
百度面试-网页搜索部
今天参加了百度的面试,面试过程安排过程中出了些问题,上午面试完成后竟然要等到下午4点安排接下来的面试,安排的不是很紧凑,最好让每个面试者的连续面试安排在一起,面试挺消耗精力了。不过周五赶上百度的summer party,在大厅等待的时候看到很多美女-_-!百度的前台妹纸们真是很漂亮嘛。
一面:面试官很清瘦,个头很高。后来发现人很nice,很随和~,至少面试过程中让人感觉很舒服。一些我回答出来的问题可能记忆的不是很清楚了,主要记录一些我答的不是很好的问题。首先自我介绍,不过刚刚开始就被打断开始进行询问了,从课程至项目,聊了很多,面试官在百度的职位or他隶属于的部门属于百度的框架开发类职位,及相对于策略类的一个职位。无论我的课程或者经历其实对于框架开发类职位比较不足,比较偏策略一些。不过继续面试嘛,我兴趣广泛,针对这个也很感兴趣的~
1.linux多线程编程的知识,这个答的不是很好,因为自己确实基本没写过多线程的知识,只是并行程序设计利用MPI实现过简单的算法,概念知识不是很了解,所以针对linux多线程编程知识还需要补充一下。当时一个问题就是锁的类型?
2.linux中文件描述符FD的概念?当时想不到是什么,然后面试官提示了一下,0,1,2,就想到了命令行中经常用到1,2就答了一下才了解到平时用到的这些就是文件描述符,自己却不知道概念。
标准输入(standard input)的文件描述符是 0,标准输出(standard output)是 1,标准错误(standard error)是 2。
3.因为是搜索公司,所以面试官让我描述一下整个搜索引擎的过程,包括用户提交query之后的一系列工作,这部分概念缺失很多,答的很差。准备面试一家搜索公司,而且在搜索公司实习过一段时间,竟然无法完整答出这个问题,其实挺糟的。
这个搜索一下比较好的架构~最好针对已经有的开源项目分析其框架最好。针对我可能分析一下Nutch和Solr比较好。
4.针对数组A和数组B,两个数组的元素内容相同,不过数组A是已经排序的,数组B是乱序的,针对数组的中位数,存在以下两组程序,比较其效率并分析原因。
int g;
int main() {
g = 0;
for(int i = 0 ; i < n ; i++) {
if( A[i] > mid )
g++;
}
for(int i = 0 ; i < n ; i++) {
if(B[i] > mid )
g++;
}
}
这个题目之前在网上浏览到过,知道有序的数组的效率其实比无序的要高很多,但是原因实在想不出来。现在搜一下,原来是stackoverflow上面的经典问答呢,原因不是编译器动手脚,而是CPU动的手脚,CPU有一个叫分支预测的技术,是这个技术导致有序数组的效率很高。 CPU指令执行的过程是流水线,简单的分支预测方案是针对当前元素判断下一个元素的指令跳转方向,有序的话分支预测的准确率很高,无序的话分支预测技术就不生效了,无法提前装载指令进入流水线,这样就损耗了一定的CPU时间。
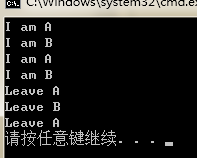
5.虚拟析构函数的应用场景。
当时答的是指向父类的指针实际指的子类对象,delete的时候需要调用子类析构函数!这是唯一应用场景!当时多嘴答了一下引用也可。其实引用必须显示创建对象,这样编译器就会自动调用其析构函数,所以不属于这一应用场景,即使指针和引用均可完成多态。
实验实例:
class A{
public:
A() {
cout<<"I am A"<<endl;
}
~A() {
cout<<"Leave A"<<endl;
}
};
class B:public A{
public:
B() {
cout<<"I am B"<<endl;
}
~B() {
cout<<"Leave B"<<endl;
}
};
int main() {
A &atestr = B();
A *atestp = new B();
delete atestp;
}
实验结果:
6.STL中list的底层实现?双链表,因为可以前进后退。STL中的deque的默认使用容器?其实当时不太确定,思考了一下,猜了一下vector,因为很多容器默认容器均使用vector。当时如果问我deque的底层实现就好了,这个我更加了解-_-。
7.vector的insert和erase操作,这个也不是很熟悉,但是属于连续空间的插入和删除,必须做内存的调整~,翻看一下STL源码具体的实现。
8.两个简单的算法题目,时间比较急,代码写的比较冗余。
a.一个数组中只有一个数字出现1次,其他数字出现两次。
挺简单的题目,因为见过,所以就跳过了这个题目,所以元素异或即可。
b.一个m*n得棋盘,每个格子中有一个数字,计算从左上角至右下角的最大路径和,每一步行只能够向右或者向下行走。
一个简单的动态规划题目,第一种方法首先时间复杂度O(mn)空间复杂度O(mn)的写了代码,代码有些长,后来改进了一个时间复杂度O(mn)空间复杂度O(min(m,n))的算法,后来面试官问如果需要还原路径如何做?采用O(mn)的额外空间记录每个单元走的路径即可。
面试总结:算法题目其实挺简单的,只不过很多基础知识不够牢固,比如linux的一些基础知识(复习下《鸟哥linux私房菜》),多线程的编程知识(学习下《posix多线程程序设计》并简单实践一下),STL的知识和C++的知识也仍然需要巩固复习(STL源码剖析,Effective C++,More Effective C++,深度探索C++对象模型一本书内容还是挺晦涩的,还是要拜读一下,面试的时候虽然可能不涉及这么深入的知识,但是还是要继续学习),另外就是尽可能的逛一些技术社区,看一些东西了。因为像有序,无序数组那个题目,感觉完全是技术视野的问题,看到了就会,没看到怎么能够想到是CPU的优化,我都以为是编译器的优化,答题方向都掌握错了。
二面:二面的面试官相对于一面的面试官不是那么的健谈,更多的是让我去说,他去加一些提醒,然后我继续的回答。不过面试官也很nice,因为答题的过程当中给了我很多的引导,因为题目我答的都不是很完善T_T!
1.首先是问一个大数据处理的题目,两个URL文件,分别有20亿条记录,每个URL的项目大约1KB。文件中有重复的URL记录,如何去除重复?
因为在一面的过程中了解到,有序的数组去除重复的时候能够得到快速的去重,所以就考虑到了首先排序,但是两个这么大的文件单机排序?外部排序,k路归并排序,然后面试官就顺势的问了我k路归并排序的知识,k路归并排序的时间估计,因为k路归并排序很多时间在磁盘的IO上面,所以我猜测可能磁盘的IO才是时间的平静,每个元素最终进出磁盘4次,所以我估计的方法是元素数量*4*磁盘IO平均时间。不知道这个方法对不对。
多机的扩展,MapReduce程序应该可以完成,但是我对hadoop不是很了解(所以这个方法没有答)。自己想一下多机的扩展吧,当然也是分治,想想也可以多机k路归并排序,后来面试官引导我说可以不排序么?我才意识到原始问题只是为了去除重复,所以这里分治并且利用hash的方法应该能够达到很快速的算法(复习一下《大型网站架构》这本书)一致性simhash方法应该是解决这个问题的。
2.设计模式,单例设计模式的深入讨论。(复习《head first》设计模式)
a.单例设计模式的应用场景?
b.单例模式的代码(白纸代码)?
c.多线程安全的单例模式代码(需要加锁)?
d.如何实现一个高效的线程安全的单例模式代码?(存在不加锁的解决方案吗?)
3.简单的聊了项目之后就问了一个算法题目。中国象棋中帅,将和一个将身边的士,输出其合理位置的方案。
刚看到这个算法题目的时候还卡了一下,不过后来自己把棋盘编号为1,2,3,4,5,6,7,8,9之后豁然开朗~不过我的代码if,else比较多,3类情况枚举,后来在面试官的提示下进行条件合并,节省了很多的代码。
for(int s = 1 ; s <= 9;s++) {
for(int j = 1 ; j <= 9;j++) {
for(int jsb = 1; jsb <= 9;jsb += 2) {
if( validposition(s,j,jsb))
printf("%d,%d,%d",s,j,jsb);
}
}
}
bool validposition(int s,int j,int jsb) {
//将和帅相对应,并且不是士兵挡在将的前面的情况???
if ( s%3 == j%3 && !( jsb % 3 == j % 3 && jsb < j ) )
return false;
return true;
}
面试总结:对于系统设计海量数据的题目还是要准备的,还是需要复习《大型网站架构》一书,书中讲述了很多海量数据处理的知识。学习下july的博客,了解一些常用的方法。另外就是设计模式中单例模式的掌握一定要非常的熟悉,不要让面试官不断的提醒修正错误,这样会引出更多的问题,我这次面试就是,虽然及时的修正问题,但是都能够引出其他的问题,比如讲一下线程和进程?虽然这个问题比较普通,但是这种引出其他问题还是尽量避免。
三面:这一面真是等了一个下午,12:30-4:20这个过程真是等待的很漫长,脑袋都秀逗了,面试官下午来了之后感觉就是聊天了,也没有针对我问一些技术问题,主要问了实习的一些工作,简单的聊了半个小时就结束了,也没有说后续的消息。不知道是不是还有后续,反正面试官还是很详细的描述了一下百度的情况,也很认真的解答了我问的几个关于百度的问题。当时也不好意思去问后续消息,就回来了。T_T。
等待吧,希望无论结果好坏,百度都会给一个答复,这样也是一种提高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号