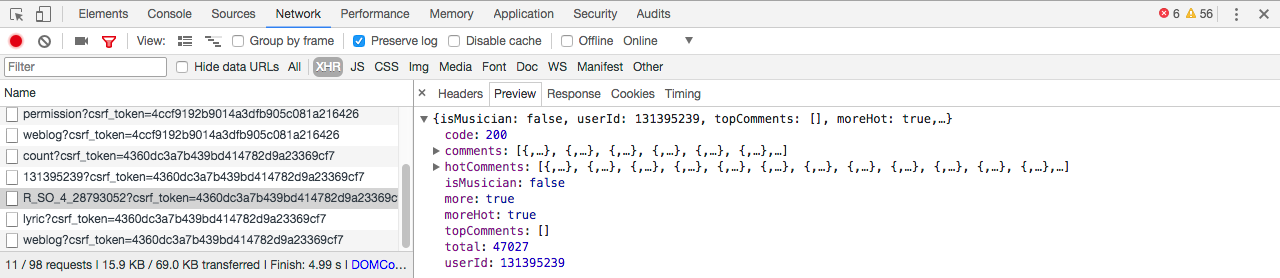
接下来思路就很明确,拿到该文件,解析该文件的 json 数据,拿到全部评论。
我们可以看到该文件有两个用JS加密的参数 params 和 encSecKey ,关于这两个加密参数,参考了知乎用户的解答:https://www.zhihu.com/question/36081767 。

步骤:
1.导入必要的模块:
from Crypto.Cipher import AES
from wordcloud import WordCloud
#需加入下面两句话,不然会报错:matplotlib: RuntimeError: Python is not installed as a framework
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import base64
import requests
import json
import codecs
import time
import jieba
注:本人使用MacOS,在该环境下会报错,加入:
import matplotlib
matplotlib.use('TkAgg')
2.写入请求头:
headers = {
'Host':'music.163.com',
'Origin':'https://music.163.com',
'Referer':'https://music.163.com/song?id=28793052',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
3.解析 params 和 encSecKey 这两个参数:
# 第一个参数
# first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
# 第二个参数
second_param = "010001"
# 第三个参数
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数
forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数
def get_params(page): # page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
encrypt_text = str(encrypt_text, encoding="utf-8") #注意一定要加上这一句,没有这一句则出现错误
return encrypt_text
4.获取 json 数据并抓取评论:
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data)
return response.content
# 抓取某一首歌的评论
def get_all_comments(url,page):
all_comments_list = [] # 存放所有评论
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
for item in json_dict['comments']:
comment = item['content'] # 评论内容
comment_info = str(comment)
all_comments_list.append(comment_info)
print('第%d页抓取完毕!' % (i+1))
#time.sleep(random.choice(range(1,3))) #爬取过快的话,设置休眠时间,跑慢点,减轻服务器负担
return all_comments_list
5.使用结巴分词过滤停用词并用 wordcloud 生成词云:
#生成词云
def wordcloud(all_comments):
# 对句子进行分词,加载停用词
# 打开和保存文件时记得加encoding='utf-8'编码,不然会报错。
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip(), cut_all=False) # 精确模式
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()] # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
for line in all_comments:
line_seg = seg_sentence(line) # 这里的返回值是字符串
with open('outputs.txt', 'a', encoding='utf-8') as f:
f.write(line_seg + '\n')
data = open('outputs.txt', 'r', encoding='utf-8').read()
my_wordcloud = WordCloud(
background_color='white', #设置背景颜色
max_words=200, #设置最大实现的字数
font_path=r'SimHei.ttf', #设置字体格式,如不设置显示不了中文
).generate(data)
plt.figure()
plt.imshow(my_wordcloud)
plt.axis('off')
plt.show() # 展示词云
注意编码格式为 'utf-8' 。
6.定义主函数并设置函数出口:
def main():
start_time = time.time() # 开始时间
url = "https://music.163.com/weapi/v1/resource/comments/R_SO_4_28793052?csrf_token=" # 替换为你想下载的歌曲R_SO的链接
all_comments = get_all_comments(url, page=2000) # 需要爬取的页面数
wordcloud(all_comments)
end_time = time.time() # 结束时间
print('程序耗时%f秒.' % (end_time - start_time))
if __name__ == '__main__':
main()
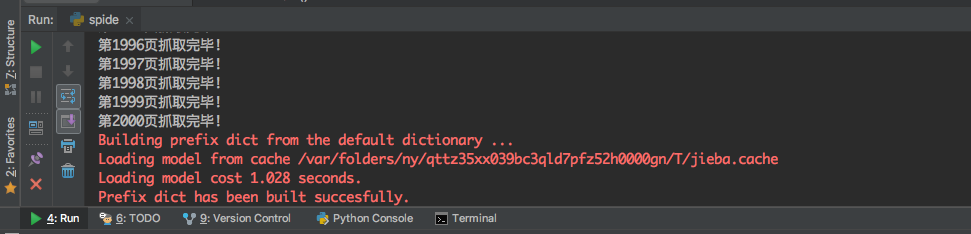
运行过程如下(个人爬取了《我以为》的前2000页的评论):
生成词云:

完整代码已上传至 github:https://github.com/weixuqin/PythonProjects/tree/master/wangyiyun

 浙公网安备 33010602011771号
浙公网安备 33010602011771号